Hadoop集群部署详解:安装配置与角色解析
需积分: 9 74 浏览量
更新于2024-07-22
收藏 4.23MB DOCX 举报
Hadoop集群(第5期)深入探讨了Apache软件基金会开源的分布式计算平台Hadoop的安装与配置。Hadoop核心包含两个关键组件:Hadoop分布式文件系统(HDFS)和MapReduce。
1. Hadoop简介:
- Hadoop是一个分布式计算平台,提供系统底层细节透明的分布式基础设施,使得用户可以在大规模数据集上进行高效处理。它起源于Google的MapReduce计算模型,但Hadoop提供了一个开源实现,即JobTracker和TaskTracker的组合。
- 集群角色分为Master(NameNode和JobTracker)和Slave(DataNode和TaskTracker)。NameNode是HDFS的中心管理器,负责命名空间管理和文件系统访问操作,而DataNode存储数据。JobTracker在MapReduce中负责任务调度和监控,确保任务在不同Slave节点上执行。
2. 环境配置:
- 集群共包含4个节点,其中1个为Master,3个为Slave,通过局域网相连,彼此间可以互相通信。节点操作系统均为CentOS 6.0,所有节点共享用户hadoop,Master节点承担NameNode和JobTracker的角色。
- 为了设置这样的集群,首先需要确保网络连通性,然后在每台机器上安装Hadoop,配置相应的环境变量和配置文件,如`core-site.xml`、`hdfs-site.xml`和`mapred-site.xml`等,它们定义了HDFS和MapReduce的参数,如数据块大小、副本数量和任务调度策略等。
3. 安装与配置步骤:
- 安装过程通常涉及下载Hadoop源代码,解压后运行编译脚本。然后配置环境变量,使系统能够在运行时找到Hadoop的库和工具。
- 对于NameNode,需要配置`/etc/hadoop/conf`下的`hdfs-site.xml`,指定DataNode的地址,以及存储目录。对于JobTracker,需配置`mapred-site.xml`来定义任务调度策略。
- 接着启动Hadoop服务,包括启动NameNode、DataNodes、JobTracker和TaskTrackers,以及监控服务,确保集群的正常运行。
4. 注意事项:
- 配置过程中可能遇到的挑战包括网络问题、磁盘空间规划、权限设置等。此外,Hadoop集群的扩展性和容错性依赖于正确配置,例如通过复制因子和心跳检测机制保证数据的一致性和可靠性。
5. 后续维护与优化:
- 定期检查Hadoop的日志文件,识别潜在的问题,如资源瓶颈、数据丢失等。随着数据的增长,可能需要调整集群规模,增加或减少节点。
Hadoop集群的安装配置涉及到多个步骤和组件间的协同工作,确保数据的可靠存储和高效的分布式计算。通过理解Hadoop的核心原理和细致的配置,用户可以构建和管理一个强大而灵活的大数据处理环境。

创建时间:2012/2/26 修改时间:2012/3/17 修改次数:1
假设没有安装 ssh 和 rsync,可以通过下面命令进行安装。
yum install ssh 安装 SSH 协议
yum install rsync (rsync 是一个远程数据同步工具,可通过 LAN/WAN 快速同步多台主机
间的文件)
service sshd restart 启动服务
确保所有的服务器都安装,上面命令执行完毕,各台机器之间可以通过密码验证相互登。
2.2 配置 Master 无密码登录所有 Salve
1)SSH 无密码原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器
Salve(DataNode | Tasktracker)上时,需要在 Master 上生成一个密钥对,包括一个公钥和
一个私钥,而后将公钥复制到所有的 Slave 上。当 Master 通过 SSH 连接 Salve 时,Salve
就会生成一个随机数并用 Master 的公钥对随机数进行加密,并发送给 Master。Master 收到
加密数之后再用私钥解密,并将解密数回传给 Slave,Slave 确认解密数无误之后就允许
Master 进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。重要过程
是将客户端 Master 复制到 Slave 上。
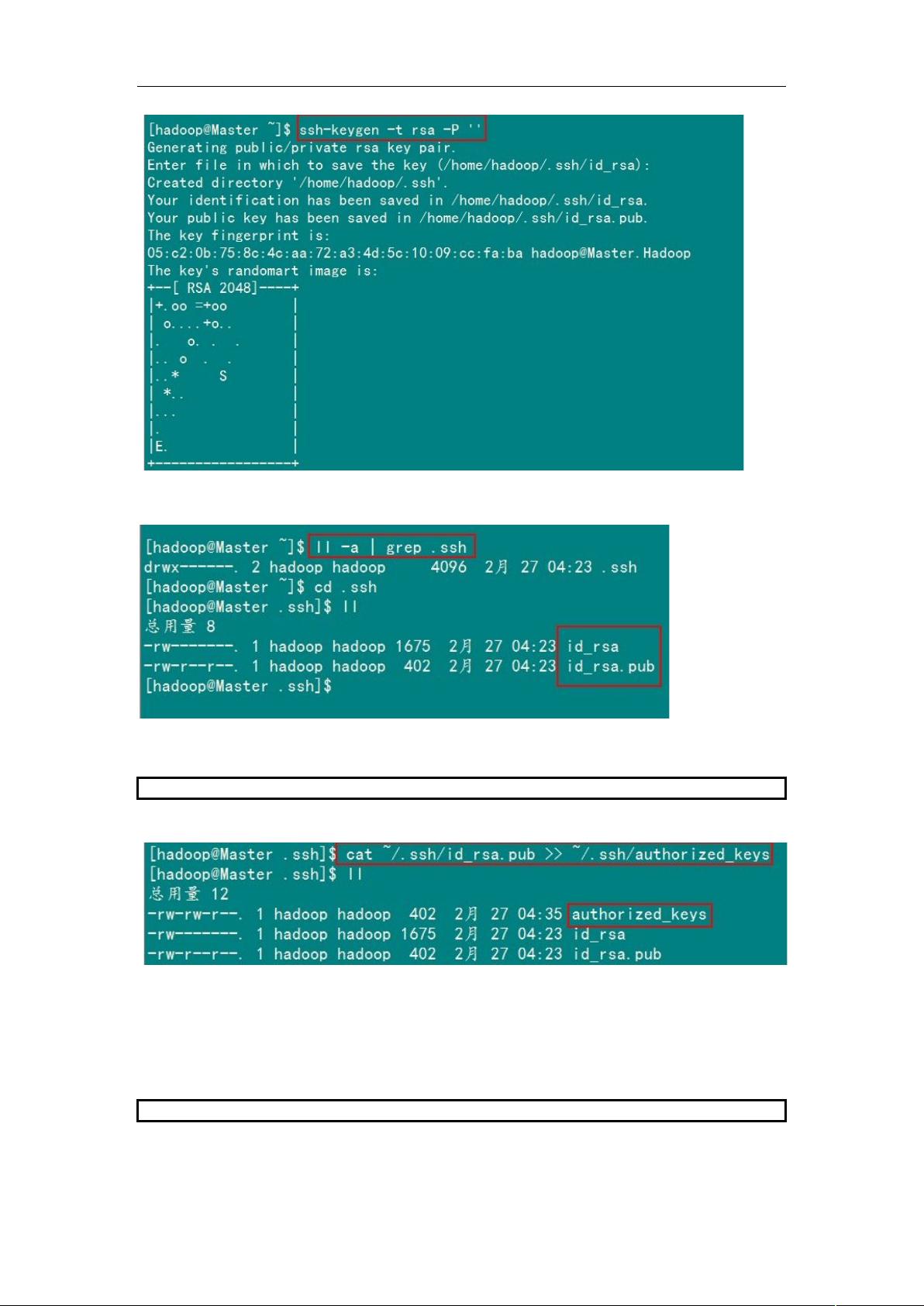
2)Master 机器上生成密码对
在 Master 节点上执行以下命令:
ssh-keygen –t rsa –P ’’
这条命是生成其无密码密钥对,询问其保存路径时直接回车采用默认路径。生成的密钥对:
id_rsa 和 id_rsa.pub,默认存储在“/home/hadoop/.ssh”目录下。
河北工业大学——软件工程与理论实验室 编辑:虾皮 8
剩余46页未读,继续阅读
2015-10-26 上传
2012-05-08 上传
2022-09-21 上传
2022-09-24 上传
2012-05-08 上传
2022-03-20 上传
2022-03-20 上传
2022-03-20 上传
2022-09-24 上传

hibay_mark
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
