统计视角下的提升算法:正则化、预测与模型拟合
版权申诉
54 浏览量
更新于2024-07-05
收藏 871KB PDF 举报
"提升算法:正则化、预测与模型拟合"
本文主要探讨了提升算法在统计学中的应用,特别是从统计学的角度出发,重点在于估计可能复杂的参数或非参数模型,包括广义线性模型、加性模型以及生存分析的回归模型。作者Peter B¨uhlmann和Torsten Hothorn分别来自ETH Zurich和Universit¨at Erlangen-N¨urnberg。
提升算法,如AdaBoost(Adaptive Boosting),最初是由Freund和Schapire提出的分类算法,它通过组合弱学习器形成强学习器,显著提高了分类性能。文章指出,提升算法不仅限于分类任务,也适用于回归和预测问题。在高维特征空间中,提升算法对于正则化和变量选择具有重要价值,因为它们可以有效地处理过拟合问题。
文章讨论了自由度的概念,这是评估模型复杂性和进行正则化的重要工具。自由度与Akaiki信息准则(AIC)和贝叶斯信息准则(BIC)紧密相关,这些准则常用于在模型选择中平衡模型复杂度和预测能力。在高维度数据中,这些准则有助于控制模型的复杂性,防止过度拟合。
`mboost`是一个专门为此目的开发的开源软件包,它实现了用于模型拟合、预测和变量选择的函数。这个包的灵活性允许用户自定义损失函数,实现新的提升算法,从而适应各种不同的学习任务。
此外,文章还深入探讨了提升算法的实践方面,包括如何通过迭代过程优化模型,如何调整学习率和迭代次数以达到最佳性能,以及如何利用提升算法的特性来处理非平衡数据集。通过对实际数据集的应用,展示了提升算法的有效性和实用性。
总结起来,这篇文章提供了一个全面的统计视角,深入解析了提升算法在模型拟合、预测和正则化中的作用,强调了其在高维数据环境中的优势,并通过`mboost`软件包展示了其实用方法,对于理解和应用提升算法在机器学习和人工智能领域具有重要参考价值。

BOOSTING ALGORITHMS AND MODEL FITTING 9
The population minimizer can be shown to be [33, cf.]
f
∗
log-lik
(x) =
1
2
log
p(x)
1 − p(x)
, p(x) = P[Y = 1|X = x].
The loss function in (3.1) is a function of ˜yf, the so-called margin value,
where the function f induces the following classifier for Y :
C(x) =
1 if f(x) > 0
0 if f(x) < 0
undetermined if f(x) = 0.
Therefore, a misclassification (including the undetermined case) happens if
and only if
˜
Y f(X) ≤ 0. Hence, the misclassification loss is
ρ
0-1
(y, f) = I
{˜yf≤0}
,(3.2)
whose population minimizer is equivalent to the Bayes classifier (for
˜
Y ∈
{−1, +1})
f
∗
0-1
(x) =
(
+1 if p(x) > 1/2
−1 if p(x) ≤ 1/2,
where p(x) = P[Y = 1|X = x]. Note that the 0-1 loss in (3.2) cannot be
used for boosting or FGD: it is non-differentiable and also non-convex as
a function of the margin value ˜yf. The negative log-likelihood loss in (3.1)
can be viewed as a convex upp er approximation of the (computationally
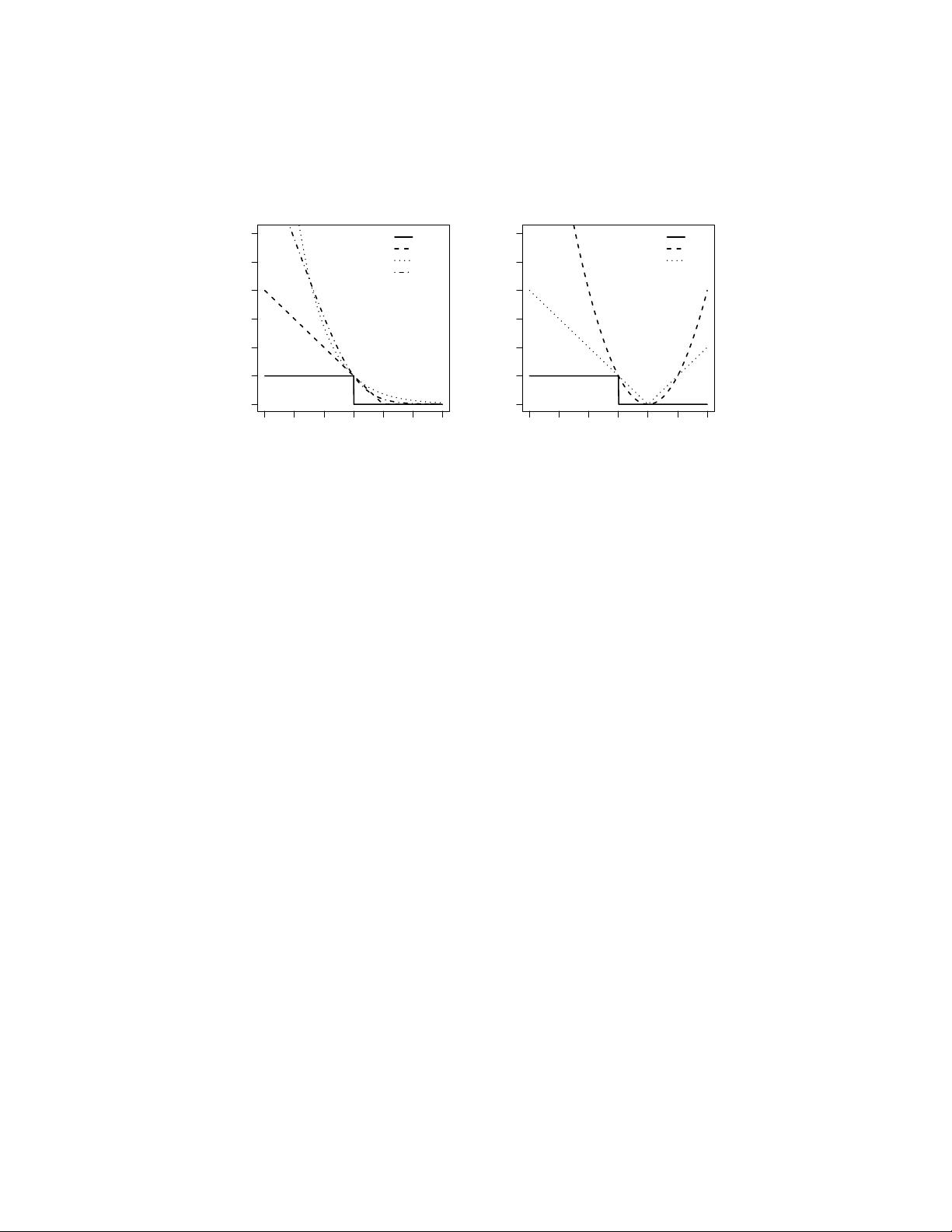
intractable) non-convex 0-1 loss, see Figure 1. We will describe in Section 3.3
the BinomialBoosting algorithm (similar to LogitBoost [33]) which uses the
negative log-likelihood as loss function (i.e. the surrogate loss which is the
implementing loss function for the algorithm).
Another upper convex approximation of the 0-1 loss function in (3.2) is
the exponential loss
ρ
exp
(y, f) = exp(−˜yf),(3.3)
implemented (with notation y ∈ {−1, +1}) in mboost as AdaExp() family.
The population minimizer can be shown to be the same as for the log-
likelihood loss [33, cf.]:
f
∗
exp
(x) =
1
2
log
p(x)
1 − p(x)
, p(x) = P[Y = 1|X = x].
imsart-sts ver. 2005/10/19 file: BuehlmannHothorn_Boosting.tex date: June 4, 2007

剩余51页未读,继续阅读
2014-01-14 上传
2017-06-03 上传
2023-06-05 上传
2024-08-13 上传
2020-07-31 上传
2019-09-10 上传
2019-09-12 上传
2022-11-28 上传
2021-09-19 上传


应用市场
- 粉丝: 943
- 资源: 4246
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
