Golang map深入解析:底层实现与内存管理
107 浏览量
更新于2024-08-28
收藏 785KB PDF 举报
"Golang 语言的map是一个重要的数据结构,它在内存管理和性能优化方面有独特的实现方式。本文将探讨Golang 1.8.3版本中map的底层实现,解析其数据结构和相关机制,以解答在使用过程中可能遇到的问题。
1. 数据结构
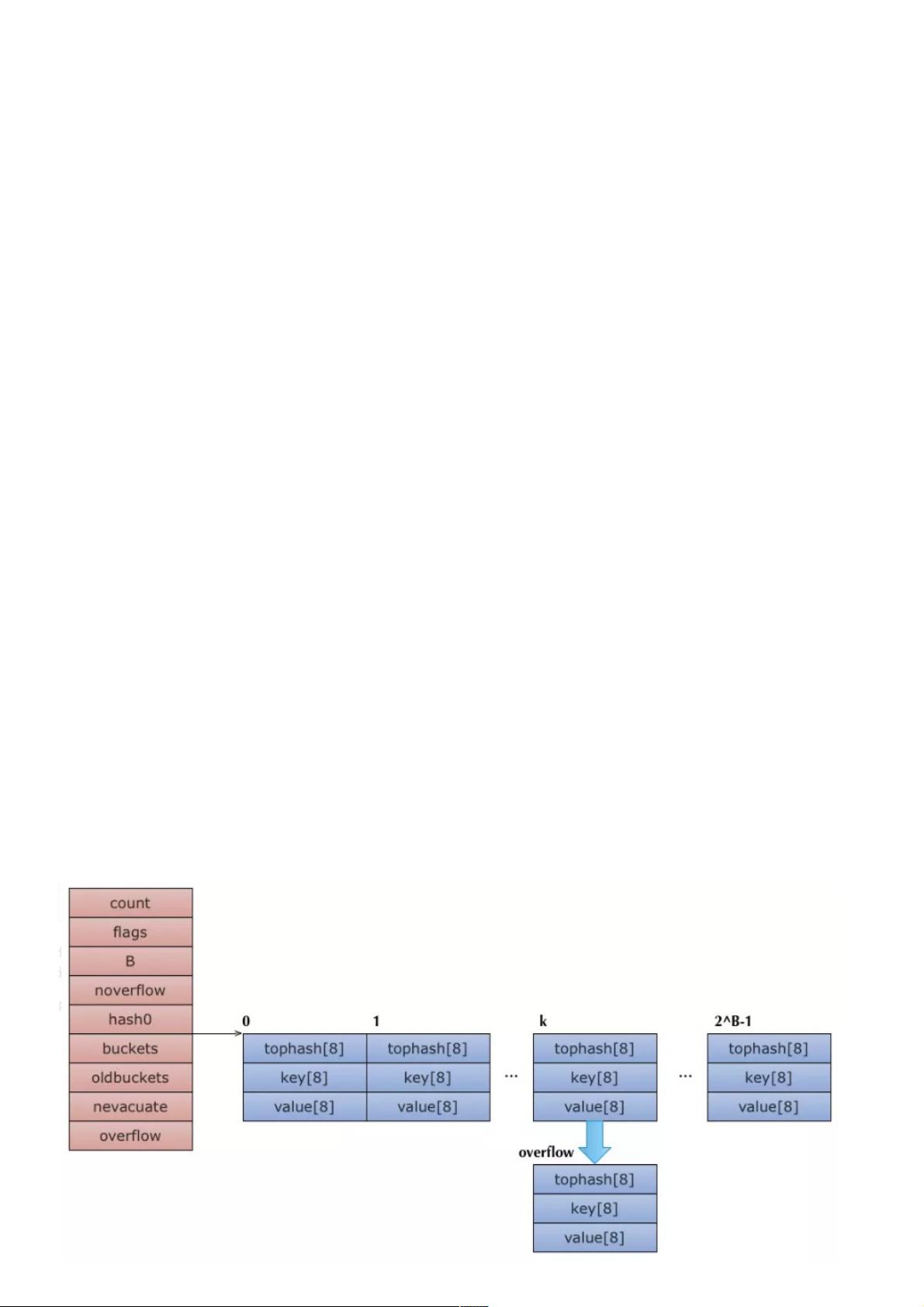
Golang中的map由`hmap`结构体表示,包含以下关键字段:
- `count`: 存储当前map中元素的数量。
- `flags`: 用于存储各种状态标志。
- `B`: 表示map的大小级别,决定了它可以存储的最大元素数量,基于装载因子6.5。
- `noverflow`: 记录溢出桶的数量。
- `hash0`: 哈希种子,用于初始化哈希函数。
- `buckets` 和 `oldbuckets`: 分别指向当前和旧的桶数组,用于扩容时的数据迁移。
- `overflow`: 指向两个溢出桶的slice,用于处理哈希冲突。
`bmap`结构体代表单个桶,包含以下元素:
- `tophash`: 用于存储每个元素哈希值的高8位,辅助快速判断是否需要进一步检查。
- 实际的key-value对:由于内存对齐的原因,key和value分开存储。
- 溢出桶的地址:当哈希冲突发生时,指向下一个桶。
2. 内存管理与扩容
- Golang的map在内存分配上采用了一种动态扩展的策略。当元素数量超过装载因子(6.5)与当前大小(2^B)的乘积时,会触发扩容。扩容不是一次性完成,而是通过增量搬迁来减少锁的竞争。
- 扩容时,新旧两组桶同时存在,新的桶容量是旧桶的两倍。旧桶中的元素逐步迁移到新桶,`nevacuate`字段跟踪搬迁进度。
- 溢出桶用于处理哈希冲突,当一个桶中的元素过多,超出8个键值对时,新的元素会被放入溢出桶中。
3. 遍历的随机性
Golang中的map遍历顺序不是固定的,这是因为遍历时会使用哈希值的低阶位来确定桶和溢出桶的访问顺序,这种设计增强了并发安全性,避免了因固定顺序导致的竞态条件。
4. 错误处理
在Golang中,你不能获取map元素的地址,因为它们可能在哈希表中移动。这就是为什么尝试`&map[key]`会导致“cannot take the address of”错误。
通过了解这些底层实现细节,开发者可以更好地理解和优化使用Golang map的情况,解决实际开发中遇到的困惑,例如理解为何无法获取map元素的地址以及遍历的非确定性行为。
Golang 语言语言map底层实现原理解析底层实现原理解析
在开发过程中,map是必不可少的数据结构,在Golang中,使用map或多或少会遇到与其他语言不一样的体验,比如访问不存在的
元素会返回其类型的空值、map的大小究竟是多少,为什么会报”cannot take the address of”错误,遍历map的随机性等等。
本文希望通过研究map的底层实现,以解答这些疑惑。
基于Golang 1.8.3
1. 数据结构及内存管理数据结构及内存管理
hashmap的定义位于 src/runtime/hashmap.go 中,首先我们看下hashmap和bucket的定义:
type hmap struct {
count int // 元素的个数
flags uint8 // 状态标志
B uint8 // 可以最多容纳 6.5 * 2 ^ B 个元素,6.5为装载因子
noverflow uint16 // 溢出的个数
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 桶的地址
oldbuckets unsafe.Pointer // 旧桶的地址,用于扩容
nevacuate uintptr // 搬迁进度,小于nevacuate的已经搬迁
overflow *[2]*[]*bmap
}
其中,overflow是一个指针,指向一个元素个数为2的数组,数组的类型是一个指针,指向一个slice,slice的元素是桶(bmap)的地
址,这些桶都是溢出桶;为什么有两个?因为Go map在hash冲突过多时,会发生扩容操作,为了不全量搬迁数据,使用了增量搬
迁,[0]表示当前使用的溢出桶集合,[1]是在发生扩容时,保存了旧的溢出桶集合;overflow存在的意义在于防止溢出桶被gc。
// A bucket for a Go map.
type bmap struct {
// 每个元素hash值的高8位,如果tophash[0] < minTopHash,表示这个桶的搬迁状态
tophash [bucketCnt]uint8
// 接下来是8个key、8个value,但是我们不能直接看到;为了优化对齐,go采用了key放在一起,value放在一起的存储方式,
// 再接下来是hash冲突发生时,下一个溢出桶的地址
}
tophash的存在是为了快速试错,毕竟只有8位,比较起来会快一点。
从定义可以看出,不同于STL中map以红黑树实现的方式,Golang采用了HashTable的实现,解决冲突采用的是链地址法。也就是
说,使用数组+链表来实现map。特别的,对于一个key,几个比较重要的计算公式为:
key hash hashtop bucket index
key
hash := alg.hash(key,
uintptr(h.hash0))
top := uint8(hash >> (sys.PtrSize*8 –
8))
bucket := hash & (uintptr(1)<<h.B – 1),即 hash %
2^B
例如,对于B = 3,当hash(key) = 4时, hashtop = 0, bucket = 4,当hash(key) = 20时,hashtop = 0, bucket = 4;这个例子我
们在搬迁过程还会用到。
内存布局类似于这样:
下载后可阅读完整内容,剩余9页未读,立即下载
2024-05-25 上传
2020-09-20 上传
2023-05-21 上传
2023-07-18 上传
2022-06-29 上传
2024-06-16 上传
2022-08-03 上传

weixin_38526208
- 粉丝: 3
- 资源: 939
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
