Uber从Postgres迁移到MySQL的原因:降低资源占用,提升效率
140 浏览量
更新于2024-08-30
收藏 328KB PDF 举报
本文探讨了Uber从PostgreSQL(Postgres)迁移到MySQL背后的原因,主要是为了减少带宽占用、降低内存消耗并提高操作效率。Uber的早期架构基于Python和Postgres,但随着业务发展转向微服务和新的数据平台,他们发现Postgres存在一些局限性,包括写入架构低效、数据复制问题、表损坏、从库MVCC支持不佳以及新版本更新困难。文章进一步分析了Postgres的磁盘数据格式,强调了其固定行(元组)设计和ctid在MVCC中的作用,并与MySQL的InnoDB存储引擎进行了对比。
Postgres的局限性分析:
1. **写入架构低效**:Postgres的写入操作可能不如MySQL的InnoDB高效,因为Postgres的行数据是固定的,这可能导致不必要的空间浪费和更复杂的更新操作。
2. **数据复制低效**:在分布式系统中,数据复制的效率至关重要。Postgres在数据复制方面可能存在不足,影响了整体性能。
3. **表损坏的问题**:Postgres的行数据固定可能导致在处理大量更新和删除操作时出现表损坏的风险,这需要额外的维护工作。
4. **糟糕的从库MVCC支持**:多版本并发控制(MVCC)是数据库并发处理的关键,但Postgres在从库上的MVCC支持可能不理想,影响了读写性能。
5. **新版本更新难度升级**:Postgres的新版本升级可能涉及更多的复杂性和风险,这可能影响到系统的稳定性和运维效率。
MySQL的InnoDB存储引擎优势:
MySQL的InnoDB存储引擎提供了更好的性能优化,尤其是在处理大量并发事务时。它采用了可变长度的行格式,减少了空间占用,并且在MVCC支持上更为出色。InnoDB还支持行级锁定,减少了锁定冲突,提高了并发性能。此外,InnoDB的InnoDB Cluster功能提供了内置的数据复制,简化了分布式环境下的数据一致性管理。
Schemaless的引入:
Uber采用Schemaless,这是一个基于MySQL的数据库分片解决方案,旨在解决Postgres的局限性。Schemaless允许更灵活的数据模型,可以更好地适应微服务架构的动态变化。通过分片,Uber能够分散负载,减少单点压力,提高整体性能。
总结:
Uber从Postgres迁移到MySQL,并构建基于MySQL的Schemaless,是为了应对随着业务规模扩大带来的挑战。Postgres的特定设计在面对大规模并发和分布式环境时显得力不从心,而MySQL的InnoDB存储引擎和Schemaless的灵活性、高效性和可扩展性更能满足Uber的需求。这种迁移不仅减少了带宽和内存的消耗,也提升了操作效率,确保了服务的稳定性和高性能。
Uber为什么从为什么从Postgres迁移到迁移到MySQL,减少频宽占用、内存,减少频宽占用、内存
占用,提高操作效率占用,提高操作效率
导论
Uber的早期架构由一个单体后端应用程序构成,该应用由Python编写,Python使用Postgres以实现数据持久化。自那时
起,Uber架构已发生巨变,逐步转化为微服务模式和新的数据平台。特别是在之前一些使用Postgres的案例中,现在则改用
Schemaless(一个基于MySQL的全新数据库分片)。本文将探索Postgres的缺陷,解释迁移到MySQL的基础上构建
Schemaless和其它后端服务的原因。
Postgres的架构
Postgres有很多局限性:
写入架构低效
数据复制低效
表损坏的问题
糟糕的从库MVCC支持
新版本更新难度升级
下文将分析Postgres的表表示法和磁盘上的索引数据,重点对比MySQL通过其InnoDB存储引擎呈现相同数据的方法,以探索
上述缺陷。注意:本文涉及的分析主要基于旧版Postgres 9.2系列。 众所周知,本文论述的内部架构在新发布的Postgres中没
有太大变更。事实上,至少自Postgres 8.3的发布开始(距今近十年),Postgres 9.2中磁盘上表示法的基础设计就一直没有
做出显著调整。
磁盘上的数据格式
关系数据库必须执行下列关键任务:
支持插入/更新/删除功能
支持schema变更功能
实现一个多版本并发控制(MVCC)机制,促使不同的连接对其所处理的数据生成一致性的事务视图
思考其所有特性如何协同运作是设计数据库在磁盘上呈现数据的基础。
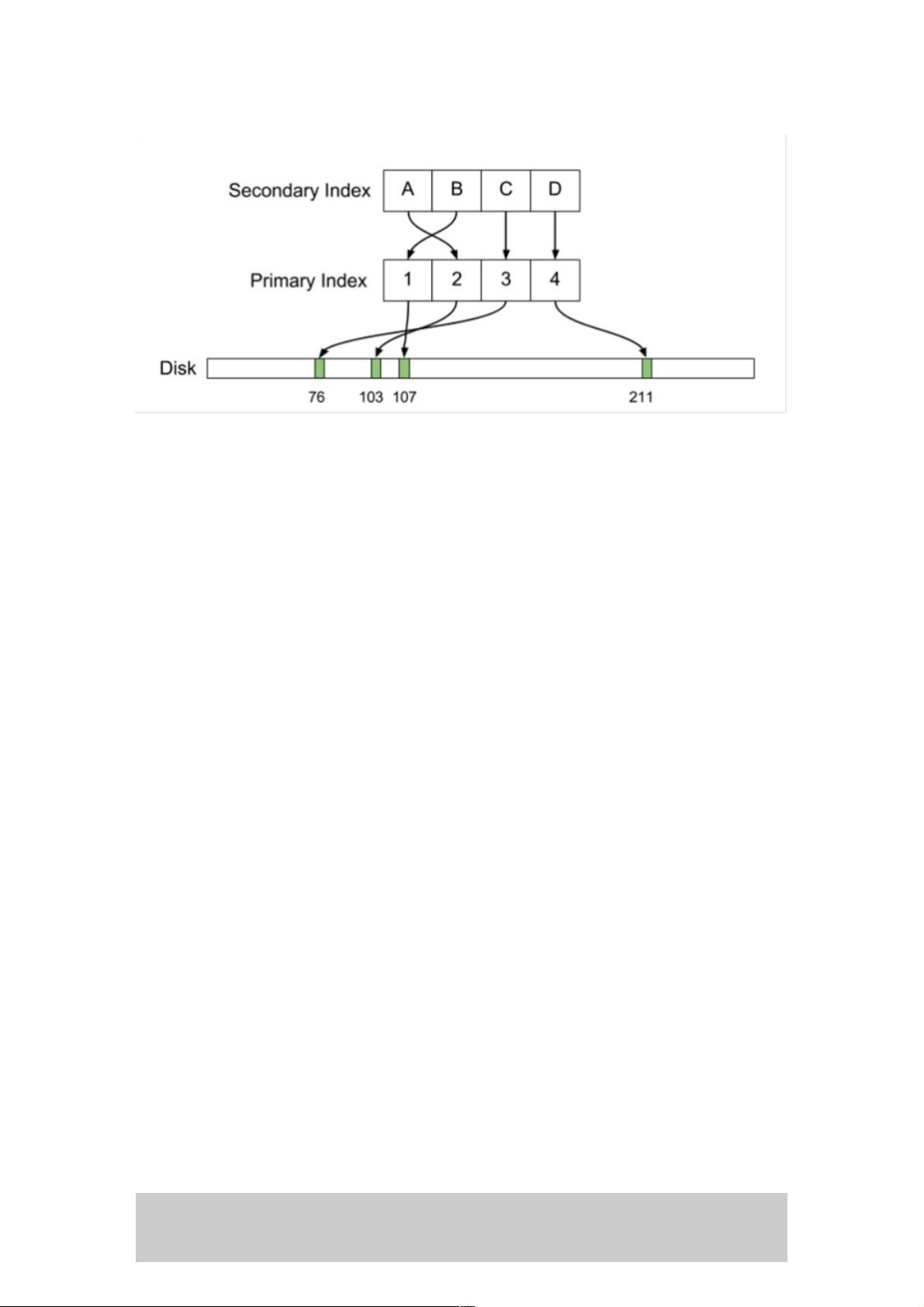
Postgres的一项核心设计是行数据固定。该固定行在Postgres用语中又名“元组(tuple)”。在Postgres中,元组又通过ctid获
得唯一标识。从概念上讲,ctid代表元组在磁盘上的位置(例如物理磁盘偏移)。多个ctid可能能够描述一个单行(例如多个
行版本为了MVCC的目的而存在时,或是旧版本行未经autovacuum进程回收时)。一组元组的组织集合构成表,表本身包含
索引,索引经组合构成数据结构(通常是B-tree结构),从而将索引字段映射到ctid的有效载荷。
通常情况下,这些ctid是面向用户透明的,但了解其运行方式有助于理解Postgres表在磁盘上的表架构。若要查看行的当前
ctid,则可向WHERE子句中的栏目列表中添加“ctid”:
下载后可阅读完整内容,剩余7页未读,立即下载
2021-01-29 上传
2021-10-13 上传
点击了解资源详情
2021-03-18 上传
2021-04-01 上传
2021-05-03 上传
2021-01-19 上传
2021-02-17 上传
2021-03-26 上传

weixin_38692122
- 粉丝: 13
- 资源: 959
 我的内容管理
展开
我的内容管理
展开







最新资源
- casa-inteligente
- esp:esp咨询开发人员
- Accuinsight-1.0.23-py2.py3-none-any.whl.zip
- 径向基函数 (RBF) 教程 - 作为函数逼近器的神经网络:关于径向基函数 (RBF) 的西班牙语教程,仅供学术和教育使用-matlab开发
- neighbors:le Wagon编码训练营的最终项目,批次531
- DP-060JA-Migrating-your-Database-to-Cosmos-DB
- 九九乘法口诀表(word打印版).rar
- AdsAuth
- athena_health:雅典娜健康宝石的叉子
- Digimon Database 数码兽数据库-数据集
- 西门子200发脉冲控制步进电机程序.rar
- monitor-bot:通过官方手柄跟踪网站的变化和新推文
- tap-console-parser:通过劫持 console.log 解析 TAP
- Login-page:登录页面以及链接到postgres的数据库
- TomKingDAO-猫王DAO框架
- Projeto-Site-de-Noticias-Cidade:城市新闻网站的设计
