HBase存储机制解析:从LSM树到高并发优化
需积分: 1 8 浏览量
更新于2024-06-15
收藏 3.28MB DOCX 举报
“Hbase.docx”讨论了HBase的高并发读写优化,特别是与LSM树相关的存储机制。文章对比了哈希存储引擎、B树存储引擎(以B+树为例)和LSM树存储引擎,分析了它们在数据操作和性能上的差异。
HBase是一种基于Google Bigtable理念设计的分布式、列式存储系统,适用于处理大规模数据。在HBase中,LSM树(Log-Structured Merge Tree)是其存储模型的核心,它优化了写入性能,尤其适合高并发场景。
哈希存储引擎提供快速的增删改查操作,具有O(1)的时间复杂度,但不支持顺序扫描。而B+树则提供了顺序扫描能力,适合关系型数据库,如MySQL,但频繁的插入操作可能导致随机IO,影响性能。
LSM树结合了两者的优点,它通过批量写入磁盘来减少随机IO,提升了写入速度。在内存中,LSM树分为多个小树,当达到一定大小后,这些小树被刷入磁盘。在读取时,可能需要合并磁盘上的历史数据和内存中的最新修改,因此读性能相对较低。LSM树的这种设计使得HBase在写入性能上相对于使用B+树的数据库如MySQL有显著优势,但在读取性能上略逊一筹。
HBase的LSM树存储机制包括以下几个关键组件:
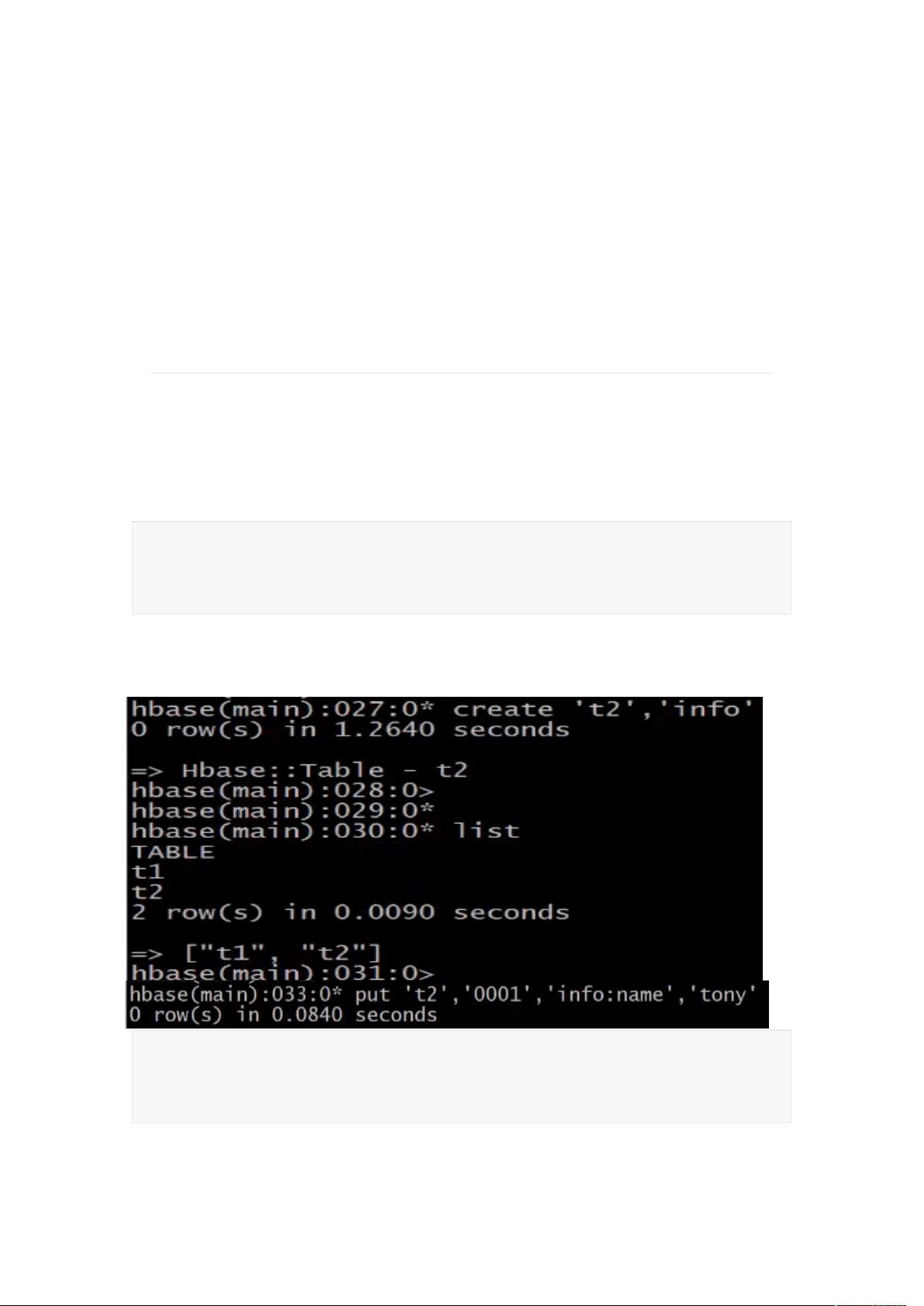
1. MemStore:内存中的数据结构,负责接收新的写入操作。当达到预设阈值时,MemStore的内容会被写入到硬盘。
2. HFile:磁盘上的数据文件,是HBase的基本存储单元,包含一系列排序的Key-Value对。
3. Compaction:定期合并磁盘上的多个HFile,以减少读取时需要检查的文件数量,优化读性能。
4. Bloom Filter:一种空间效率高的概率数据结构,用于判断一个元素是否可能存在集合中,减少不必要的磁盘访问。
5. Region Split:当Region(HBase的分区概念)变得过大时,会被自动分割,以维持系统的水平扩展性和性能。
通过这些组件的协同工作,HBase能够有效地处理大规模、高并发的数据写入和查询,尤其是在大数据分析和实时数据处理场景下表现出色。然而,由于其优化写入的特性,对于需要频繁进行顺序扫描或读取性能要求极高的应用,可能需要寻找更适合的解决方案。
也称为 WAL 意为 Write ahead log,类似 mysql 中的 binlog,用来做灾难恢复时用,HLog
记录数据的所有变更,一旦数据修改,就可以从 log 中进行恢复。
备注 2:
MemStore 是数据块中的一个内存区域,它可以提升写出数据的效率,新增和更新的数据
写入 MemStore,然后再由 MemStore 写入磁盘。当客户端收到一个 Put 请求时会先查
询 hbase:meta 元数据来定位将要写入的数据 Region 位置,具体操作细节会交给 Region
实体来完成。
1. 先写入 WriteAheadLog(WAL)日志中,它记录数据操作整个流程,WAL 是写入 HDFS 集
群文件系统上,一旦写入动作失败,可以从 WAL 恢复过来,默认参数 writeToWAL 为
true,意思是数据会先写入 WAL 日志;
然后才写入 MemStore 内存块中,MemStore 内存如果满了,才会刷新写入本地磁盘的
StoreFile 上。刷新是由独立的 RegionServer 线程来完成的。注意 MemStore 只会在内存
区域存在的,如果数据写入了 MemStore,但还没有来得及写入磁盘已经崩溃,此时数
据便会丢失。
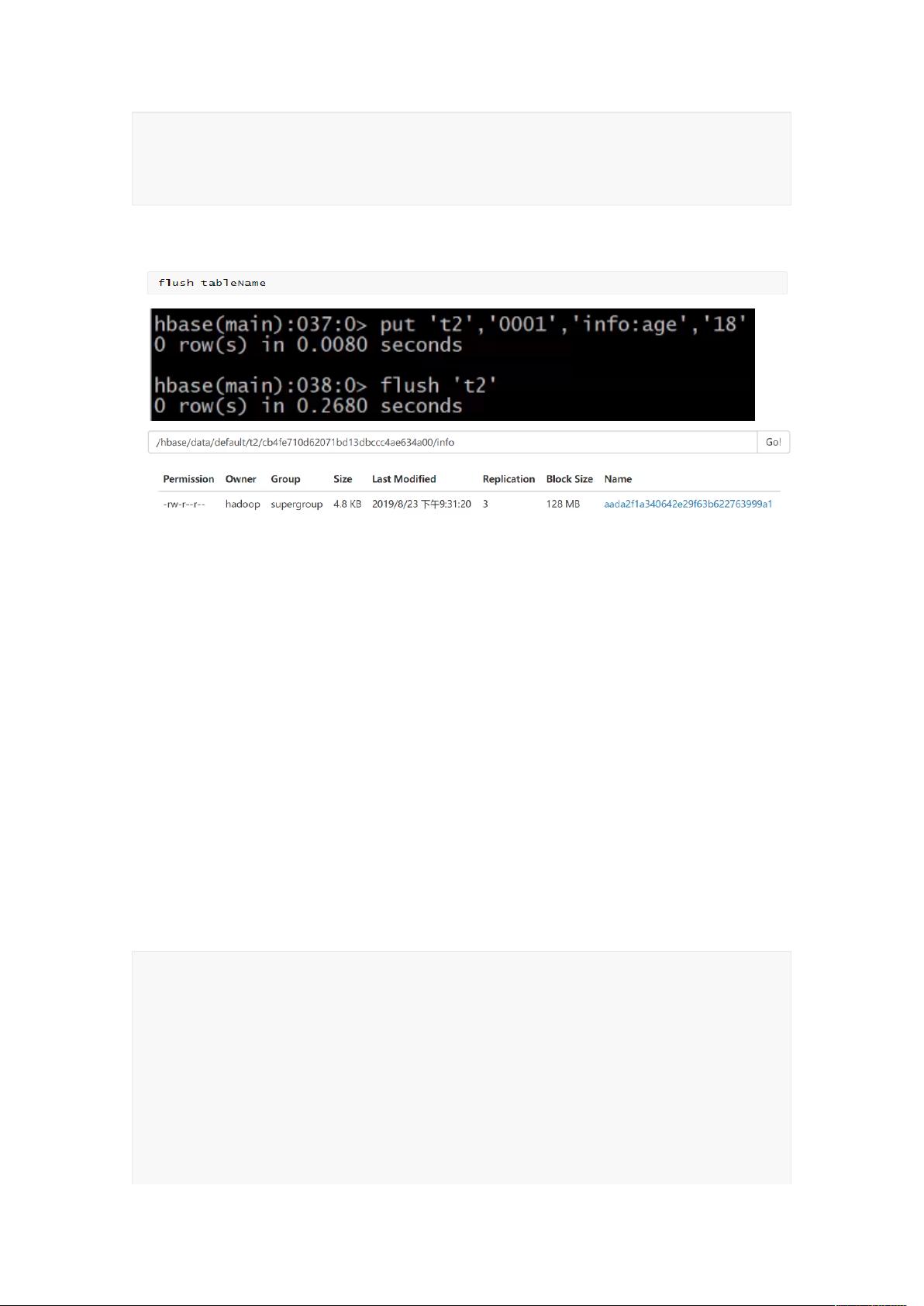
Flush 机制-M
� (1)当 memstore 的大小超过这个值的时候,会 flush 到磁盘,默认为 128M
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
� (2)当 memstore 中的数据时间超过 1 小时,会 flush 到磁盘
<property>
<name>hbase.regionserver.optionalcacheflushinterval</name>
<value>3600000</value>
</property>
� (3)HregionServer 的全局 memstore 的大小,超过该大小会触发 flush 到磁
盘的操作,默认是堆大小的 40%
剩余50页未读,继续阅读
127 浏览量
156 浏览量
938 浏览量
283 浏览量
122 浏览量
2020-02-24 上传
224 浏览量

大数据侠客
- 粉丝: 734
- 资源: 76
 我的内容管理
展开
我的内容管理
展开







最新资源
- 易语言BASS音乐盒
- Draft 2020-10-26 09:34:16-数据集
- Мотолькулятор-crx插件
- 作品答辩PPT指导模版.rar
- Dockboard-开源
- nativescript-fb-analytics:轻量级NativeScript插件,可将Facebook Analytics添加到iOS和Android应用程序
- 视频商店:Guia Objetos IV
- NotNews!-crx插件
- 易语言Beep卡农
- SFE_CC3000_Library:用于 TI CC3000 WiFi 模块的 Arduino 库
- FogPlacementWithSelfLearning
- mpu6050_姿态传感器_姿态解算_TI_
- Unfixed google search form-crx插件
- lipyd:用于脂质组学LC MSMS数据分析的Python模块
- java图书管理系统实现代码
- nativescript-disable-bitcode:禁用CocoaPods位码的NativeScript插件
