




WEKA机器学习实战:数据挖掘入门
"这是一份关于使用Weka进行机器学习的指南,由林松江编写,日期为2005年9月30日。Weka是一个开源的数据挖掘工具,由新西兰怀卡托大学的机器学习小组开发并维护。该资料可能涵盖了Weka的基本概念、操作方法以及在实际问题中的应用。示例数据集是关于心脏病的简化版,包含了年龄、性别、胸痛类型、胆固醇水平、运动诱导的胸痛情况以及是否存在心脏病的信息。"
Weka是一个强大的数据挖掘和机器学习软件,它提供了一个图形用户界面(GUI)以及命令行接口,便于用户进行数据预处理、分类、聚类、关联规则学习等多种任务。以下是对Weka中涉及的一些关键知识点的详细说明:
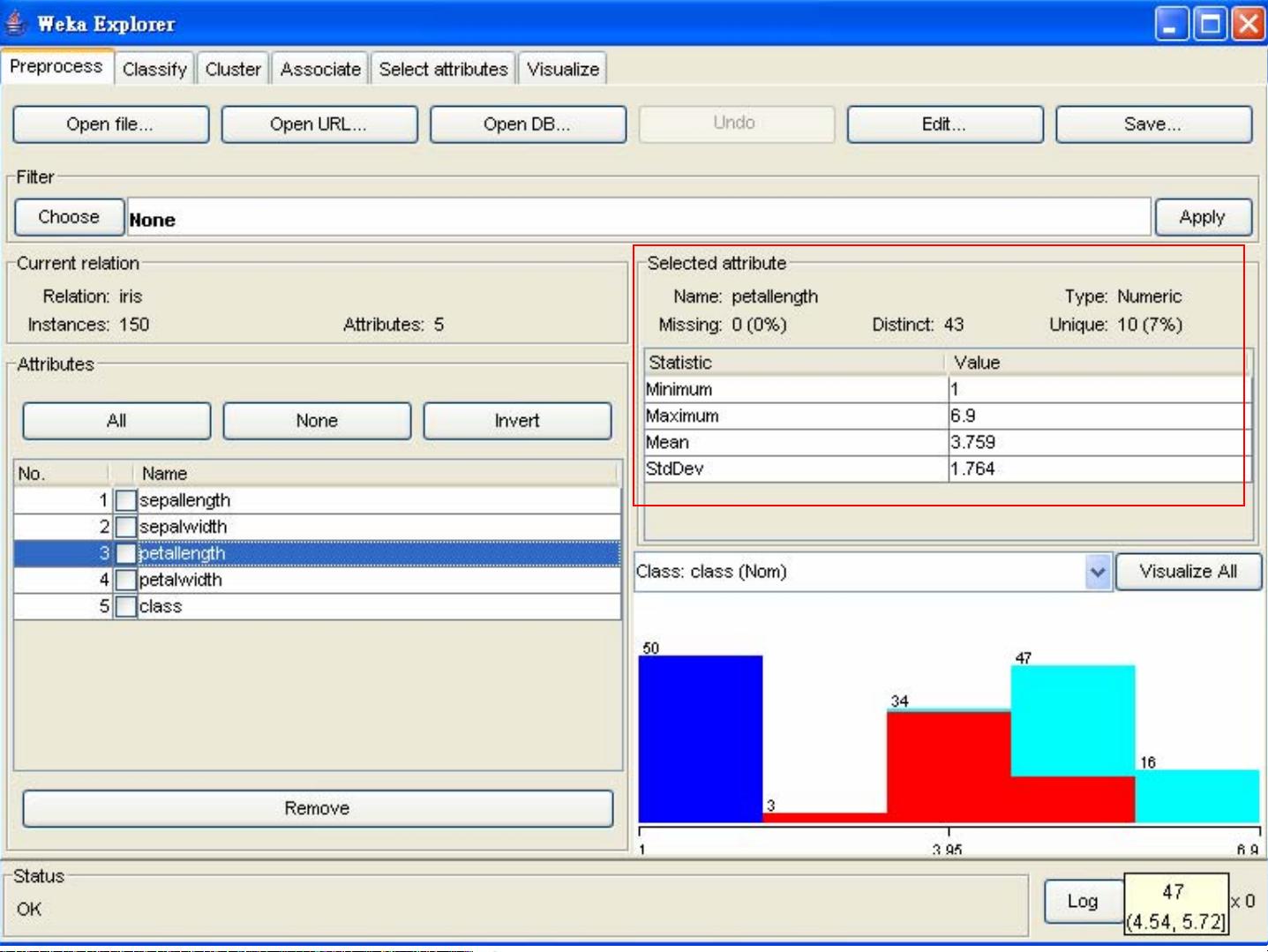
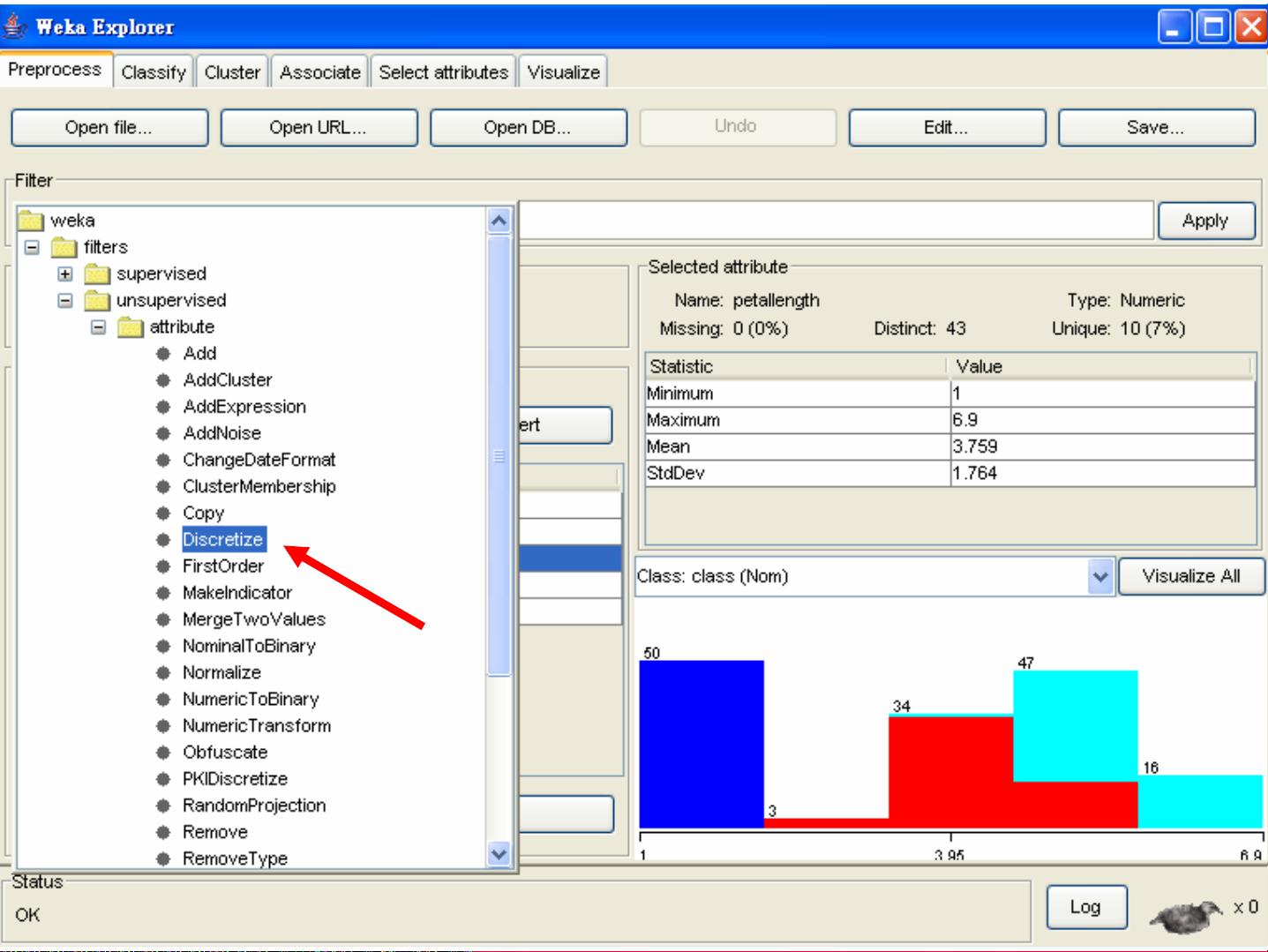
1. 数据预处理:Weka提供了多种数据预处理工具,如缺失值处理、异常值检测、特征选择和数据转换。在给定的心脏病数据集中,可以看到一个特征“cholesterol”的值为“?”,这表示缺失值,Weka可以使用不同的策略来处理这种缺失值,例如删除含有缺失值的记录、使用平均值或中位数填充等。
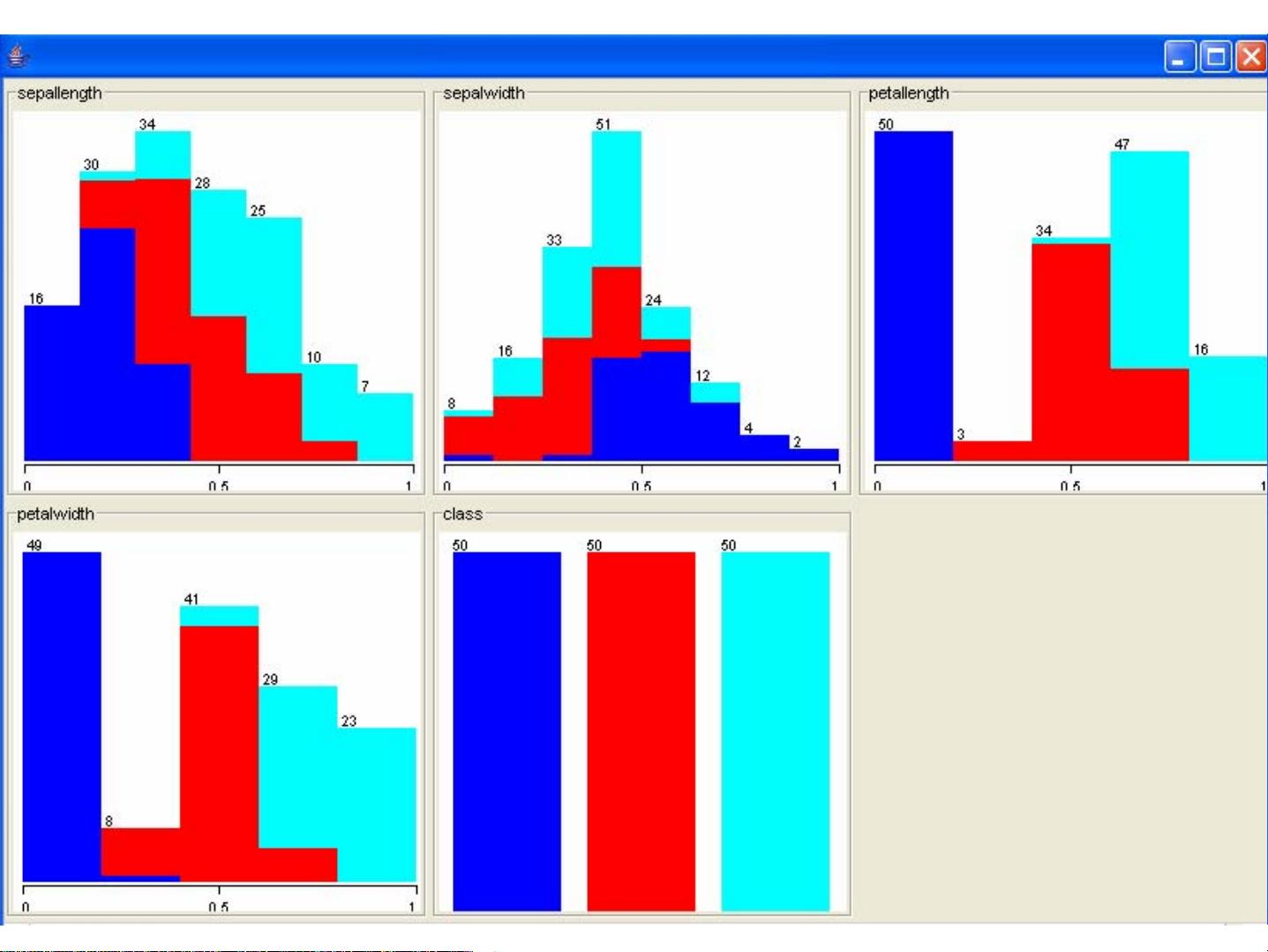
2. 数据格式:Weka支持ARFF(Attribute-Relation File Format)文件格式,这是它的标准数据输入格式。如示例所示,ARFF文件由关系名、属性定义和数据实例组成。属性可以是数值型(numeric)或分类型(如sex、chest_pain_type、exercise_induced_angina),数据实例则是一系列属性值的列表。
3. 分类:Weka包含许多经典的分类算法,如决策树(C4.5、ID3)、贝叶斯网络、支持向量机(SVM)、随机森林等。在处理心脏病数据时,可以使用这些算法构建模型来预测是否存在心脏病。
4. 评估与验证:Weka提供了交叉验证、独立测试集验证等多种评估方法,用于衡量模型的性能。例如,可以使用10折交叉验证来评估模型的泛化能力,通过混淆矩阵分析准确率、召回率、F1分数等指标。
5. 特征选择:在数据预处理阶段,Weka提供了过滤式和包裹式特征选择方法,帮助用户找出对目标变量最有影响力的特征,从而减少模型复杂度,提高预测准确性。
6. 实验设计:Weka允许用户创建复杂的实验设计,包括多个数据集、多个算法和多个评估指标,以便系统地比较不同方法的效果。
7. 可视化:Weka提供了丰富的可视化工具,如决策树的图形表示、分类结果的混淆矩阵图、聚类结果的二维投影等,帮助用户理解模型的工作原理和预测结果。
通过Weka,初学者和专业人士都能快速上手进行数据挖掘和机器学习项目,同时,Weka也支持自定义算法和扩展,为研究者提供了极大的灵活性。这个指南可能是介绍如何利用Weka进行机器学习实践的一个良好起点,涵盖了从数据导入到模型构建和评估的全过程。

相关推荐
541 浏览量
151 浏览量
273 浏览量
213 浏览量
2025-01-01 上传
2025-03-20 上传
2024-11-05 上传
2024-11-08 上传
2024-11-08 上传

zhaoshengyi
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开








最新资源
- 华为面试必看:精选面试题解密
- 深入浅出Android SDK开发:实例与创意结合全集
- 深入讲解Java反射、泛型、注解及动态代理
- C语言实现状态机四种方法的源代码解析
- JDBC Oracle驱动添加到Maven的详细指南
- Delphi硬件编程:串口通信与语音传真的高级应用
- 易语言VISTA模拟窗口源码介绍与应用
- ASPack-v2.12h: 提升DLL与EXE压缩率的有效工具
- Node.js Express与MongoDB示例应用快速部署指南
- C#实现的订单系统四层架构设计与开发
- Ecshop四合一登录插件:简化社交账号登录流程
- Delphi打造的中小型信息管理系统教程与工具
- IOS通讯录信息获取与管理技巧
- 高等教育复变函数与积分变换全解版
- 深入理解C++源码编程技巧及测试案例
- 《C++编码规范》学习笔记及PDF下载










