Apache Flink:实时流处理与超越
需积分: 9 100 浏览量
更新于2024-07-18
收藏 3.62MB PDF 举报
"Apache Flink是开源的流处理框架,它基于流式处理模型,特别适合对无界数据集进行实时处理。Apache Flink提供了一个融合的平台,支持快速且轻松地构建突破性的实时应用程序,使得数据能够即时用于流处理。在全球物联网(IoT)规模下,它能实现每秒复制数百万条消息的能力。用户可以通过相关的免费培训课程进一步学习Flink,如MapR的Learn Streaming课程。此外,还有一本由Ellen Friedman和Kostas Tzoumas合著的《Introduction to Apache Flink》,详细介绍了Flink的流处理技术及其超越实时应用的潜力。"
Apache Flink是一个强大的分布式流处理引擎,它旨在处理连续不断的数据流,同时也支持批处理,为开发者提供了统一的数据处理模型。Flink的核心特性包括:
1. **流处理模型**:Flink基于DataStream API,它支持两种数据流类型——无界流(unbounded streams)和有界流(bounded streams)。无界流是无限的,而有界流是有限的,这种模型使得Flink可以处理各种实时和历史数据。
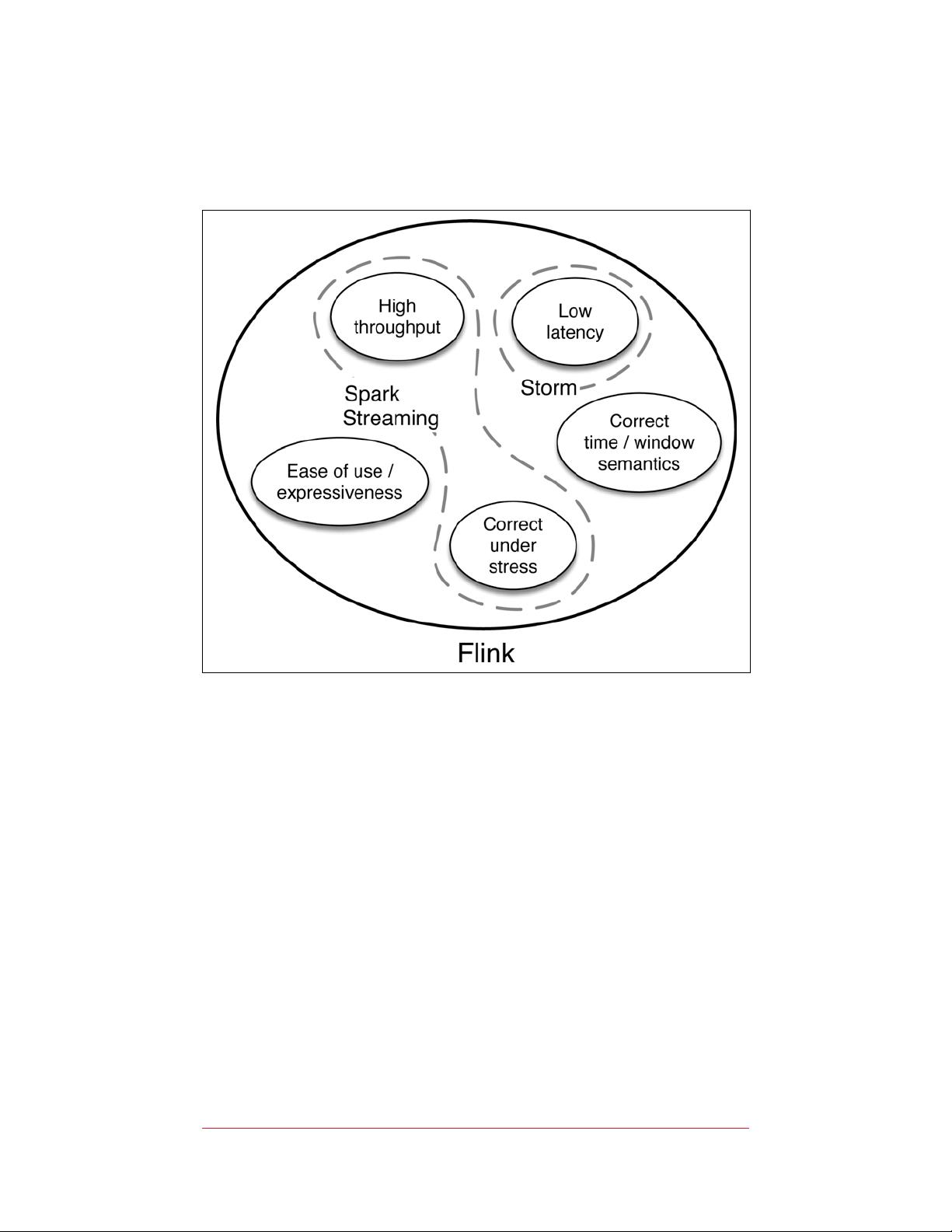
2. **事件时间处理**:Flink支持事件时间处理,这在处理延迟数据或者乱序事件时非常重要,因为它确保了数据处理的准确性。
3. **状态管理和容错**:Flink通过其检查点和保存点机制实现了高效的状态管理和故障恢复,保证了数据的一致性和处理的精确一次(Exactly-once)语义。
4. **低延迟与高吞吐**:Flink设计目标之一就是低延迟,同时能处理高吞吐量的数据流,使其在实时分析领域具有竞争优势。
5. **丰富的算子和连接器**:Flink提供了一系列的算子,如窗口操作、状态操作等,以及多种数据源和数据 sink的连接器,便于与其他系统集成。
6. **批处理与流处理的统一**:Flink通过统一的API,将批处理看作是特殊形式的流处理,这简化了开发和维护工作。
7. **内存优化和并行计算**:Flink使用高效的内存管理策略,以及分布式并行执行模型,能够有效地利用多核CPU和大规模集群资源。
8. **与Hadoop集成**:Flink能够很好地与Hadoop生态系统中的其他组件如HDFS、YARN等集成,允许用户无缝迁移或扩展现有的Hadoop应用。
9. **实时交互查询**:Flink SQL和Table API提供了SQL接口,支持实时交互式查询,使业务分析师也能直接对流数据进行分析。
10. **全球化部署**:Flink可以在全球范围内进行数据复制和处理,支持大型的、分布式的物联网应用。
Apache Flink作为一个强大的流处理框架,不仅具备实时处理能力,还能提供批处理功能,是构建实时数据分析和决策系统的重要工具。通过学习和掌握Flink,开发者能够构建出更高效、可靠的实时应用程序,满足现代大数据处理的需求。

exactly-once guarantees for maintaining accurate state, and even the
guarantees that Storm could provide came at a high overhead.
Overview of Lambda Architecture: Advantages and
Limitations
The need for affordable scale drove people to distributed file sys‐
tems such as HDFS and batch-based computing (MapReduce jobs).
But that approach made it difficult to deal with low-latency
insights. Development of real-time stream processing technology
with Apache Storm helped address the latency issue, but not as a
complete solution. For one thing, Storm did not guarantee state
consistency with exactly-once processing and did not handle event-
time processing. People who had these needs were forced to imple‐
ment these features in their application code.
A hybrid view of data analytics that mixed these approaches offered
one way to deal with these challenges. This hybrid, called Lambda
architecture, provided delayed but accurate results via batch Map‐
Reduce jobs and an in-the-moment preliminary view of new results
via Storm’s processing.
The Lambda architecture is a helpful framework for building big
data applications, but it is not sufficient. For example, with a
Lambda system based on MapReduce and HDFS, there is a time
window, in hours, when inaccuracies due to failures are visible.
Lambda architectures need the same business logic to be coded
twice, in two different programming APIs: once for the batch sys‐
tem and once for the streaming system. This leads to two codebases
that represent the same business problem, but have different kinds
of bugs. In practice, this is very difficult to maintain.
To compute values that depend on multiple
streaming events, it is necessary to retain data
from one event to another. This retained data is
known as the state of the computation. Accurate
handling of state is essential for consistency in
computation. The ability to accurately update
state after a failure or interruption is a key to
fault tolerance.
8 | Chapter 1: Why Apache Flink?
https://www.iteblog.com



剩余107页未读,继续阅读
2022-03-15 上传
2022-01-18 上传
2021-03-19 上传
2021-05-13 上传
2019-04-26 上传
2019-10-25 上传
2015-02-28 上传
2019-09-17 上传

qq_29668687
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
