




时序聚类:十年回顾与展望
需积分: 11 85 浏览量
更新于2024-07-16
收藏 1.27MB PDF 举报
"这篇论文是2015年由Saeed Aghabozorgi、Ali Seyed Shirkhorshidi和Teh Ying Wah在University of Malaya的Department of Information System发表的,名为《时序聚类——十年回顾》。文章深入探讨了时序聚类的各个方面,并列举了一些关键方法,旨在对过去十年的时序聚类研究进行总结和评估。"
时序聚类是一种无监督学习方法,用于将大量没有预先标记的数据集分成不同的组或簇,以便发现数据中的潜在结构和模式。随着云计算和大数据等新概念的出现,对无监督解决方案如聚类算法的需求日益增长,因为它们可以从海量数据中挖掘有价值的信息。
时序数据是随着时间变化的一系列数值,广泛应用于许多科学领域,包括气象学、生物医学、金融分析和物联网等。时序聚类特别适用于处理大规模数据集,因为在这些情况下,监督学习方法由于缺乏标签往往难以应用。而无监督的聚类方法能够不依赖于预先存在的类别信息来组织和理解数据。
论文中可能涉及的关键概念包括:
1. 距离度量:聚类过程依赖于计算不同时间序列之间的相似性。常见的距离度量有欧氏距离、动态时间规整(DTW)、曼哈顿距离和余弦相似性等。选择合适的距离度量对于正确识别相似的时间序列至关重要。
2. 评价指标:评估聚类结果的质量通常使用外部和内部标准。外部标准如调整 rand 指数和轮廓系数,基于已知的类标签;内部标准如 Calinski-Harabasz 指数和 Davies-Bouldin 指数,则基于聚类本身的特性。
3. 表示方法:时间序列的表示形式也会影响聚类效果。常见的表示包括原始值、差分、平滑化、特征提取(如傅立叶变换或PCA)以及时间序列形状let等。
4. 聚类算法:文中可能涵盖了多种时序聚类算法,如基于距离的K-means、DBSCAN、BIRCH、谱聚类,以及特定于时序的算法,如ELKI中的ST-DBSCAN、TCut和T-Linkage等。
通过对这些领域的回顾,论文旨在为研究人员提供一个全面的理解,以便他们可以选择最适合其特定应用的时序聚类方法。此外,这种回顾性研究也为未来的研究指明了可能的方向,如改进距离度量、开发更适应时序数据的聚类算法,以及探索新的评估和可视化技术。
for each time-series,) and then a suitable model distance
and a clustering algorithm (usually conventional clustering
algorithms) is chosen and applied to the extracted model
parameters [16]. However, it is shown that usually model-
based approaches has scalability problems [78], and its
performance reduces when the clusters are close to each
other [79].
Reviewing existing works in the literature, it is implied
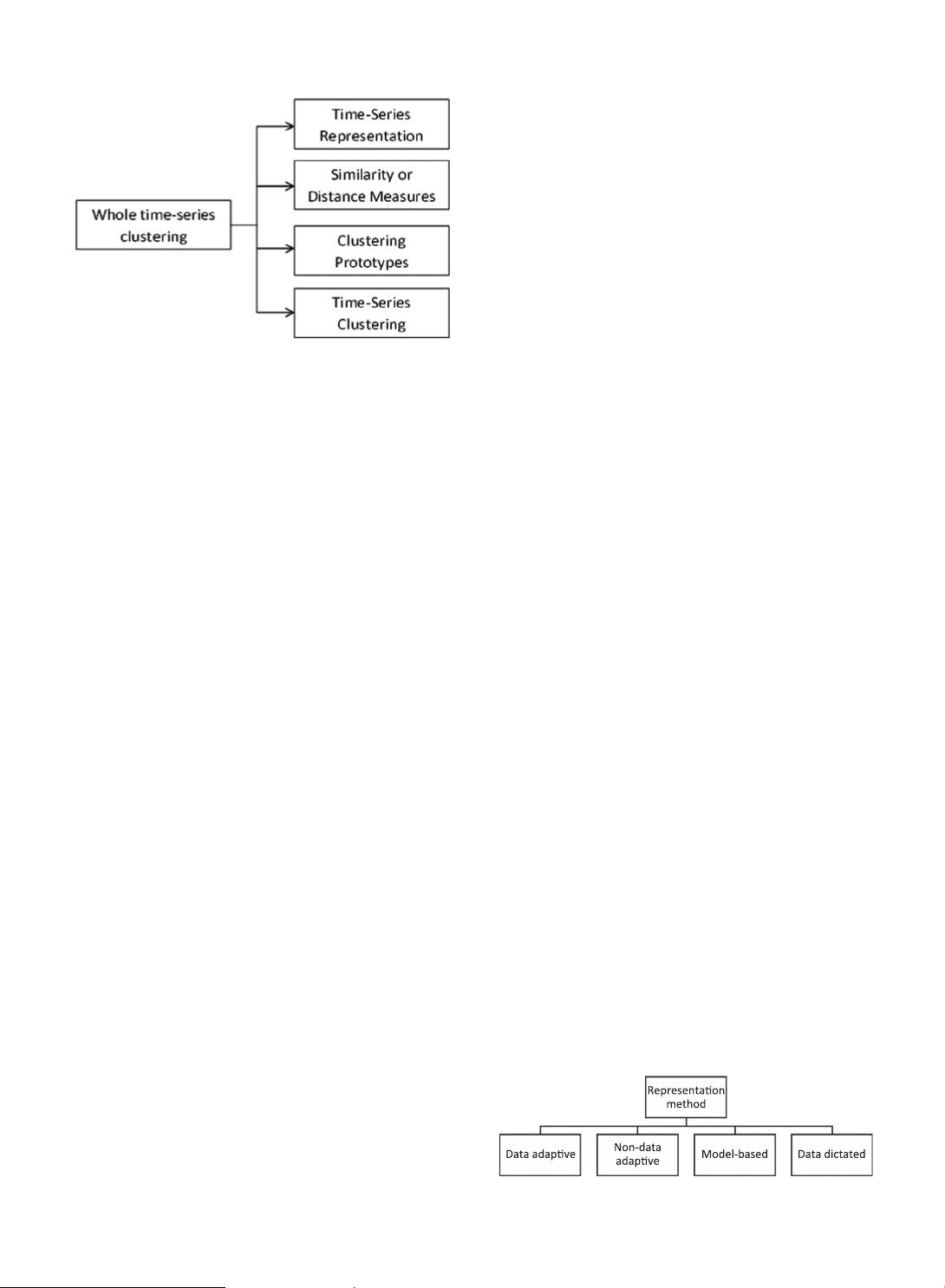
that essentially time-series clustering has four components:
dimensionality reduction or representation method, dis-
tance measurement, clustering algorithm, prototype defini-
tion, and evaluation. Fig. 3 shows an overview of these
components.
The general process in the time-series clustering uses
some or all of these components depending on the problem.
Usually, data is approximated using a representation
method in such a way that can fit in memory. Afterwards,
a clustering algorithm is applied on data by using a distance
measure. In the clustering process, usually a prototype is
required for summarization of the time-series. At last, the
clusters are evaluated using criteria. In the following sub-
sections, each component is discussed, and several related
works and methods are reviewed.
1.4. Organization of the review
In the rest of this paper, we will provide a state-of-the-
art review on main components available in time-series
clustering plus the evaluation methods and measures avail-
able for validating time-series clustering. In Section 2, time-
series representation is discussed. Similarity and dissimilar-
ity measures are represented in Section 3. Sections 4 and 5
are dedicated to clustering prototypes and clustering algo-
rithms respectively. In section 6 evaluation measures is
discussed and finally the paper is concluded in Section 7.
2. Representation methods for time series clustering
The first component of time-series clustering explained
here is dimension reduction which is a common solution for
most whole time-series clustering approaches proposed in
the literature [9,80–82]. This section reviews methods of
time-series dimension reduction which is known as time-
series representation as well. Dimensionality reduction r epre-
sents the raw time-series in another space by transforming
time-series to a lower dimensional space or by feature
extraction. The reason that dimensionality reduction is
greatly important in clustering of time-series is firstly because
itreducesmemoryrequirementsasallrawtime-series
cannot fit in the main memory [9,24]. Secondly, distance
calculation among raw data is computationally expensive,
and dimensionality reduction significantly speeds up cluster-
ing [9,24]. Finally, when measuring the distance between two
raw time-series, highly unintuitive results may be garnered,
because some distance measures are highly sensitive to some
“distortions” in the data [3,83], and consequently, by using
raw time-series, one may cluster time-series which are
similar in noise instead of clustering them based on similarity
in shape. The potential to obtain a different type of cluster is
the reason why choosing the appropriate approach for
dimension reduction (feature extr action) and its ratio is a
challenging task [26]. In fact, it is a trade-off between speed
and quality and all efforts must be made to obtain a proper
balance point between quality and execution time.
Definition 2:. Time-series representation, given a time-
series data F
i
¼ f
1
; ::; f
t
; ::; f
T
, representation is transform-
ing the time-series to another dimensionality reduced
vector F
'
i
¼ f
'
1
; ::; f
'
x
no
where xo T and if two series are
similar in the original space, then their representations
should be similar in the transformation space too.
According to [83], choosing an appropriate data representa-
tion method can be considered as the key component which
effects the efficiency and accuracy of the solution. High
dimensionality and noise are characteristics of most time-
series data [6], consequentl y , dimensionality reduction meth-
ods are usuall y used in whole time-series cluster ing in or der to
address these issues and promote the performance. Time-
series dimensionality reduction techniques have progr essed a
long wa y and are widel y used with larg e scale time-series
dataset and each has its own features and drawbac ks. Accord-
ingly , many researches had been carried out focusing on
representation and dimensionality reduction [84–90].Itis
worth here to mention about the one of the recent compar -
isons on representation methods. H. Ding et al. [91] hav e
performed a comprehensive comparison of 8 representation
methods on 38 datasets. Although, they had investigated the
indexing effectiveness of representation methods, the results
are advantag eous for clustering purpose as well. They use
tightness of lo wer bounds to compar e representation methods.
They show that there is very little difference between recent
representatio n methods. In tax onom y of representations, ther e
are generally four representation types [9,83,92,93]:data
adaptive, non-data adaptive, model-based and data dictated
representation approaches as are depicted in Fig. 4.
Fig. 3. An overview of four components of whole time-series clustering.
Fig. 4. Hierarchy of different time-series representation approaches.
S. Aghabozorgi et al. / Information Systems 53 (2015) 16–3820
下载后可阅读完整内容,剩余22页未读,立即下载
110 浏览量
2052 浏览量
624 浏览量
140 浏览量
2025-03-21 上传
2025-03-21 上传

weixin_43326944
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开








最新资源
- 迅享迅雷会员登陆器1.7版:快速获取白金账号
- iOS仿系统日历源码工程项目解析
- 展示个人技术实力:devjun63的GitHub投资组合
- AutoCAD教育版打印戳记管理工具R17.32-2012.06版介绍
- War Helper最新版功能增强:支持键鼠及语音设置
- DW1820 WIN10驱动程序下载 - 亲测有效
- 掌握ListCtrl四种显示样式的实现技巧
- 深入理解Microsoft Visual C++6.0运行库的使用
- 视频聊天应用:实时互动与通讯的新体验
- 在Eclipse中自定义编程英文字体的步骤
- 操作系统基础简答题精华整理
- C#实现D3D技术:三个球体自转与互绕系统
- 打造个人网络云盘:黑群晖3615/3617/918+安装教程
- 百度UEditor Mini版1.2.2集成与运行指南
- 打造高效Flash导航制作工具
- MERN博客应用:打造全新互动阅读与写作平台










