TensorFlow数据读取深度解析:十图+代码详解
186 浏览量
更新于2024-09-04
收藏 497KB PDF 举报
本文主要讲解了TensorFlow中的数据读取机制,通过图文并茂的方式帮助读者理解和掌握这一复杂过程。文章首先阐述了数据读取的基本概念,比如以图像数据为例,指出数据读取是从硬盘中获取数据,将其加载到内存以便GPU或CPU进行计算。然而,由于读取速度通常慢于计算,可能导致运算效率低下,因此通过并发处理来解决这个问题,即使用两个线程,一个负责读取,一个负责计算,形成一个内存队列。
文章特别提到了TensorFlow中引入的"文件名队列"这一层,其目的是为了更好地管理数据集的迭代。在机器学习中,一个epoch指的是数据集中的所有样本被处理一次。文件名队列确保在每个epoch开始时,按照一定的顺序将文件名加入队列,这样在执行计算时,可以保证数据的一致性和重复性。
通过一张图示,作者解释了文件名队列和内存队列的协同工作流程。例如,对于包含A.jpg、B.jpg、C.jpg的简单数据集,一个epoch的处理会将这三个文件依次放入文件名队列,然后数据读取线程将它们逐个读取到内存队列中。这样,当计算线程需要数据时,可以从内存队列中直接获取,避免了因为I/O操作导致的计算暂停,从而提高了整体的计算效率。
为了方便读者进一步实践,文章还提供了相关的代码示例,使得理论知识和实际操作相结合,有助于读者在学习过程中更好地理解和应用TensorFlow的数据读取机制。本文是一篇实用性很强的教程,适合那些在学习TensorFlow过程中对数据读取机制感到困惑的开发者。
用十张图详解用十张图详解TensorFlow数据读取机制(附代码)数据读取机制(附代码)
主要介绍了用十张图详解TensorFlow数据读取机制(附代码),小编觉得挺不错的,现在分享给大家,也给大
家做个参考。一起跟随小编过来看看吧
在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解。确实这一块官方的教程比较简略,网上也找不到
什么合适的学习材料。今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下TensorFlow的数据读取机制,
文章的最后还会给出实战代码以供参考。
TensorFlow读取机制图解读取机制图解
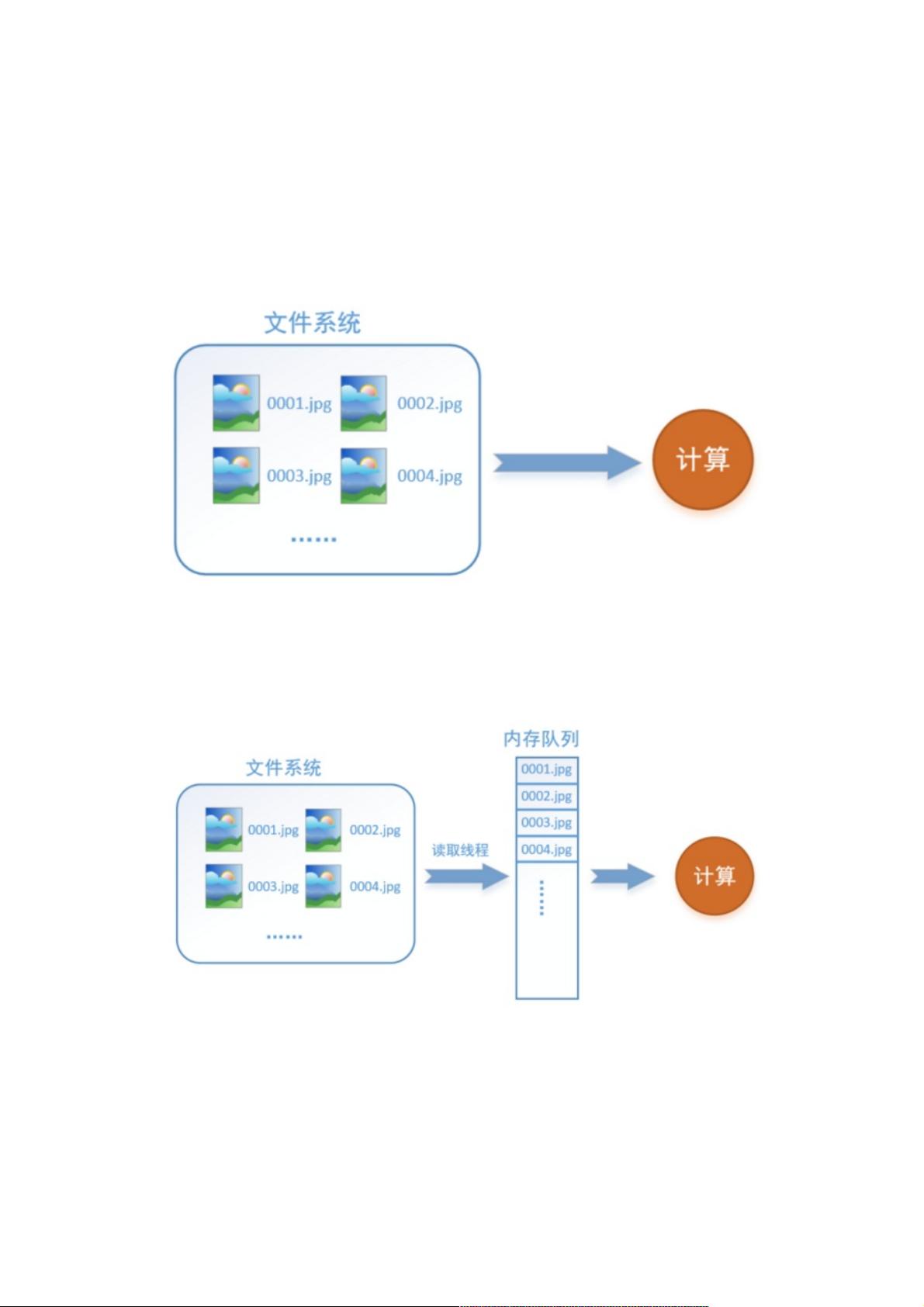
首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示:
假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或
是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,
假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内
存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在TensorFlow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就
是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、
C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两
遍。
TensorFlow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面我们用图片的形式来说明这个机
制的运行方式。如下图,还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么我们就在文件名队列中把A、
B、C各放入一次,并在之后标注队列结束。
下载后可阅读完整内容,剩余5页未读,立即下载
2012-05-08 上传
点击了解资源详情
2021-01-12 上传
2022-01-03 上传
2023-11-17 上传
2023-12-05 上传
2018-01-10 上传

weixin_38632763
- 粉丝: 7
- 资源: 944
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
