LVT: 提升轻量化Transformer视觉性能的创新方法
101 浏览量
更新于2024-06-20
收藏 2.98MB PDF 举报
增强自我关注的轻量级视觉Transformer网络,或LVT,是一种针对移动设备部署优化的新型Transformer模型,旨在解决当前轻量级模型在处理图像任务时存在的局部一致性问题和密集预测不准确的问题。Transformer架构,最初由Dosovitskiy[18]引入到计算机视觉领域,通过模仿自然语言处理中的自我注意机制,实现了在图像识别、对象检测和语义分割等任务中的出色表现。
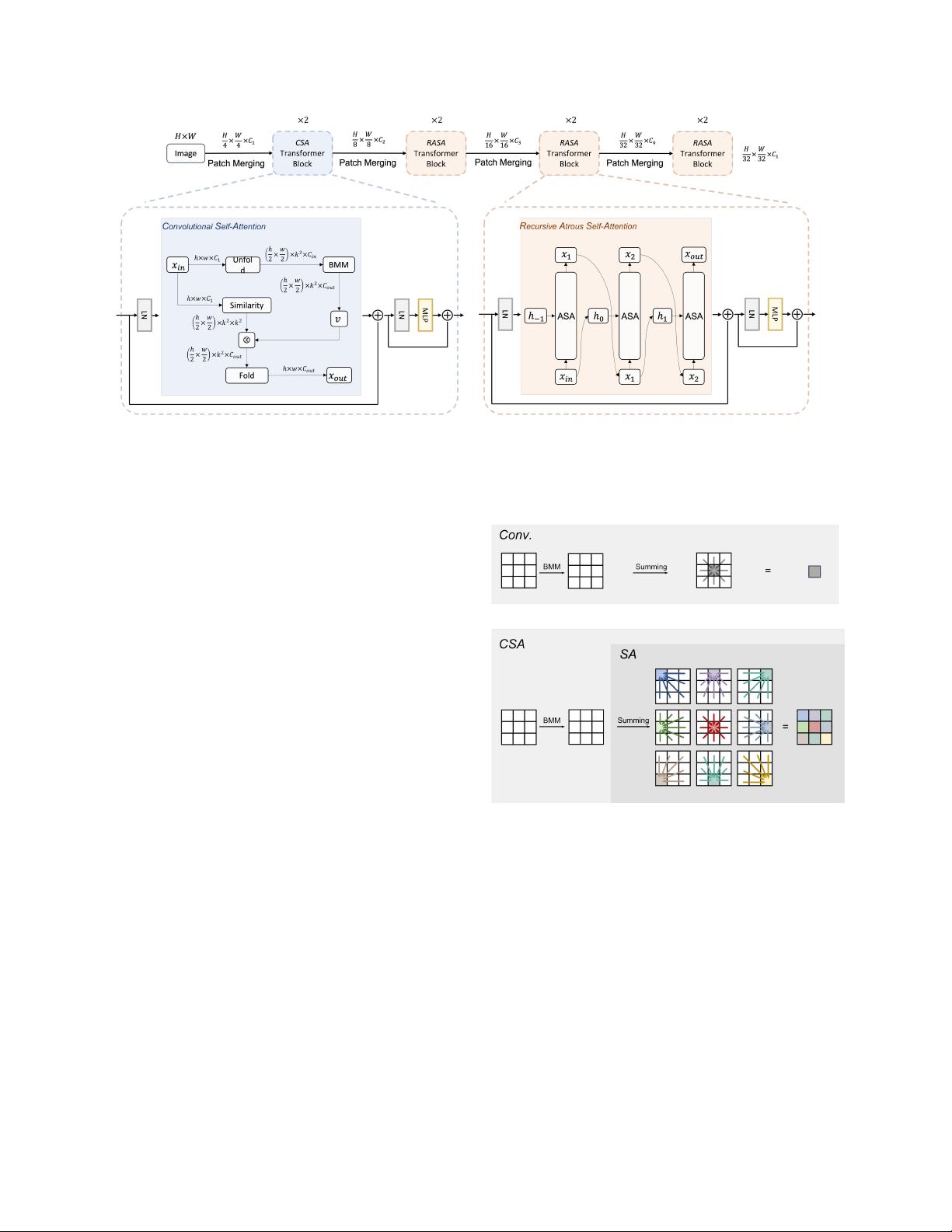
LVT的设计重点在于增强自注意力机制,以适应更浅和更薄的网络结构。针对低层次特征,LVT采用了创新的卷积自注意力(CSA)模块。与传统的融合方法不同,CSA引入了3x3大小的局部自注意力内核,在卷积层内部进行操作,增强了对底层特征的丰富和表达能力。这有助于捕捉更精确的局部特征,从而提高模型在早期阶段的表现。
在高层次特征处理上,LVT提出了递归自注意力(RASA)算法。RASA利用多尺度上下文来计算相似性映射,通过这种方式,模型能够更好地理解和整合来自不同层面的信息,进一步提升整体性能。RASA的优势在ImageNet图像识别、ADE20K语义分割以及COCO全景分割任务上得到了验证,尤其是在移动场景下的COCO全景分割任务中,LVT明显提高了标签的准确性。
LVT的编码器架构选择对于模型的整体性能至关重要,尤其是在与MobileNetV2和PVTv2-B0这样的轻量级模型比较时,LVT能够在保持相同训练和测试流程的前提下,提供显著的性能提升。这一成果表明,通过优化的自注意力机制,即使是轻量级的Transformer模型也能在移动设备上展现出强大的视觉处理能力,并且在实际应用中具有很高的实用价值。研究人员已经将LVT的代码开源,以便于学术界和业界的进一步研究和应用发展。
12000
×
×
×
×
×
图2.Lite Vision Transformer(LVT)。顶行表示LVT的总体结构左下角和右下角部分可视化了所提出的卷积自注意力(CSA)
和递归
Atrous
自注意力(
RASA
)。
H
,
W
表示图像的高度和宽度。
C
是频道。显示了每个模块的输出分辨率展开和折叠操作的
步幅都为2。
BMM
代表批量矩阵乘法,其对应于等式
11
中的
W
i
→
j
x
j
。其中批量维度是
局部窗口中的空间位置的数量。ASA是
Atrous Self-Attention
的缩写。
层的多尺度查询信息,有效地提高了移动模型的性
能。
与混合了移动CNN和Transformer架构的并发轻量级
模型Mobile- Former [8]不同,我们的工作LVT仅基于
具有增强的自我注意力层的Transformer架构。trans-
former架构被证明是更有效的参数,并导致SOTA性能
的下游任务[9,32,38]。
3.
Lite Vision Transformer
我们提出了Lite Vision Transformer(LVT),如图2
所示。作为多个视觉任务的骨干网络,我们遵循标准
的四阶段设计[21,38,57]。每个阶段执行一个下采
样操作和consists的一系列的构建块。它们的输出分辨
率从步幅
-4
逐渐到步幅
-32
与以前的视觉变换器不同
[18,38,57,65],LVT提出了有限的参数和两个新的
自注意层。第一个是卷积自我注意力层,其具有
3 3
滑动核, 第一阶段。第二层是递归Atrous自注意层,
该层具有全局内核,并在最后三个阶段中采用。
3.1.
卷积自注意(CSA)
全局感受野有利于自注意层进行特征提取。然而,
卷积在视觉模型的早期阶段是首选的[16],因为局部
性在处理低级特征时更重要不同于以往
图3. 卷积自注意(CSA)在3 3本地窗口卷积和CSA的输
出是
1 1和3 3所示。 从数学上讲,卷积com-
prises prices
两个
procedures
程序:批量矩阵乘法(
BMM
)
和
求和。
BMM
对应于等式中的
Wi
-j
X
j
。(
1
)
批量维度是空间
位置的数量。CSA具有BMM操作,但具有与SA相同的求和
过程。它执行9个不同的输入相关求和,其中权重
为
等式n中
的
α
。(
2
)以颜色的方式显示的过程。
行和补丁。通过这种设计,CSA包含了可学习的过滤器和动
态内核。
结 合 卷 积 和 大 内 核 ( 全 局 ) 自 注 意 力 的 方 法 [16 ,
59],我们专注于设计一个基于窗口的自注意力层,该
层具有
3
×
3
内核并结合了卷积的表示。
剩余14页未读,继续阅读
2021-01-07 上传
2023-04-06 上传
2021-04-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-21 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
