疫情分析系统设计:基于Elastic Stack的Python Scrapy爬虫实践
版权申诉
88 浏览量
更新于2024-06-21
收藏 2.85MB DOCX 举报
"基于Elastic Stack平台的疫情分析系统的设计与实现-数据获取模块.docx"
本文档主要讨论了如何利用Elastic Stack平台构建一个疫情分析系统,特别关注数据获取模块,该模块使用Python的Scrapy框架来抓取和处理疫情相关的实时数据。系统设计的背景是2020年全球爆发的新型冠状病毒疫情,强调了准确、及时的信息获取在疫情防控中的重要性,以及对抗网络谣言以避免公众恐慌的必要性。
在设计这个疫情分析系统时,数据获取模块扮演了核心角色。Scrapy是一个强大的、灵活的爬虫框架,用于高效地抓取大规模网页数据。系统采用了两种不同的抓取策略来适应不同类型的网站:
1. 对于那些在客户端持续更新、只有一个页面的网站,采用单机爬虫进行定时采集。这种方式下,爬虫按照设定的时间间隔访问页面,提取新数据,确保数据的实时性。
2. 对于频繁更新并产生新URL、涉及多页面抓取的大型网站,系统使用分布式爬虫。分布式爬虫可以分发任务到多个节点,提高数据采集的速度和效率,尤其适合处理数据量大的情况。
Elastic Stack,又称为ELK(Elasticsearch, Logstash, Kibana),是一组开源工具,常用于日志管理和数据分析。在这个疫情分析系统中,Elasticsearch可能用于存储和索引爬取的疫情数据,Logstash用于数据清洗和转换,而Kibana则用于数据的可视化,帮助用户直观地查看和理解疫情的发展趋势。
关键词:互联网;疫情数据;分布式;Scrapy。这些关键词表明了系统的组成部分和技术选型,显示了利用现代技术和开源工具解决公共卫生问题的能力。
整个系统的目标是提供一个真实的疫情信息平台,通过实时数据更新和可视化,帮助公众了解疫情动态,识别虚假信息,从而减少因恐慌引起的不良社会影响。通过这样的系统,用户可以及时获取准确的疫情信息,为个人防护和决策提供支持。
在实现过程中,开发者需要注意处理网页的反爬策略,如IP限制、User-Agent切换等,同时确保爬虫行为的合法性和合规性。此外,数据的预处理、清洗和标准化也是关键步骤,以确保分析结果的准确性和可靠性。
这个基于Elastic Stack的疫情分析系统利用Scrapy爬虫框架获取和处理数据,结合分布式爬虫技术处理大量信息,旨在构建一个高效、实时的疫情信息平台,助力疫情防控工作。
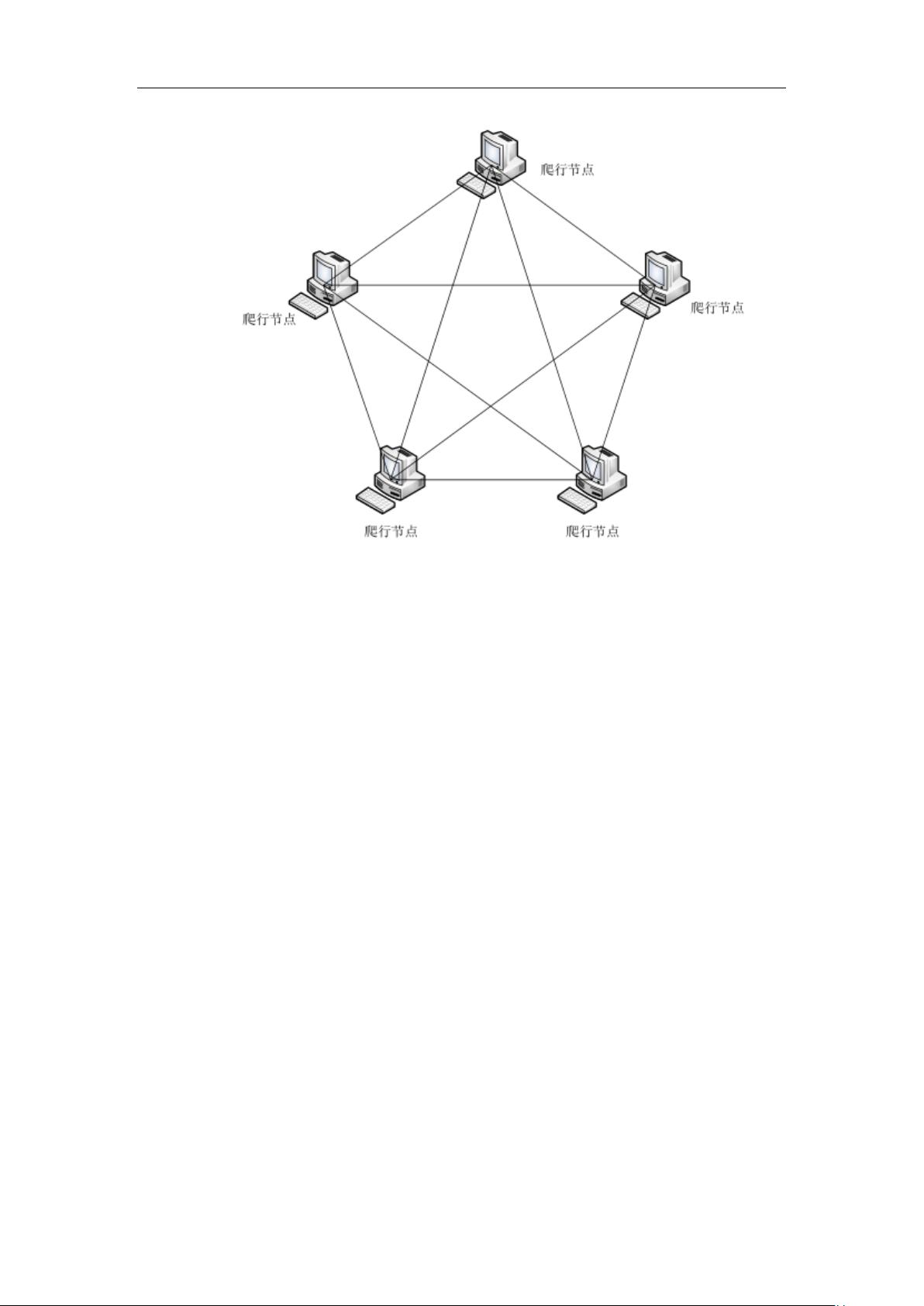
4
图 2-2 对等式架构图
2.3 Scrapy 框架的研究
写一个网络爬虫的时候,我们经常需要做一些重复的操作,比如发送请求,
处理请求队列,请求调度等等。如果我们每次写一个爬虫都要完成这些重复的操
作,那么就比较浪费时间,而 scrapy 框架把一些基础的操作都封装好了,使用
scrapy 框架开发,可以提高我们编写爬虫的效率。
2.3.1 Scrapy 框架结构
Scrapy 框架 主 要由 Spider (爬虫 )、 Downloader (下载 器 )、Scrapy
Engine(引擎)、Scheduler(调度器)、Item Pipeline(数据管道)这 5 个部分
组成,图 2-3 展示了 Scrapy 的框架结构。
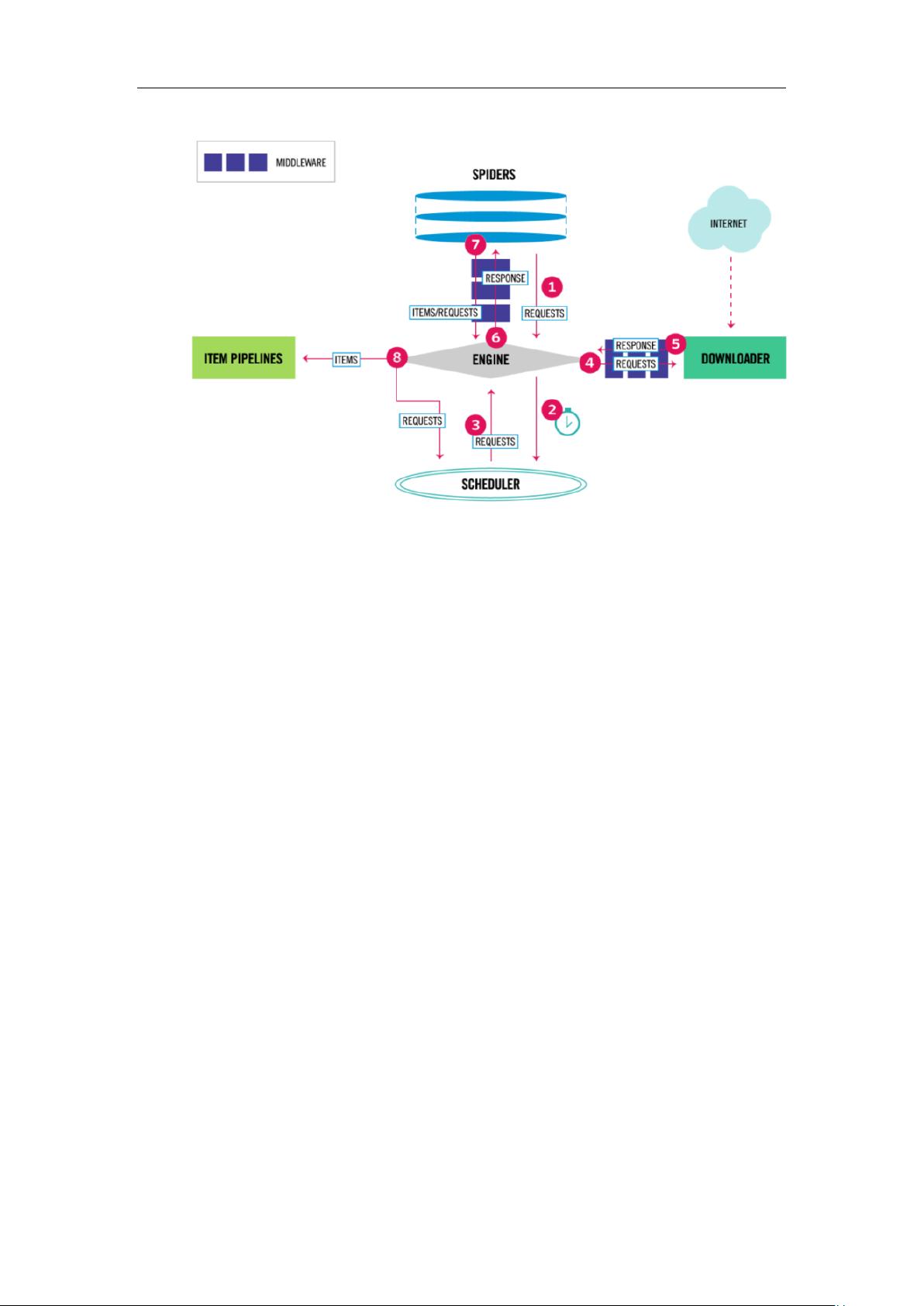
剩余40页未读,继续阅读
2020-11-03 上传
2024-01-29 上传
2023-07-27 上传
2023-11-03 上传
2023-06-26 上传
2023-08-29 上传
2023-08-09 上传
2023-03-25 上传
2024-01-24 上传

南抖北快东卫
- 粉丝: 78
- 资源: 5587
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
