Java从零开始构建网络爬虫指南
需积分: 11 60 浏览量
更新于2024-07-28
收藏 2.49MB PDF 举报
"该资源是一本关于网络爬虫的教程,特别针对Java语言编写,旨在指导读者从零开始构建自己的网络爬虫。本书首先介绍了网络爬虫的基本概念和作用,指出尽管已有大型搜索引擎抓取了大量信息,但个性化和特定需求的数据抓取仍有其价值。在第1章中,作者详细讲解了网络爬虫的工作原理,包括如何抓取网页,理解URL(统一资源定位符)以及处理HTTP状态码的重要性。通过学习,读者将能够运用Java语言实现抓取网页的功能,并了解如何查看和解析网页源代码。"
在深入学习网络爬虫的过程中,首先要理解的是URL,它是Uniform Resource Locator的缩写,用于唯一标识互联网上的资源。在浏览器中输入的URL,如http://www.lietu.com,包含了几部分信息:协议(这里是HTTP),域名(www.lietu.com),以及可能的路径和查询参数。而URI(Universal Resource Identifier)更为广泛,不仅包括URL,还涵盖了其他类型的资源标识方式。
网络爬虫的基础操作是模拟浏览器向服务器发送请求,获取响应的网页内容。这一过程中,掌握HTTP状态码的理解至关重要,因为它能告诉爬虫请求是否成功。例如,200状态码表示请求成功,而404则表示资源未找到。通过处理不同的HTTP状态码,爬虫可以适当地处理错误或重试请求。
Java是一种常用的编程语言,用于实现网络爬虫。在示例中,读者将学习如何使用Java来构造HTTP请求,获取网页内容,并解析这些内容以提取所需信息。这通常涉及到使用HTTP库,如Apache HttpClient,以及HTML解析库,如Jsoup,来解析HTML文档,提取数据。
在后续章节中,可能会涵盖更多高级主题,如反爬虫策略的应对、数据存储、并发爬取以及爬虫架构的设计。这些知识对于创建一个高效且健壮的网络爬虫系统至关重要。通过逐步学习和实践,读者不仅可以掌握网络爬虫的基本技术,还能了解到如何处理实际应用中遇到的各种挑战。
12
1
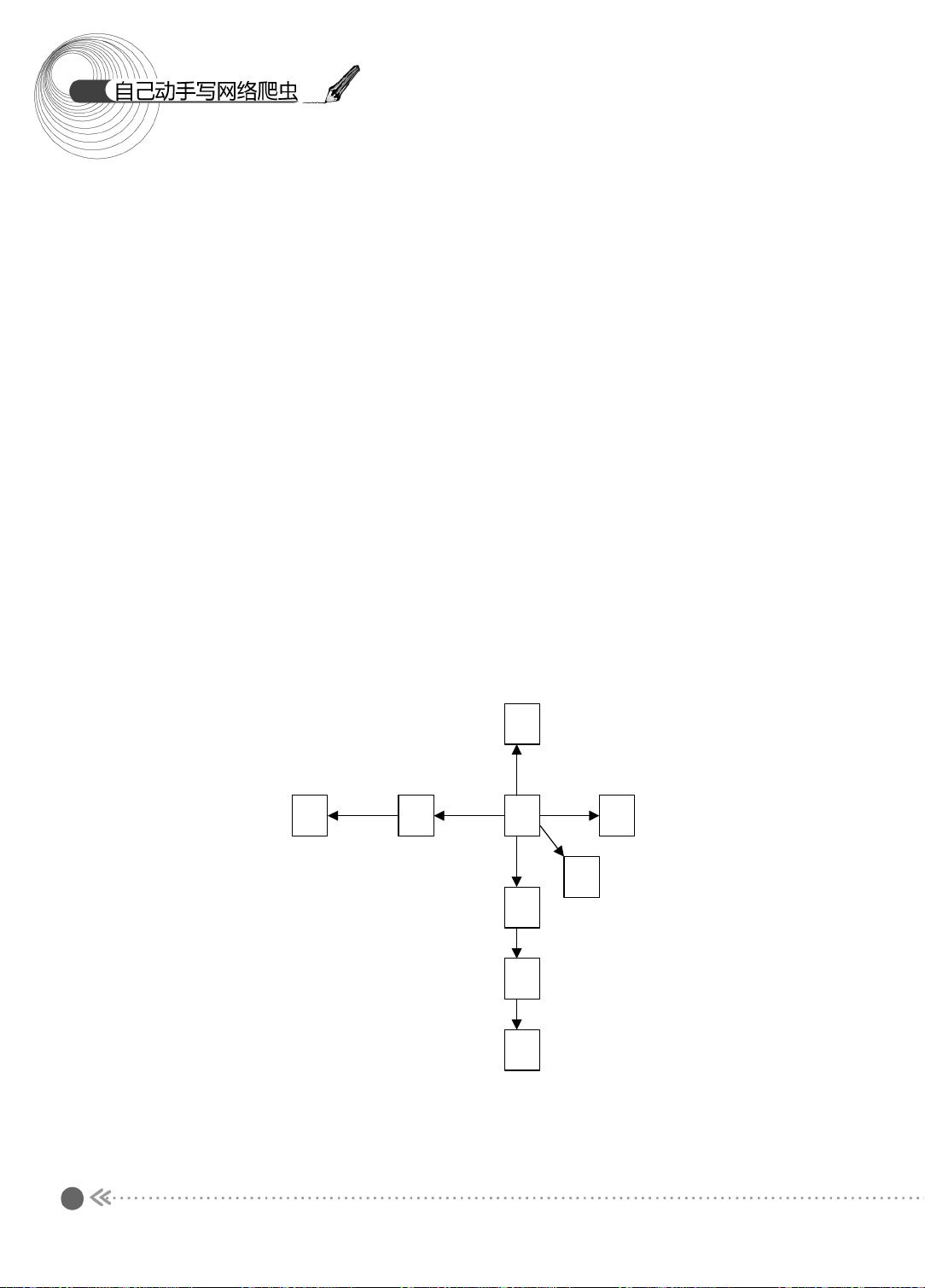
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
1.2.1 图的宽度优先遍历
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
201 浏览量
188 浏览量
244 浏览量
2025-01-05 上传
2025-01-05 上传
2025-01-05 上传
2025-01-05 上传

FinallKill
- 粉丝: 0
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







