深入理解Kafka:从安装到实战SparkStreaming
需积分: 32 125 浏览量
更新于2024-09-07
收藏 474KB DOCX 举报
"本文档主要介绍了Kafka的基本概念、作用,以及Kafka集群的安装和配置。同时,涉及了与Kafka相关的JMS规范,并探讨了Kafka在流式计算中的应用,特别是与SparkStreaming和Redis的配合使用。文档旨在帮助学习者理解Kafka的核心组件,掌握其生产者和消费者API,提升流式计算项目架构的能力。"
Kafka是Apache基金会开发的一款高性能、分布式的流处理平台,主要用于实时数据处理。它允许生产者以高吞吐量发布消息,而消费者可以以自己的速度消费这些消息。Kafka不是JMS(Java Message Service)规范的实现,但它提供了类似的功能,支持消息的发布/订阅模型。在Kafka中,数据被组织成主题(Topic),每个主题可以分为多个分区(Partition),以确保数据的并行处理。Kafka集群由多个broker组成,每个broker负责一部分主题的存储和分发,而Zookeeper则用于协调集群状态和元数据管理,确保高可用性和一致性。
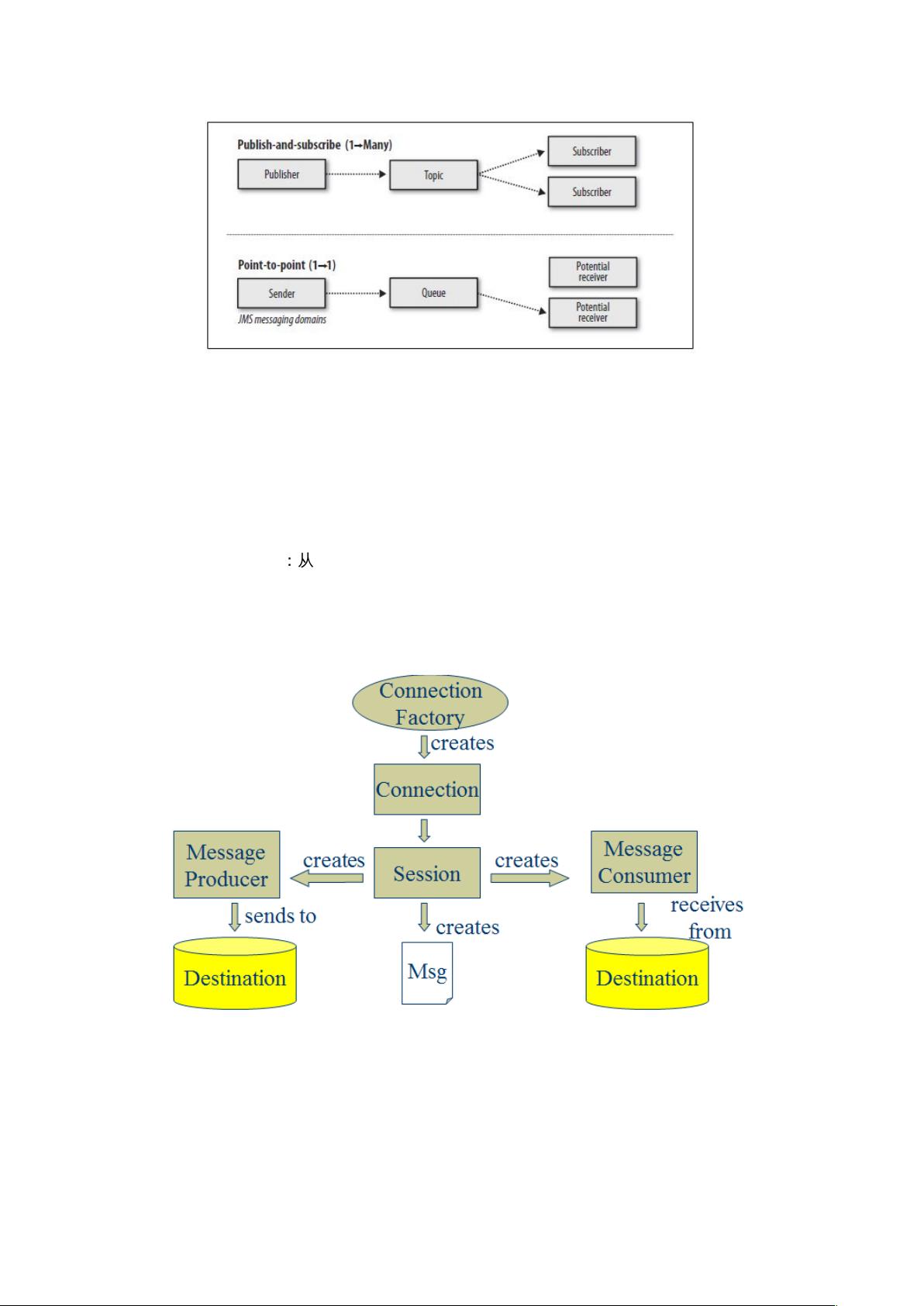
JMS,即Java消息服务,是Java中用于集成异构系统通信的一套规范。它定义了两种消息传输模型:点对点(Point-to-Point)和发布/订阅(Publish/Subscribe)。点对点模型中,消息从生产者发送到队列,由一个消费者消费后被删除;发布/订阅模型则允许多消费者订阅同一个主题,接收到消息的副本。
Kafka的安装部署通常包括以下步骤:安装Java环境,下载Kafka二进制包,配置Kafka环境变量,设置Zookeeper配置,启动Zookeeper服务,配置Kafka服务器配置文件,启动Kafka服务,创建主题,以及设置生产者和消费者参数。在集群环境中,还需要考虑broker之间的复制配置,以实现数据冗余和故障恢复。
在编程接口方面,Kafka提供了Java API,使得开发者可以方便地创建生产者和消费者。生产者API用于发布消息到指定主题,而消费者API则用于订阅主题并消费消息。在SparkStreaming中,Kafka作为上游数据源,可以实时地将数据馈送给Spark流处理任务,再结合Redis这样的内存数据库,可以构建实时数据处理和缓存系统,提高数据处理的效率和响应速度。
通过学习Kafka,不仅可以理解其在大数据实时处理中的重要角色,还可以掌握如何利用Kafka构建高效、可扩展的流处理架构,这对于现代大数据应用和实时分析系统的设计至关重要。
queue.put(object) 数据生产
queue.take(object) 数据消费
2.3、JMS 核心组件
Destination:消息发送的目的地,也就是前面说的 Queue 和 Topic。
Message :从字面上就可以看出是被发送的消息。
Producer: 消息的生产者,要发送一个消息,必须通过这个生产者来发送。
MessageConsumer: 与生产者相对应,这是消息的消费者或接收者,通过它
来接收一个消息。
通过与 ConnectionFactory 可以获得一个 connection
通过 connection 可以获得一个 session 会话。
剩余13页未读,继续阅读
2018-09-12 上传
2015-03-07 上传
2020-11-03 上传
2022-09-14 上传
2018-12-14 上传

weixin_43750942
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
