预训练模型演进:从词嵌入到BERT的深度探索
49 浏览量
更新于2024-08-03
收藏 309KB DOCX 举报
"自然语言预训练模型大总结"
自然语言预训练模型是当前人工智能领域,尤其是自然语言处理(NLP)中的热门研究方向。这些模型通过在大规模未标注文本数据上进行预训练,学习到通用的语言表示,然后在特定任务上进行微调,以提升模型在下游任务的性能。预训练模型的发展极大地推动了NLP的进步,如机器翻译、问答系统、情感分析等领域的应用。
预训练模型的主要优点包括:
1. 学习通用语言表示:在大量数据上预训练可以帮助模型捕捉语言的普遍规律,为各种NLP任务提供强有力的起点。
2. 提高模型初始化质量:预训练模型的参数能更好地适应目标任务,加速训练过程,提高泛化能力。
3. 正则化效果:通过预训练,模型能避免在小数据集上过拟合,增强模型的稳定性。
按照网络深度表示方法,预训练模型可划分为两代:
1. 词嵌入(Embedding):如word2vec、paragraph vector等,它们是静态的、浅层的模型,无法处理多义词和未知词汇问题。
2. 深度模型:包括LSTM、ELMo、GPT和BERT等,这些模型引入了上下文感知的动态词向量,显著提高了模型的表达能力。
根据任务类型,预训练模型可以分为:
1. 监督学习:如CoVe,依赖于大量标注数据,但由于标注成本高,研究焦点更多地放在无监督和自监督学习。
2. 无监督学习:如自回归语言模型(auto-regressive LM)和双向语言模型(BiLM),它们利用最大似然估计在大规模未标注数据上学习语言模型,尽管无监督学习不需要标注数据,但在复杂任务上可能不如监督学习和自监督学习有效。
3. 自监督学习:如BERT,它通过预测句子中被遮蔽的单词或判断句子顺序等自监督任务进行预训练,这种方法已经在许多NLP任务中取得了突破性成果。
随着技术的不断发展,预训练模型的规模越来越大,参数数量呈指数级增长,如GPT-3这样的超大规模模型,这既展示了预训练模型的巨大潜力,也带来了计算资源和环境影响的挑战。未来的研究将集中在如何在不牺牲性能的前提下,减少模型的计算需求,以及如何更好地利用无标注数据和少量标注数据进行联合学习,以实现更加高效和泛化的自然语言处理模型。
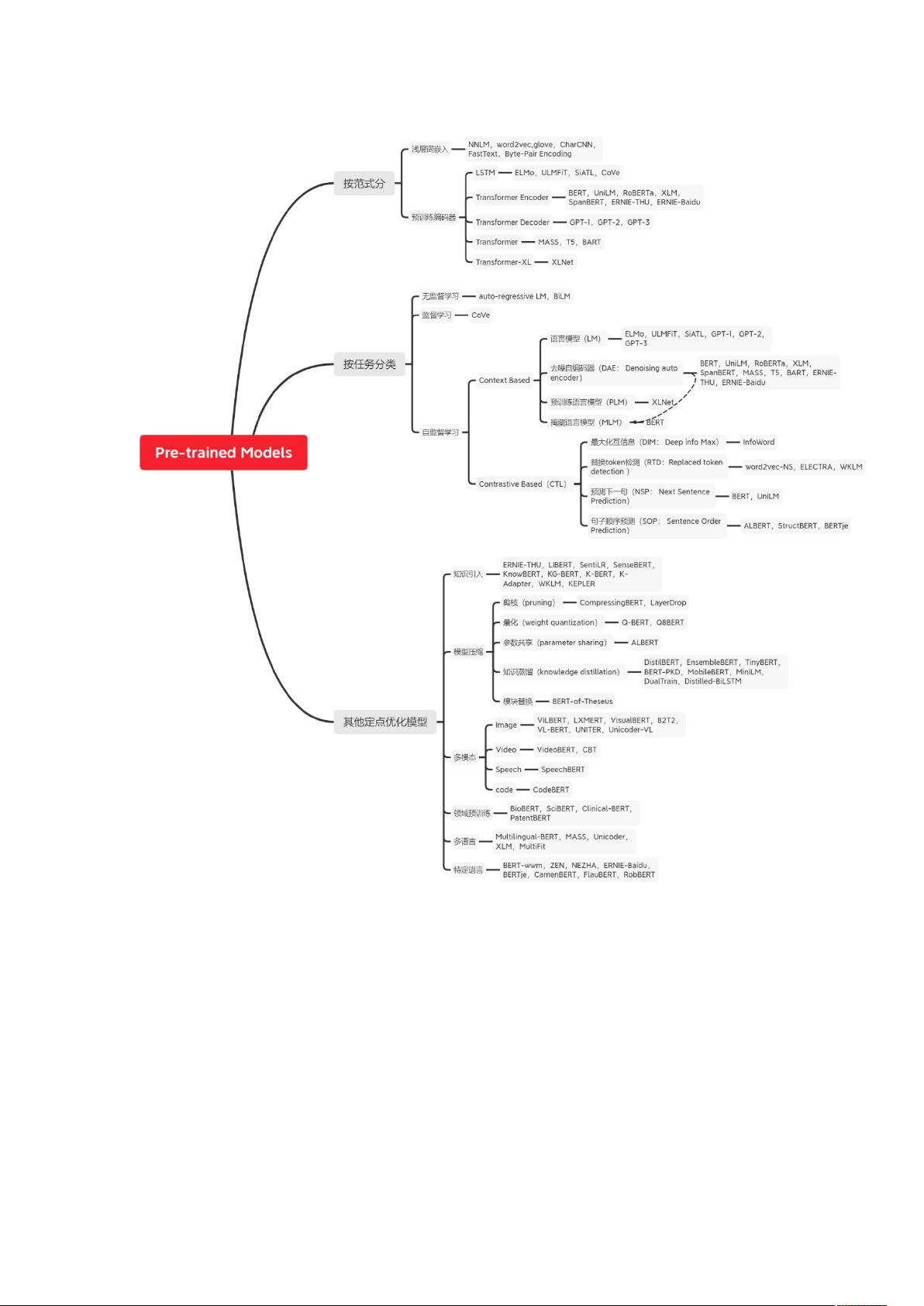
⾃然语⾔预训练模型⼤总结
Pre-trained Models.png
先来⼀张图。
本⽂主要援引复旦⼤学邱锡鹏教授的论⽂:NLP预训练模型综述,对预训练模型
进⾏了⼀些梳理
模型参数的数量增长迅速,⽽为了训练这些参数,就需要更⼤的数据集来避免
过拟合,⽽⼤规模的标注数据集成本⼜⾮常⾼。⽽相⽐之下,⼤规模未标注的
语料却很容易构建。
为了利⽤⼤量的未标注⽂本数据,我们可以先从其中学习⼀个好的表⽰,再将
这些表⽰⽤在别的任务中。这⼀通过 PTMs
从未标注⼤规模数据集中提取表⽰的预训练过程在很多 NLP
任务中都取得了很好的表现。
预训练的优点可以总结为以下三点:
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
327 浏览量
2022-08-08 上传
599 浏览量
260 浏览量
182 浏览量
293 浏览量
408 浏览量

sun7bear
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
