揭秘Spark作业全生命周期:Driver与组件交互图解
57 浏览量
更新于2024-08-30
收藏 263KB PDF 举报
在Spark源码系列的第四章中,我们深入探讨了Spark作业的生命周期,特别是关注于DriverProgram(驱动程序)及其与SparkContext的交互。SparkContext是Spark编程的核心,它负责创建和管理RDD(弹性分布式数据集),用户通过它来执行各种操作。
在SparkContext初始化过程中,两个关键组件DAGScheduler(有向无环图调度器)和TaskScheduler(任务调度器)被实例化。在standalone模式下,TaskScheduler的具体实现是TaskSchedulerImpl。在这个阶段,SparkContext会传递一个SparkDeploySchedulerBackend实例,用于后续的部署和通信。
SparkDeploySchedulerBackend的主要职责之一是启动一个AppClient。AppClient的创建涉及到构造一个Command对象,包含了ExecutorBackend的类名、命令参数、SparkContext的环境变量等信息,以及Spark的主目录(sparkHome)和UI地址。随后,AppClient会连接到Master节点进行应用的注册。
在图示中,展示了Driver与Master之间的三方通信过程。首先,Driver通过AppClient与Master建立连接,然后发送ApplicationDescription,包含了应用程序的基本信息,如名称、最大可用核心数(由spark.cores.max参数控制)、每个executor的内存限制(由spark.executor.memory设置)、ExecutorBackend的命令和其他配置。最后,AppClient将ApplicationDescription发送给Master,标志着作业的注册过程开始。
整个过程中,Driver扮演着调度中心的角色,它不仅负责初始化和配置各个组件,还与Master进行通信,确保作业的正确部署和执行。Master则负责协调资源分配和任务调度,保证作业的并行处理和性能优化。这个深入理解Spark作业生命周期的过程对于开发者来说,有助于更好地掌握Spark的工作原理,从而提高代码的效率和可维护性。
Spark源码系列(四)图解作业生命周期源码系列(四)图解作业生命周期
这一章我们探索了Spark作业的运行过程,但是没把整个过程描绘出来,好,跟着我走吧,let you know!
我们先回顾一下这个图,Driver Program是我们写的那个程序,它的核心是SparkContext,回想一下,从api的使用角
度,RDD都必须通过它来获得。
下面讲一讲它所不为认知的一面,它和其它组件是如何交互的。
Driver向Master注册Application过程
SparkContext实例化之后,在内部实例化两个很重要的类,DAGScheduler和TaskScheduler。
在standalone的模式下,TaskScheduler的实现类是TaskSchedulerImpl,在初始化它的时候SparkContext会传入一个
SparkDeploySchedulerBackend。
在SparkDeploySchedulerBackend的start方法里面启动了一个AppClient。
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend", args, sc.executorEnvs,
classPathEntries, libraryPathEntries, extraJavaOpts)
val sparkHome = sc.getSparkHome()
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
sparkHome, sc.ui.appUIAddress, sc.eventLogger.map(_.logDir))
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
maxCores是由参数spark.cores.max来指定的,executorMemoy是由spark.executor.memory指定的。
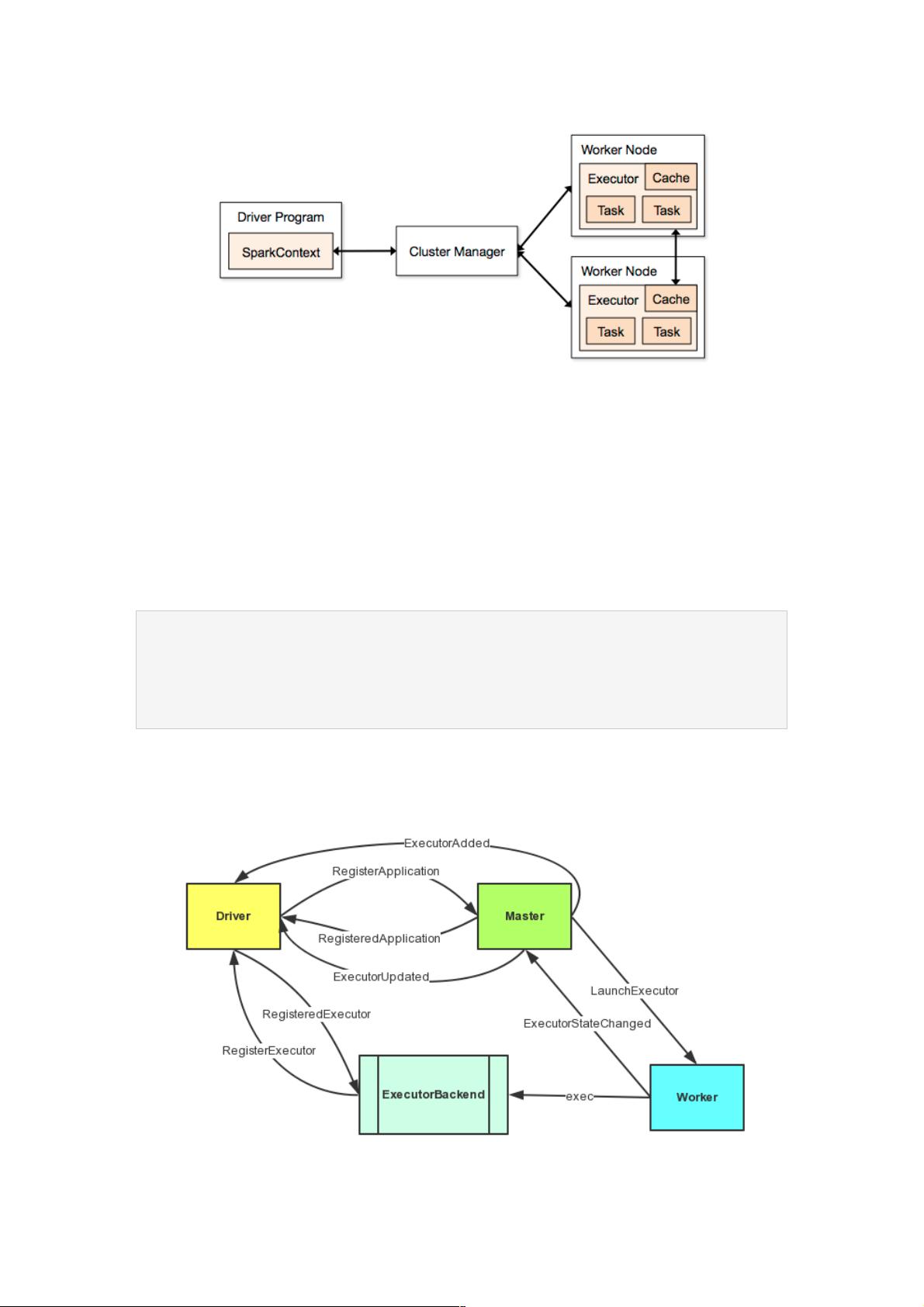
AppClient启动之后就会去向Master注册Applicatoin了,后面的过程我用图来表达。
上面的图中涉及到了三方通信,具体的过程如下:
1、Driver通过AppClient向Master发送了RegisterApplication消息来注册Application,Master收到消息之后会发送
RegisteredApplication通知Driver注册成功,Driver的接收类还是AppClient。
下载后可阅读完整内容,剩余3页未读,立即下载
2018-05-02 上传
2021-01-30 上传
2021-01-30 上传
2018-01-20 上传
2021-01-30 上传
2021-03-03 上传
2021-01-30 上传
2021-01-30 上传
2018-11-18 上传

weixin_38593823
- 粉丝: 8
- 资源: 894
 我的内容管理
展开
我的内容管理
展开







最新资源
- Haskell编写的C-Minus编译器针对TM架构实现
- 水电模拟工具HydroElectric开发使用Matlab
- Vue与antd结合的后台管理系统分模块打包技术解析
- 微信小游戏开发新框架:SFramework_LayaAir
- AFO算法与GA/PSO在多式联运路径优化中的应用研究
- MapleLeaflet:Ruby中构建Leaflet.js地图的简易工具
- FontForge安装包下载指南
- 个人博客系统开发:设计、安全与管理功能解析
- SmartWiki-AmazeUI风格:自定义Markdown Wiki系统
- USB虚拟串口驱动助力刻字机高效运行
- 加拿大早期种子投资通用条款清单详解
- SSM与Layui结合的汽车租赁系统
- 探索混沌与精英引导结合的鲸鱼优化算法
- Scala教程详解:代码实例与实践操作指南
- Rails 4.0+ 资产管道集成 Handlebars.js 实例解析
- Python实现Spark计算矩阵向量的余弦相似度
