Spark ML Pipeline:构建与理解
需积分: 18 62 浏览量
更新于2024-09-09
收藏 247KB PDF 举报
"pyspark模型训练机制之Pipline"
在机器学习领域,高效地管理和组织复杂的模型训练流程至关重要。PySpark中的Pipline机制正是为此设计的,它借鉴了scikit-learn的理念,使得在Python中使用Spark进行大规模数据处理和模型训练变得更加简洁。Pipline允许用户构建一个包含多个步骤的工作流,其中包括数据预处理、特征提取、模型训练和评估等,以实现端到端的机器学习任务。
1. 数据框(DataFrame)
DataFrame是SparkSQL的核心数据结构,它是处理多种类型数据的理想选择,如文本、特征向量、标签值和预测值。DataFrame基于RDD(Resilient Distributed Datasets)并增加了元数据,使其具备了类似传统数据库表的特性,支持结构化查询和高效计算。
2. 转换器(Transformer)
转换器是能够将一个DataFrame转换为另一个DataFrame的算法。它们通常用于数据预处理和特征工程,例如,标准化、编码类别变量或使用预训练的模型进行预测。转换器有一个`transform()`方法,该方法应用于DataFrame以产生处理后的结果。
3. 估计器(Estimator)
估计器是对DataFrame进行拟合以生成转换器的算法。这包括训练各种机器学习模型,如逻辑回归、决策树或随机森林等。估计器的`fit()`方法用于训练数据,并返回一个转换器,这个转换器可以用于实际的预测。
4. 管道(Pipeline)
管道是连接多个转换器和估计器的序列,形成一个完整的工作流程。每个阶段按照顺序执行,数据在每个阶段之间传递和转换。管道通过定义一系列操作步骤,确保了模型训练过程的清晰性和可复用性。
5. 参数(Params)
管道中的所有转换器和估计器都有一套通用的参数接口,这使得用户可以通过统一的方式调整各个组件的超参数。这种方式简化了模型调参和交叉验证的过程。
6. 工作原理
在Pipline中,数据首先通过估计器阶段,使用`fit()`方法进行训练,生成转换器;然后,转换器通过`transform()`方法作用于DataFrame,执行预测或预处理。这种流程确保了数据仅需一次性遍历整个管道,提高了效率。
7. 示例工作流
以文本处理为例,一个简单的工作流可能包括:(1)使用估计器进行文本分词;(2)使用转换器进行TF-IDF转换;(3)训练一个分类模型(如朴素贝叶斯);(4)最终的转换器用于对新数据进行预测。
总结来说,PySpark的Pipline机制为机器学习提供了强大的工具,它将复杂的模型训练过程结构化,简化了代码编写,同时也提升了性能和可维护性。通过DataFrame、Transformer、Estimator和Pipeline的组合使用,用户可以灵活地构建和管理大规模的机器学习项目。
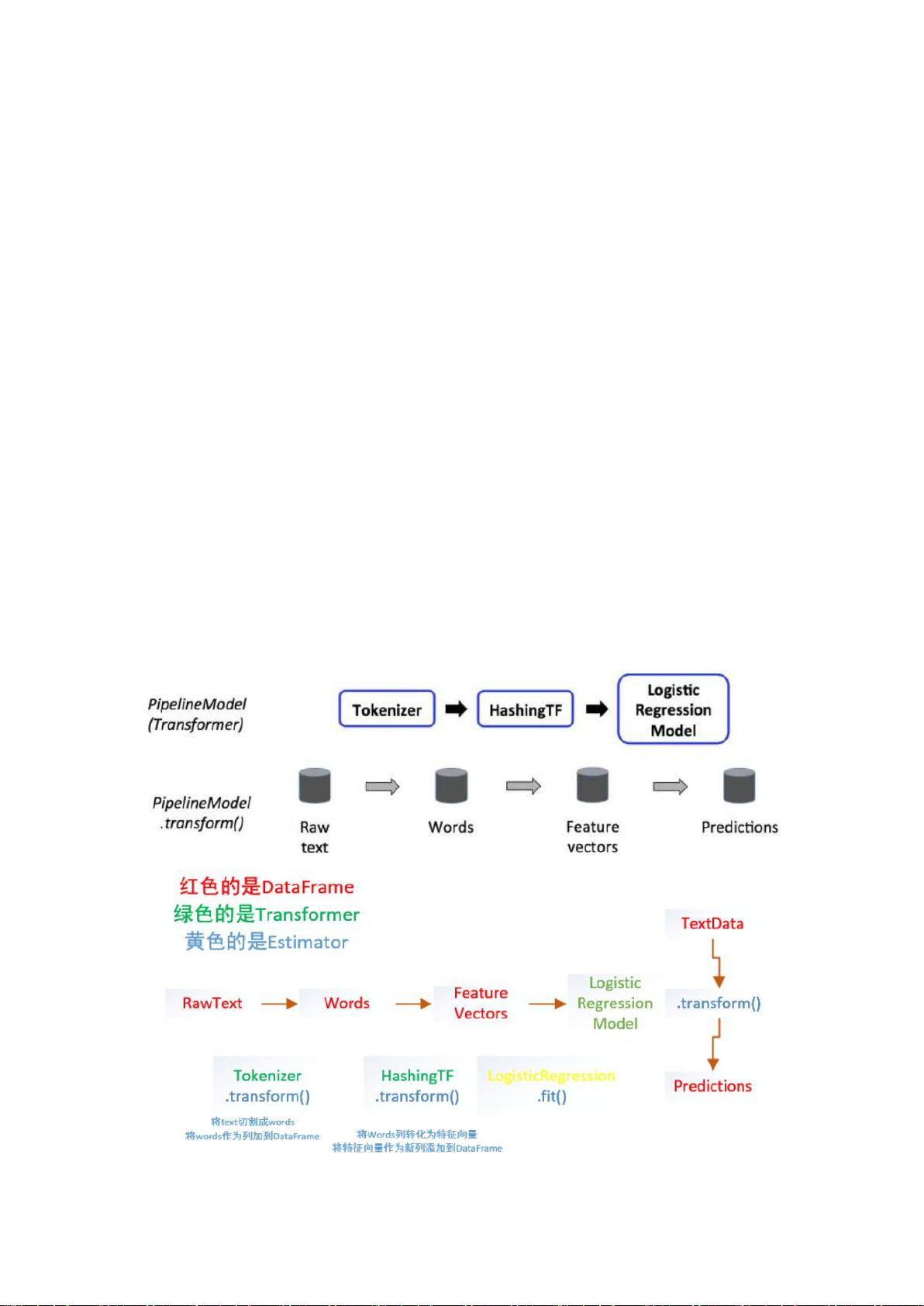
Spark ML Pipeline 的引入,是受到 scikit-learn 的启发,虽然 MLlib 已经足够简单实
用,但如果目标数据集结构复杂,需要多次处理,或是在学习过程中,要使用多个转化器
(Transformer) 和预测器 (Estimator),这种情况下使用 MLlib 将会让程序结构极其复杂。所
以,一个可用于构建复杂机器学习工作流应用的新库已经出现了,它就是 Spark 1.2 版本之
后引入的 ML Pipeline。ML Pipeline 是建立在 DataFrames 上的更高层次的 API 库,旨在
帮助使用者来创建和调试实际的机器学习工作流。
管道里的主要概念
MLlib 提供标准的接口来使联合多个算法到单个的管道或者工作流,管道的概念源于
scikit-learn 项目。
1.数据框:机器学习接口使用来自 Spark SQL 的数据框形式数据作为数据集,它可以处
理多种数据类型。比如,一个数据框可以有不同的列存储文本、特征向量、标签值和预测值。
2.转换器:转换器是将一个数据框变为另一个数据框的算法。比如,一个机器学习模型
就是一个转换器,它将带有特征数据框转为预测值数据框。
3.估计器:估计器是拟合一个数据框来产生转换器的算法。比如,一个机器学习算法就
是一个估计器,它训练一个数据框产生一个模型。
4.管道:一个管道串起多个转换器和估计器,明确一个机器学习工作流。
5.参数:管道中的所有转换器和估计器使用共同的接口来指定参数。
工作原理
管道由一系列有顺序的阶段指定,每个状态时转换器或估计器。每个状态的运行是有顺
序的,输入的数据框通过每个阶段进行改变。在转换器阶段,transform()方法被调用于数据
框上。对于估计器阶段,fit()方法被调用来产生一个转换器,然后该转换器的 transform()方
法被调用在数据框上。
下面的图说明简单的文档处理工作流的运行。
下载后可阅读完整内容,剩余3页未读,立即下载
2021-04-02 上传
2021-05-03 上传
2015-06-29 上传
2023-08-28 上传
2021-02-20 上传
2021-03-17 上传
2021-02-13 上传
2023-05-24 上传
2023-04-25 上传

h_seM
- 粉丝: 0
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
