汇编语言:多字节数据存储顺序与不同字量格式详解
版权申诉
183 浏览量
更新于2024-07-06
收藏 481KB PDF 举报
本资源主要讨论了汇编语言程序设计中的多字节数据存储顺序,针对字节、字、双字等不同数据类型在主存储器中的组织方式。汇编语言中,最小的存储单位是二进制位(比特位),而最常用的存储单位是字节,由8个二进制位组成。数据在内存中是以字节为单位进行存储和访问的,每个存储单元对应一个唯一的地址。
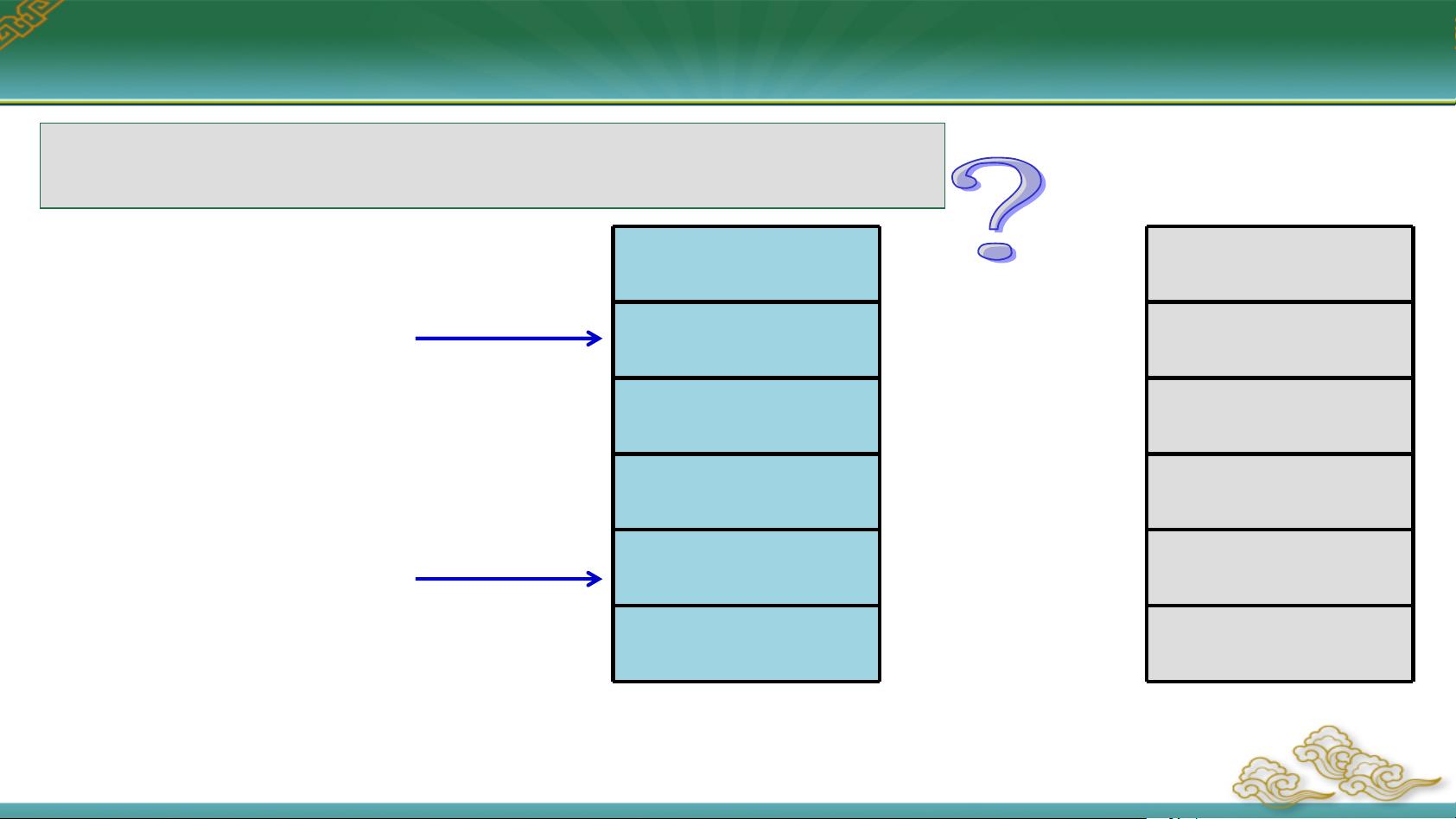
对于单字节的数据类型,如byte,如`byte39h,31h,32h,38h`,这些数据会按照低地址到高地址的顺序依次存储。对于多字节的数据类型,例如字(word)和双字(dword),存储顺序更为复杂。字通常包含两个字节,存储时可能遵循大端(BigEndian)或小端(LittleEndian)方式。小端方式中,高字节存储在低地址,低字节存储在高地址;相反,大端方式则反之。
例如,双字`dword38323139h`在小端方式下,字节顺序为39H、38H、32H、31H,而在大端方式下则是39H、31H、32H、38H。在80x86架构中,由于采用的是小端方式,内存地址`00405090H`对应的数据依次是字节39H、字节3139H和双字38323139H。
此外,这个文档还强调了主存储器的字节编址方式,即每个存储单元只存放一个字节的数据,这对于理解程序的内存布局和数据操作至关重要。理解多字节数据的存储顺序对于编写高效、正确的汇编程序以及与不同体系结构的兼容性至关重要。
总结来说,本资源深入讲解了汇编语言编程中涉及的内存结构和数据组织原则,特别是针对多字节数据在不同类型的存储单元(如字节、字和双字)中的存储顺序,这对于程序员理解和操作计算机内存具有实际指导意义。
剩余29页未读,继续阅读
2022-01-10 上传
2022-01-10 上传
2023-08-21 上传
2023-08-22 上传
2023-12-31 上传
2023-06-21 上传
2023-07-02 上传
2023-06-21 上传
2023-07-05 上传

念广隶
- 粉丝: 4w+
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
