"本文将详述如何配置Hadoop v1.0集群,包括搭建一个由一个Master节点和两个Slave节点组成的3节点集群,并通过执行WordCount示例来验证配置的成功。我们将涵盖安装Xshell和Vmware9.0.2作为辅助工具,以及安装CentOS-6.4操作系统、拷贝必要文件、配置Java环境等关键步骤。"
在配置Hadoop集群之前,首先需要准备合适的工具。Xshell是一款强大的终端模拟器,用于在Linux环境下更方便地管理配置文件。虽然不是必需的,但它的使用可以简化操作。同样,虽然Vmware9.0.2不是必须的,但它可以帮助在虚拟环境中顺利安装CentOS-6.4,特别是当原有的Vmware版本不兼容时。
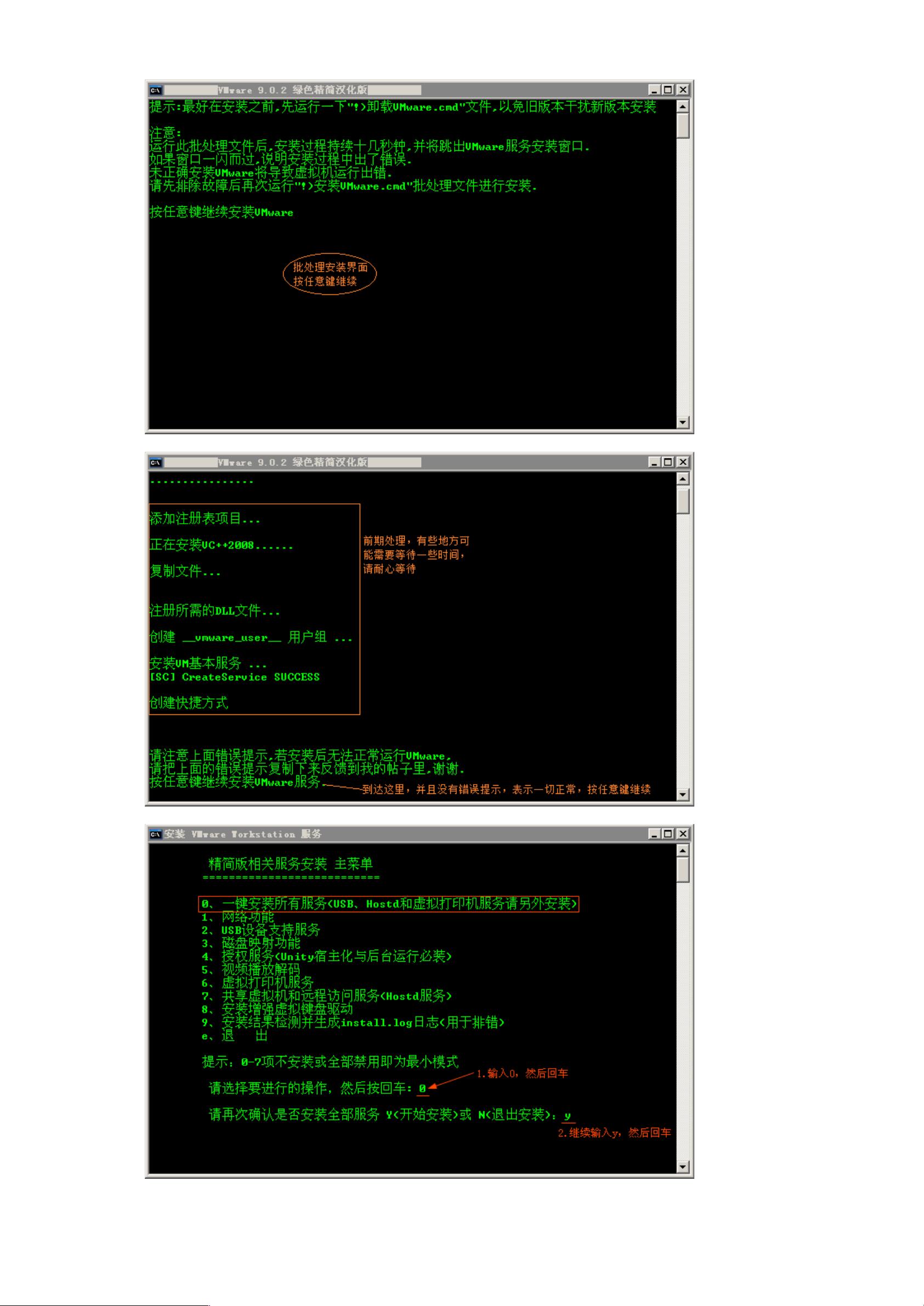
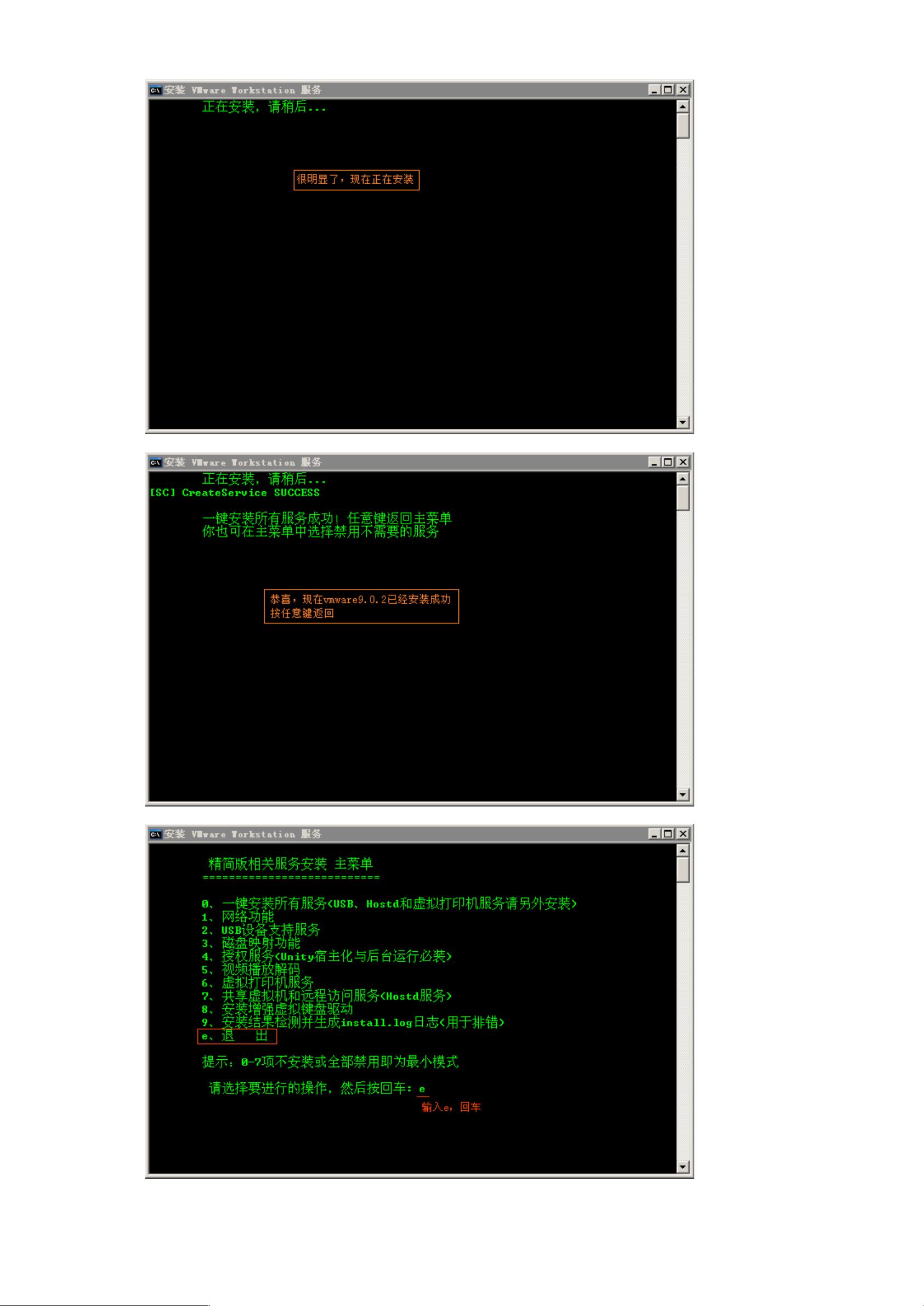
首先,确保卸载旧版Vmware,然后安装Vmware9.0.2。安装过程包括下载安装包、运行安装程序、接受许可协议、选择安装位置等步骤。安装完成后,启动Vmware并导入CentOS-6.4的ISO镜像,按照提示进行虚拟机的创建和系统安装。
CentOS-6.4安装完成后,首次启动会进入登陆界面。这时,需要通过SSH客户端,如Xshell,连接到Master节点。首先,获取Master节点的IP地址,然后在winscp中配置SFTP连接,将Windows上的Hadoop相关文件传输到Master节点。
接下来是Java环境的配置,这是Hadoop运行的基础。在Xshell中,使用root权限更新系统环境变量,设置JAVA_HOME指向Java安装目录,同时修改PATH变量,确保可以全局访问Java可执行文件。执行`java -version`命令确认Java已正确配置。
随后,我们需要在所有节点上安装Hadoop。将解压后的Hadoop安装包通过winscp复制到所有节点的相同路径下。配置Hadoop的配置文件,包括`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`。这些文件主要定义了HDFS的名称节点、数据节点,MapReduce的作业历史服务器,以及YARN的相关设置。
在`hadoop-env.sh`中设置HADOOP_PID_DIR和HADOOP_OPTS,确保Java内存分配合适。此外,还需要配置`slaves`文件,列出所有Slave节点的主机名。
完成配置后,启动Hadoop集群。首先格式化NameNode,然后启动DataNode、ResourceManager、NodeManager和HistoryServer。通过`jps`命令检查各个服务是否正常运行。
最后,验证Hadoop集群的正确配置,可以通过运行经典的WordCount示例。将示例程序上传到HDFS,然后提交JobTracker进行处理。观察输出结果,如果正确输出每个单词及其频率,那么恭喜,你已经成功配置了一个Hadoop集群。
配置Hadoop集群涉及多个步骤,包括环境准备、操作系统安装、文件传输、Java环境配置、Hadoop安装与配置、服务启动和测试。每一个环节都需要细心操作,确保无误,这样才能搭建出稳定、高效的Hadoop集群。


 我的内容管理
展开
我的内容管理
展开









