DARE:低耗高效的数据去重与相似性检测方案
28 浏览量
更新于2024-08-30
收藏 924KB PDF 举报
本文档探讨了"数据减少与低开销的重复检测与消除方案(DARE)",这是一项针对大数据时代存储系统中日益重要的数据缩减问题的研究。随着数字数据的爆炸性增长,大规模数据缩减面临着如何在极低的开销下最大限度地识别和消除冗余的挑战。DARE的设计目标是提供一种高效且低耗能的解决方案。
该研究论文由 Wen Xia、Hong Jiang、Dan Feng 和 Lei Tian 等作者提出,他们均为 IEEE 会员或院士。论文指出,传统的数据缩减技术可能在处理大量相似数据时效率低下,因此DARE旨在通过增强对重复数据的意识和识别能力来改进这一状况。它采用了新颖的重复检测方法,能够在不影响性能的前提下,准确地区分并移除重复的数据块,从而实现数据的高效压缩和存储空间的节省。
DARE的核心思想是结合数据去重(deduplication)技术和相似性检测算法,以最小化对系统性能的影响。它可能涉及高级的哈希函数或者机器学习技术来评估数据块之间的相似度,确保只有真正意义上的重复数据被消除。此外,为了降低操作开销,文章强调了算法的实时性和轻量级设计,以适应现代存储系统的高吞吐量需求。
值得注意的是,这篇论文尚未正式发表,但已经接受在《计算机交易》(IEEE Transactions on Computers)期刊的未来一期上发布。引用该文章时,应参考DOI 10.1109/TC.2015.2456015。作者们提醒读者,由于是预印本,内容可能会在最终出版前有所修改,因此对于具体细节和技术实现,读者应以最终版本为准。
总结来说,DARE是一个创新的框架,旨在解决存储系统中的数据冗余问题,通过低开销的重复检测和消除策略,帮助存储系统在大数据环境下提高存储效率和性能。它的成功实施将对存储技术的发展产生积极影响,并为其他类似领域的研究提供了有价值的参考。
0018-9340 (c) 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. See
http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI
10.1109/TC.2015.2456015, IEEE Transactions on Computers
SUBMITTED TO IEEE TRANSACTIONS ON COMPUTERS, MANUSCRIPT ID XXXX 3
TABLE 1
Comparisons between duplicate detection and
resemblance detection for data reduction systems.
Duplicate Detection Resemblance Detection
Objects Duplicate data Similar data
Granularity Chunk-level Byte-level
Rep. Methods Secure-Fingerprint Super-Feature based
based Deduplication Delta Compression
Scalability Strong Weak
Rep. Systems LBFS [11], Venti[5], REBL[16], DERD[15],
DDFS [6] SIDC[12]
Another challenge for data deduplication is how to
maximally detect and eliminate data redundancy in stor-
age systems by determining appropriate data chunking
schemes. In order to find more redundant data, the
Content-Defined Chunking (CDC) approach was pro-
posed in LBFS to find the proper cut-point of each chunk
in the files and address the boundary-shift problem [11],
[30], [9]. Re-chunking approaches were also proposed to
divide those non-duplicate chunks into smaller ones to
expose and detect more redundancy [31], [32], [33].
Resemblance detection with delta compression[16],
[15], [26], as another approach to data reduction in
storage systems, was proposed more than ten years
ago but was later overshadowed by fingerprint-based
deduplication [6], [25], [24] due to the former’s scala-
bility issue. Table 1 compares these two data reduction
approaches. Resemblance detection detects redundancy
among similar data at the byte level while duplicate
detection finds totally identical data at the chunk level,
which makes the latter much more scalable than the
former in mass storage systems.
REBL[16] and DERD [15] are typical super-feature-
based resemblance detection approaches for data reduc-
tion. They compute the features of the data stream (e.g.,
Rabin Fingerprints [34]) and group features into super-
features to capture the resemblance of data and then
delta compress the data. TAPER [35] presents a Bloom-
Filter solution that measures the similar files based on
the chunk fingerprints recorded in Bloom Filters. All
these approaches require high computation and indexing
overheads for resemblance detection. As a result, the
simpler and faster deduplication method has become a
more popular data reduction approach in the last five
years [8], [6], [7].
Nevertheless, resemblance detection is gaining in-
creasing tractions in storage systems because of its ability
to capture and eliminate data redundancy among similar
but non-duplicate data chunks that effectively comple-
ments fingerprint-based deduplication. Difference En-
gine [20] employs Xdelta [23] to further eliminate mem-
ory redundancy and thus enlarge the logical RAM
space in VM environments. I-CASH [18] delta com-
presses similar data to enlarge the logical space of SSD
caches. Shilane et al. [12] proposed a stream-informed
delta compression approach to reducing similar data
transmission and thus accelerating data replication in a
WAN environment. This approach is super-feature based
and complements the chunk-level deduplication by only
detecting resemblance among non-duplicate chunks in
Similar
File BFile A File C
File EFile D File F
B
1
B
2
B
3
B
5
B
4
E
1
E
2
E
3
E
5
ĂĂ
ĂĂ
Similar
Duplicate
E
4
Data stream 1
Data stream 2
Duplicate
Similar
Fig. 1. A conceptual illustration of the duplicate adjacency. The
non-duplicate chunks adjacent to duplicate ones are considered
potentially similar and thus good delta compression candidates.
the cache that preserves the backup stream locality. It
avoids the costly global indexing, at a limited loss of
resemblance detection. While the combined detection of
duplicate and resemblance promises to achieve a supe-
rior data reduction performance, challenges of relatively
high computation and indexing overheads stemming
from resemblance detection remain [17].
Note that SIDC [12] is the most related work to DARE.
Different from SIDC that implements traditional super-
feature based delta compression in a stream-informed
(i.e., locality preserved) cache, DARE first employs a
duplicate-adjacency based resemblance detection scheme
(see Section 3.2) and then an improved super-feature
based approach (see Section 3.3) to jointly and more
effectively reduce the indexing and computation over-
heads for delta compression.
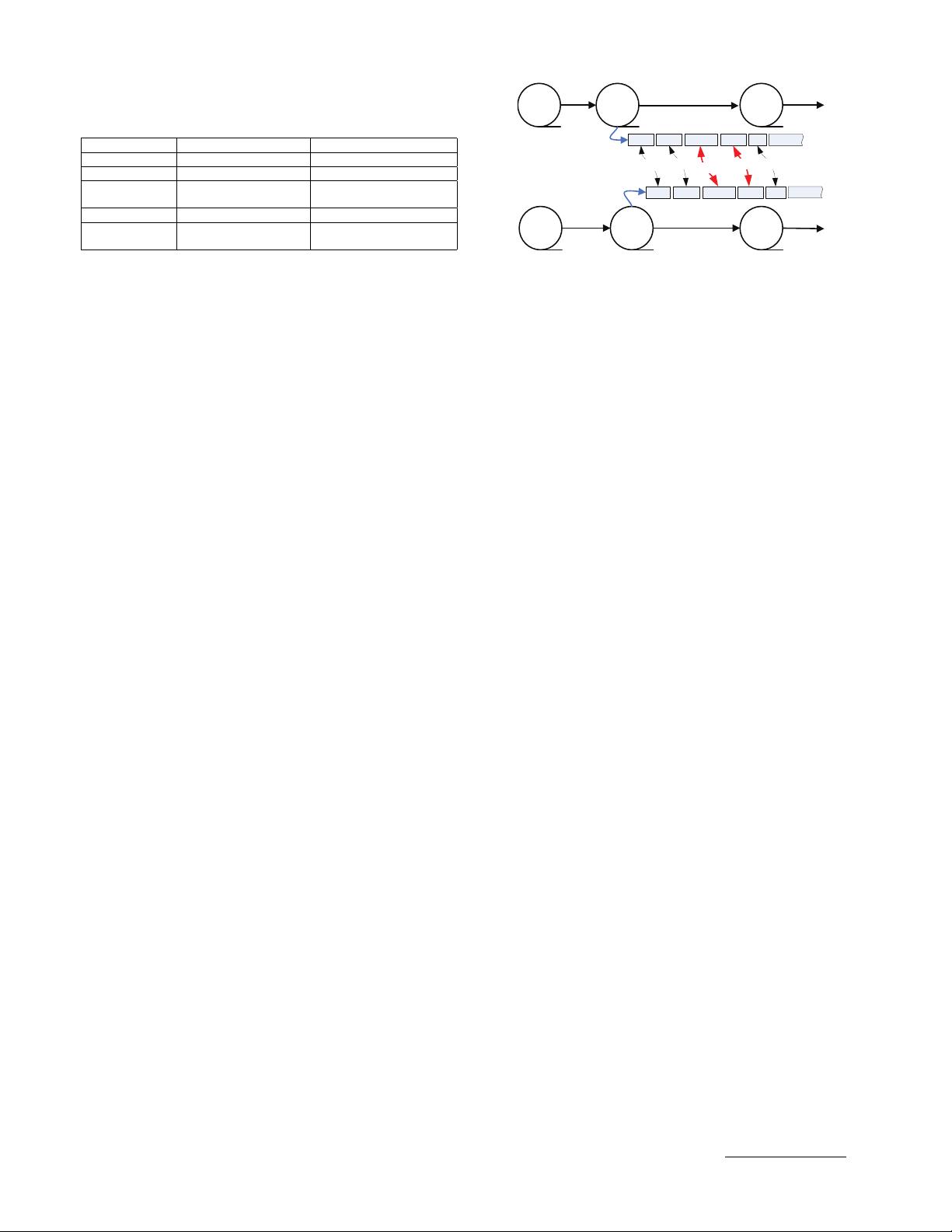
2.2 Fact of Duplicate Adjacency
As discussed in Section 2.1, the modified chunks may
be very similar to their previous versions in a backup
system while unmodified chunks will remain duplicate
and are easily identified by the deduplication process.
For those non-duplicate chunks that are location-adjacent to
known duplicate data chunks in a deduplication system, it
is intuitive and quite possible that only a few bytes of them
are modified from the last backup, making them potentially
excellent delta compression candidates.
Figure 1 illustrates a case of duplicate data chunks and
their immediate non-duplicate neighbors. As mentioned
above, our intuition is that the latter are highly likely to
be similar and thus good delta compression candidates.
Specifically, since chunks B
3
& B
4
are duplicates of
chunks E
3
& E
4
in Figure 1 respectively, their immediate
neighbors, the chunk-pairs B
1
& E
1
, B
2
& E
2
, and
B
5
& E
5
, are then considered good delta compression
candidates, which is consistent with the aforementioned
backup-stream locality [6], [12], [29], [25], [36].
If we can make full use of the existing knowledge
about duplicate data chunks in a deduplication system,
it is possible for us to detect similar chunks without the
overheads of computing and storing features & super-
features and then accessing their on-disk index. Figure
2 shows important preliminary results of this duplicate-
adjacency-based resemblance detection approach, called
DupAdj, on several real-world datasets whose workload
characteristics are detailed in Table 2 in Section 4.1.
First, the similarity degree (i.e.,
dela compressed size
chunk size
) of
剩余13页未读,继续阅读
2021-02-21 上传
2021-05-12 上传
2021-02-07 上传
2021-04-13 上传
2021-05-02 上传
2021-05-04 上传
2021-02-22 上传
2021-03-22 上传

weixin_38724919
- 粉丝: 5
- 资源: 991
 我的内容管理
展开
我的内容管理
展开







最新资源
- ES管理利器:ES Head工具详解
- Layui前端UI框架压缩包:轻量级的Web界面构建利器
- WPF 字体布局问题解决方法与应用案例
- 响应式网页布局教程:CSS实现全平台适配
- Windows平台Elasticsearch 8.10.2版发布
- ICEY开源小程序:定时显示极限值提醒
- MATLAB条形图绘制指南:从入门到进阶技巧全解析
- WPF实现任务管理器进程分组逻辑教程解析
- C#编程实现显卡硬件信息的获取方法
- 前端世界核心-HTML+CSS+JS团队服务网页模板开发
- 精选SQL面试题大汇总
- Nacos Server 1.2.1在Linux系统的安装包介绍
- 易语言MySQL支持库3.0#0版全新升级与使用指南
- 快乐足球响应式网页模板:前端开发全技能秘籍
- OpenEuler4.19内核发布:国产操作系统的里程碑
- Boyue Zheng的LeetCode Python解答集
