两阶段锁详解:避免数据竞争与一致性破坏
下载需积分: 0 | PDF格式 | 2.93MB |
更新于2024-06-30
| 151 浏览量 | 举报
本资源主要介绍了数据库并发控制中的两阶段锁(Two-Phase Locking)概念及其在事务处理中的应用。在传统的数据库管理系统中,为了确保数据一致性,避免数据竞争和冲突,特别是R-W/W-R/W-W这样的竞态条件,引入了锁机制作为并发控制的关键手段。
在朴素的加锁方法中,每个事务在访问特定数据(如表的行)之前,需先通过数据库的锁管理器获取锁,例如S-锁(共享锁,类似读锁)和X-锁(排他锁,类似写锁)。S-锁允许事务读取数据而不会阻止其他事务读取同一数据,而X-锁则禁止其他事务对同一数据进行任何修改操作,确保数据的独占访问。
然而,简单的加锁策略存在一个问题,即依赖于冲突可串行化的判断方式在事务执行过程中无法实时检测是否可串行化,因为这需要等待所有事务完成后才能确认。如果最终执行调度是不可串行化的,即使使用锁也无法防止一致性破坏,因为数据已经被多个事务并发修改。
为解决这个问题,学者们提出了两阶段锁模型。第一阶段是预锁定(Locking Phase),在事务开始时,事务尝试获取所有可能冲突的数据对象的锁,这可以尽早地避免潜在的冲突。第二阶段是提交阶段(Commit Phase),只有当事务的所有操作完成且没有发生冲突时,事务才会正式提交并释放已经获取的锁。
尽管加锁可以一定程度上改善并发环境下的数据一致性,但并不能保证所有不可串行化的执行调度都能被转化为正确结果。例如,图示中的场景表明,即使使用了锁,T1和T2事务之间的交互仍然没有完全隔离,导致执行结果仍然缺乏一致性。因此,后续的研究和发展转向了更复杂的锁协议和并发控制技术,如死锁预防、恢复策略以及多版本并发控制(MVCC)等,以提高数据库系统的并发性能和一致性保障。
Two-Phase Locking
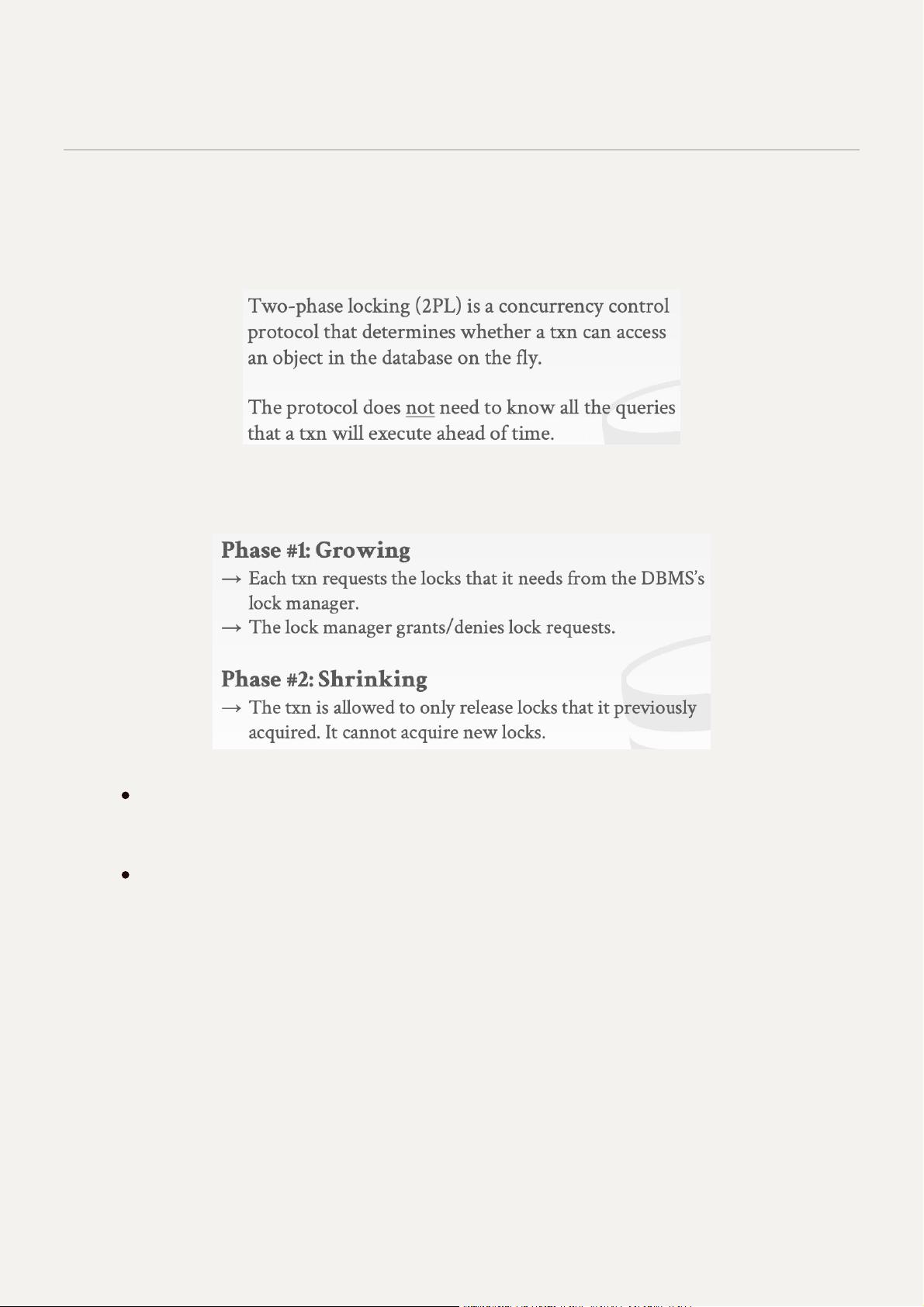
⼆阶段锁是⼀个并发控制协议,它规定了⼀个事务在运⾏的过程中如何跟其他事务之间协调
锁,从⽽实现可串⾏化。使⽤两阶段锁不需要提前知道完整的执⾏调度,它会在调度进⾏的
过程中避免不可串⾏化的情况发⽣
⼆阶段锁中有两个阶段
增长阶段(Growing)
在这个阶段事务只能不断地获得锁,不能释放锁
缩⼩阶段(Shrinking)
在这个阶段只能释放释放锁,不能再获取新的锁
在⼀个事务的⽣命周期⾥,它所持有的锁的数量的增长趋势如下所⽰,最后将所有获取过的
锁都释放后会提交事务:
剩余18页未读,继续阅读
相关推荐

341 浏览量



网络小精灵
- 粉丝: 36
- 资源: 334
 我的内容管理
展开
我的内容管理
展开







最新资源
- 叉车变矩器故障诊断及处理.rar
- BULLDOG-开源
- 草图设备:一些草图格式的设备
- libdaisy-rust:菊花板的硬件抽象层实现
- clangular:lan角
- 行业文档-设计装置-一种拒油抗静电纸质包装材料.zip
- ICLR-Workshop-Challenge-1-CGIAR-Computer-Vision-for-Crop-Disease:Zindi竞赛的入门代码-ICLR Workshop Challenge#1
- aklabeth:Akalabeth aka'Ultima 0'的翻拍-开源
- snglpg:Занимаясь“在浏览器中设计”
- OpenCore-0.6.2-09-09.zip
- 摩尔斯电码,实现将字符转为摩尔斯电码的主体功能,能将摩尔斯电码通过串口上位机进行显示
- matlab布朗运动代码-Zombie:用于团队项目的MATLAB僵尸启示仿真(2016)
- 纯css3圆形发光按钮动画特效
- mvntest
- 版本:效用调查,专家和UX使用者,请指责一个集体经济团体,请参阅一份通俗的经济通函,一份从业者的各种困难和疑难解答,请参见网站实际内容
- OpenCore-0.6.1-09-08正式版.zip
