CentOS7配置Hadoop2.10高可用集群(HA)指南
146 浏览量
更新于2024-08-31
收藏 669KB PDF 举报
"在CentOS7环境下构建Hadoop2.10高可用(HA)集群的教程"
本教程详细阐述了如何在CentOS7系统中搭建Hadoop2.10的高可用集群。集群由6台服务器组成,其中包括2台NameNode(nn),4台DataNode(dn)以及3台JournalNode(jn)。以下是各节点的IP地址、hostname及运行的进程:
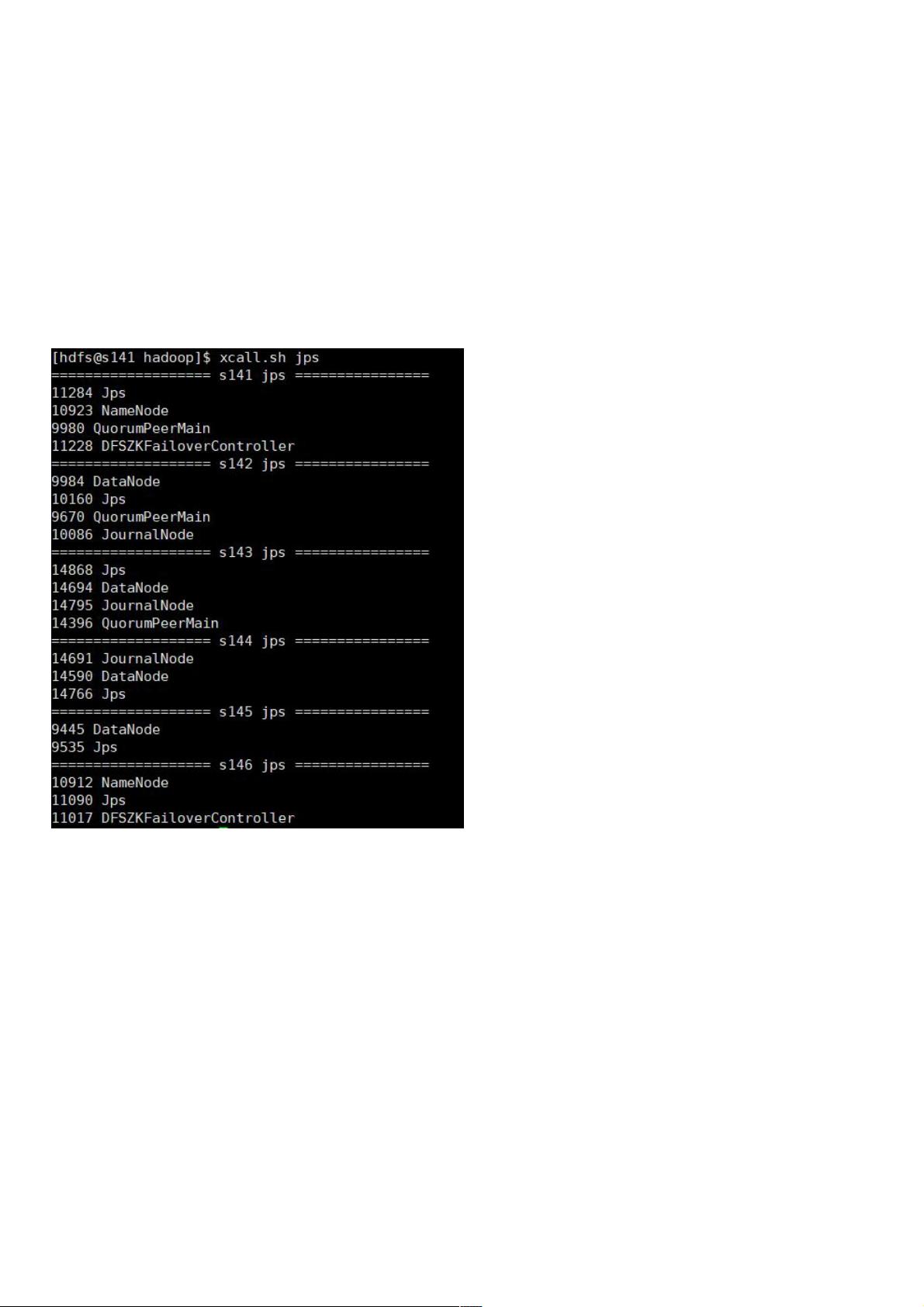
- 192.168.30.141 (s141): nn1(NameNode)、ZKFC(DFSZKFailoverController)、Zookeeper(QuorumPeerMain)
- 192.168.30.142 (s142): dn(DataNode)、jn(JournalNode)、Zookeeper(QuorumPeerMain)
- 192.168.30.143 (s143): dn(DataNode)、jn(JournalNode)
- 192.168.30.144 (s144): dn(DataNode)、jn(JournalNode)
- 192.168.30.145 (s145): dn(DataNode)
- 192.168.30.146 (s146): nn2(NameNode)、ZKFC(DFSZKFailoverController)
搭建过程中,首先确保每台机器的hostname和hosts文件正确配置,使得通过hostname可以访问到相应的IP地址。接着,配置SSH无密码登录,特别是对于NameNode节点(s141和s146),它们需要能够无密码登录到所有其他节点,这在故障切换和管理操作中非常重要。
安装过程中,首先需要创建名为"hdfs"的用户和用户组,然后安装Java开发工具(JDK),并为Hadoop环境进行必要的配置。安装Hadoop时,选择HA模式,并根据集群的拓扑结构进行相应的配置调整,例如设置HDFS的名称空间镜像和数据复制策略。
在NameNode高可用配置中,Zookeeper集群扮演着关键角色,它用于协调NameNode的故障切换。每个NameNode节点上都运行一个ZKFC进程,监控另一台NameNode的状态,一旦检测到主NameNode故障,ZKFC将与Zookeeper协作完成故障切换,确保服务的连续性。
JournalNode是Hadoop的HDFS HA组件之一,它们负责存储HDFS的Edit Logs,这些日志记录了HDFS的所有变更操作。当主NameNode发生故障时,备用NameNode可以通过JournalNodes获取未同步的Edit Logs,从而恢复到与主NameNode相同的系统状态。
DataNodes是Hadoop HDFS中的数据存储节点,它们接收来自NameNode的指令,存储和检索数据块。在集群中,DataNodes的数量越多,整个系统的容错性和存储能力就越强。
为了确保集群的安全性,通常还需要配置Secure Mode,启用Hadoop的权限验证和访问控制,如Kerberos认证。此外,还需要对Hadoop的相关配置文件(如hdfs-site.xml、core-site.xml、yarn-site.xml等)进行适当的修改,以便支持HA模式。
在所有配置完成后,执行格式化NameNode、启动Hadoop服务和检查集群健康状态等步骤。通过`jps`命令可以查看各节点正在运行的服务进程,确保所有服务都已经正常启动。
构建Hadoop2.10的高可用集群是一项复杂的工作,涉及到多台服务器的协调、配置和安全设置。这个过程需要对Hadoop的架构、HA原理以及操作系统层面的知识有深入理解。通过遵循上述步骤,你可以成功地在CentOS7环境中建立一个可靠的Hadoop高可用集群。
centos7搭建搭建hadoop2.10高可用高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode);3台
jns(journalnodes)
IP hostname 进程
192.168.30.141 s141 nn1(namenode),zkfc(DFSZKFailoverController),zk(QuorumPeerMain)
192.168.30.142 s142 dn(datanode), jn(journalnode),zk(QuorumPeerMain)
192.168.30.143 s143 dn(datanode), jn(journalnode),zk(QuorumPeerMain)
192.168.30.144 s144 dn(datanode), jn(journalnode)
192.168.30.145 s145 dn(datanode)
192.168.30.146 s146 nn2(namenode),zkfc(DFSZKFailoverController)
各个机器 jps进程:
由于本人使用的是vmware虚拟机,所以在配置好一台机器后,使用克隆,克隆出剩余机器,并修改hostname和IP,这样每台
机器配置就都统一了每台机器配置添加hdfs用户及用户组,配置jdk环境,安装hadoop,本次搭建高可用集群在hdfs用户下,
可以参照:centos7搭建hadoop2.10伪分布模式
下面是安装高可用集群的一些步骤和细节:
1.设置每台机器的设置每台机器的hostname 和和 hosts
修改hosts文件,hosts设置有后可以使用hostname访问机器,这样比较方便,修改如下:
127.0.0.1 locahost
192.168.30.141 s141
192.168.30.142 s142
192.168.30.143 s143
192.168.30.144 s144
192.168.30.145 s145
192.168.30.146 s146
2.设置ssh无密登录,由于s141和s146都为namenode,所以要将这两台机器无密登录到所有机器,最好hdfs用户和root用户
都设置无密登录
我们将s141设置为nn1,s146设置为nn2,就需要s141、s146能够通过ssh无密登录到其他机器,这样就需要在s141和s146机
器hdfs用户下生成密钥对,并将s141和s146公钥发送到其他机器放到~/.ssh/authorized_keys文件中,更确切的说要将公钥添
加的所有机器上(包括自己)
下载后可阅读完整内容,剩余9页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-07 上传
2021-10-01 上传
2020-09-15 上传
2021-01-07 上传
2012-08-13 上传

weixin_38612568
- 粉丝: 3
- 资源: 897
 我的内容管理
展开
我的内容管理
展开







最新资源
- atcoder
- cu:这是我所有角色,他们的世界等等的参考书
- samplepcb_market_app:재능마켓앱
- today.html:一个极简主义的日记应用程序,可每天记下来
- UKItten-crx插件
- k3s-aws-cluster:使用 terraform 将 rancher k3s 集群部署到 aws
- esx_status:新版本esx_status
- global-store-demo:演示项目以演示React Context
- Sistema-JSF-PrimeFaces-Hibernate
- My-WebSite:我
- Shape-Calculator:形状计算器
- Android实现毛玻璃效果
- bluepot:蓝牙蜜罐
- TDT4113
- VenddySearch
- interactive-website-with-hexagon-grid
