MeanShift算法详解:从概念到应用
下载需积分: 10 | PDF格式 | 756KB |
更新于2024-07-29
| 39 浏览量 | 举报
"这篇文档是关于Mean Shift算法的概述,介绍了Mean Shift的起源、发展、核心思想、应用领域以及在图像处理和跟踪问题中的实际应用。文中提到了关键人物如Fukunaga、Yizong Cheng和Comaniciu的工作,并阐述了Mean Shift算法的收敛性和在概率密度函数模式检测中的作用。"
Mean Shift是一种非参数机器学习方法,主要用于数据聚类、图像平滑和分割、物体跟踪等领域。该算法的核心在于通过迭代找到数据分布的局部峰值,这些峰值通常对应着数据集中的类别中心或高密度区域。
Mean Shift最初由Fukunaga在1975年提出,最初是一个向量概念,表示数据点的均值移动。随着时间的推移,Mean Shift演变成一个迭代过程,每次迭代都会将数据点移动到其邻域内数据密度更高的位置,直到达到稳定状态或满足预设的停止条件。
Yizong Cheng在1995年的文献中扩展了Mean Shift,引入了核函数和权重系数,使算法能处理不同距离和重要性的样本,增加了算法的灵活性和适应性。他还指出Mean Shift在模式识别和图像处理中的潜在应用。
Comaniciu等人进一步发展了Mean Shift在特征空间的应用,特别是在图像处理中的应用,如图像平滑和分割。他们证明了在特定条件下,Mean Shift算法能够收敛到概率密度函数的局部最大值,这使得它成为寻找数据集模式的有效工具。
此外,Mean Shift也被应用于非刚体跟踪问题,通过将其转化为最优化问题,实现高效的实时跟踪。在算法步骤上,Mean Shift涉及计算每个点的密度梯度,更新点的位置,直至达到收敛。
Mean Shift算法通过迭代地移动数据点,寻找数据分布的局部峰点,从而揭示数据内在的结构。它的灵活性、适应性和在多种领域的应用,使其成为解决复杂数据分析问题的重要工具。尽管Mean Shift是非监督的,但其在聚类任务中的表现,以及在处理高维数据和实时跟踪上的能力,使其在机器学习和计算机视觉领域有着广泛的应用。
2
()K x k x
(3)
并且满足:
(1)
k
是非负的.
(2)
k
是非增的,即如果
ab
那么
( ) ( )k a k b
.
(3)
k
是分段连续的,并且
0
()k r dr
那么,函数
()Kx
就被称为核函数.
举例:在 Mean Shift 中,有两类核函数经常用到,他们分别是,
单位均匀核函数:
1 if 1
()
0 if 1
x
Fx
x
(4)
单位高斯核函数:
2
()
x
N x e
(5)
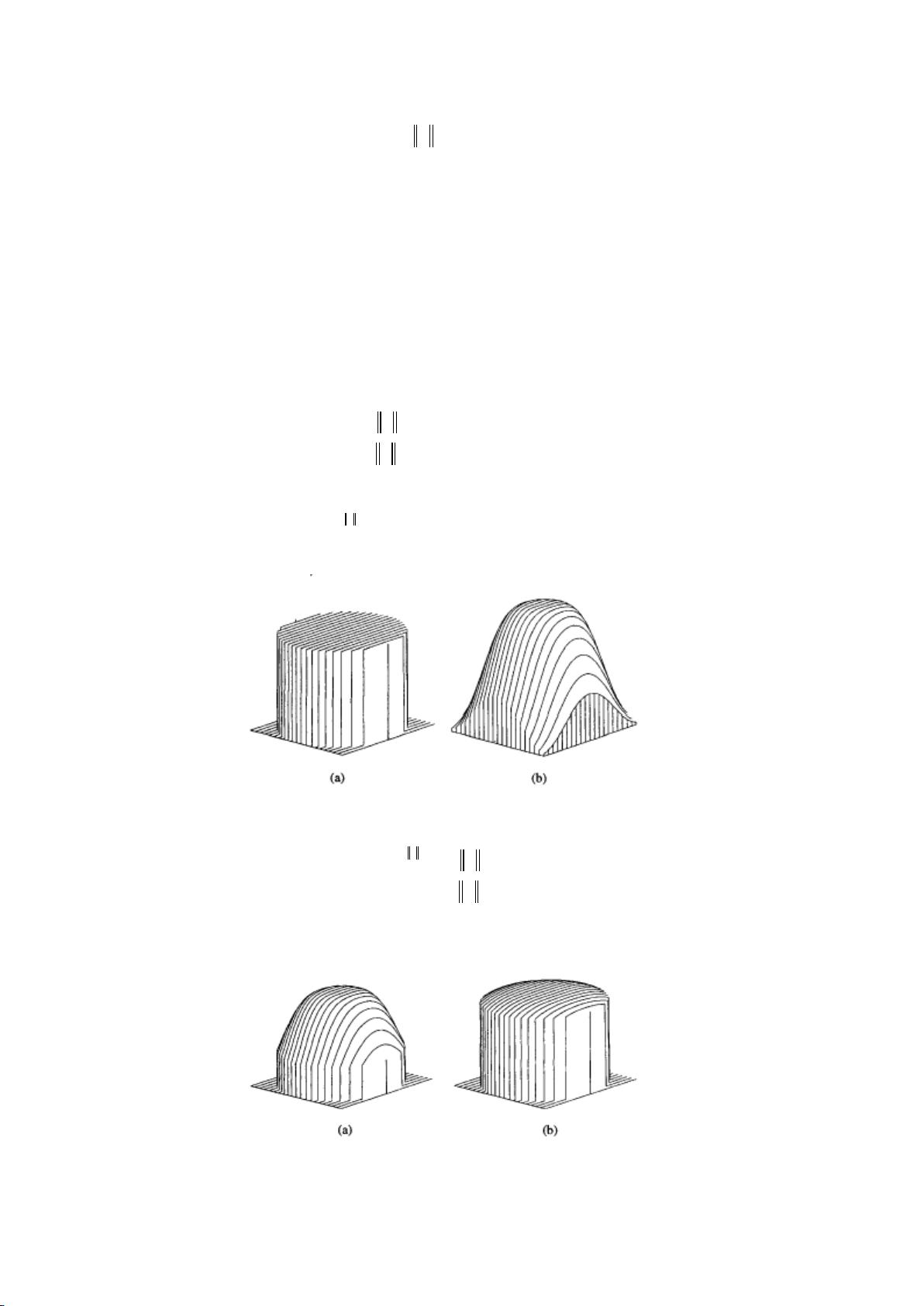
这两类核函数如下图所示.
图 2, (a) 单位均匀核函数 (b) 单位高斯核函数
一个核函数可以与一个均匀核函数相乘而截尾,如一个截尾的高斯核函数为,
2
if
()
0 if
x
ex
N F x
x
(6)
图 3 显示了不同的
,
值所对应的截尾高斯核函数的示意图.
图 3 截尾高斯核函数 (a)
1
1
NF
(b)
0.1
1
NF
剩余14页未读,继续阅读
相关推荐





wj31520110154099
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 普天身份证阅读器新版二次开发包发布
- C# 实现文件的数据库保存与导出操作
- CkEditor增强功能:轻松实现图片上传
- 掌握DLL注入技术:测试工具使用与探索
- 实现带节假日农历功能的jQuery日历选择器
- Spring循环依赖示例:深入理解与Git代码仓库实践
- ABB PLC液压阀门控制程序开发指南
- 揭秘4核旋风密版626象棋引擎的超牛实力
- HTML5实现的经典游戏:小霸王坦克大战源码分享
- 让Visual Studio兼容APM硬件信息的方法
- Kotlin入门:创建我的第一个应用
- Android语音识别技术研究报告与应用分析
- 掌握JavaScript基础:第8版教程源代码解析
- jQuery制作动态侧面浮动图片广告特效教程
- Android PinView仿支付宝密码输入框源码分析
- HTML5 Canvas制作的围住神经猫游戏源码分享
