斯坦福CS229机器学习笔记:从线性回归到SVM
需积分: 50 82 浏览量
更新于2024-07-20
收藏 11.4MB PDF 举报
"这是一份详细的斯坦福大学CS229机器学习课程的个人学习笔记,涵盖了从基础的线性回归到高级的增强学习等多个主题。笔记由一位研究生在学习过程中整理,主要依据Andrew Ng教授的讲义和视频,同时也包含了一些其他资料。笔记可能存在个人理解和错误,建议读者在遇到疑问时参考原始讲义和视频,或者寻求专业人士的帮助。笔记作者还分享了自己的研究方向和兴趣,如分布式计算和大数据处理,并欢迎交流和合作。"
正文:
1. 线性回归与Logistic回归
- 线性回归是一种预测模型,通过找到最佳拟合直线来描述输入特征与输出之间的关系。它适用于连续数值型的预测问题。
- Logistic回归则是线性回归的扩展,用于二分类问题,通过sigmoid函数将线性组合转换为概率输出。
2. 判别模型与生成模型
- 判别模型直接学习决策边界,如SVM,关注的是如何划分样本空间,不关心数据的生成过程。
- 生成模型如朴素贝叶斯,不仅学习决策边界,还学习数据的概率分布,可以用于生成新样本。
3. 支持向量机(SVM)
- SVM是一种最大化边距的分类器,通过寻找最大间隔超平面进行分类。上下两部分分别介绍了SVM的基本概念和复杂情况下的处理,如核函数的应用。
4. 规则化与模型选择
- 规则化是为了防止过拟合,通过添加正则项来限制模型的复杂度,如L1和L2正则化。
- 模型选择涉及到交叉验证、网格搜索等方法,旨在选取最优的模型参数。
5. 聚类算法
- K-means是常见的无监督学习算法,通过迭代调整簇中心和样本分配来达到聚类目的。
- 混合高斯模型(GMM)利用概率模型进行聚类,EM算法用于求解GMM的参数。
6. 主成分分析(PCA)
- PCA用于降维,通过找到数据方差最大的方向,保留主要信息,去除噪声。
7. 在线学习
- 在线学习是一种处理流式数据的算法,每次更新基于单个或小批量样本,适合大规模数据集。
8. 其他
- 独立成分分析(ICA)寻找信号的原始非高斯分量。
- 线性判别分析(LDA)和因子分析用于特征提取和降维,常用于分类问题。
9. 增强学习
- 增强学习是通过与环境交互,通过奖励机制学习最优策略。
10. 关联规则与典型关联分析
- 发现数据集中项集之间的频繁模式,如"购买了A的人往往也会购买B"。
11. 偏最小二乘法回归(PLSR)
- PLSR用于处理多重共线性和高维数据的回归问题,同时考虑响应变量和自变量之间的相关性。
这些笔记内容全面,覆盖了机器学习的基础理论和常用算法,对于初学者和进阶者都是宝贵的参考资料。然而,由于是个人笔记,可能存在一些错误,建议结合正式教材和专业资源进行深入学习。
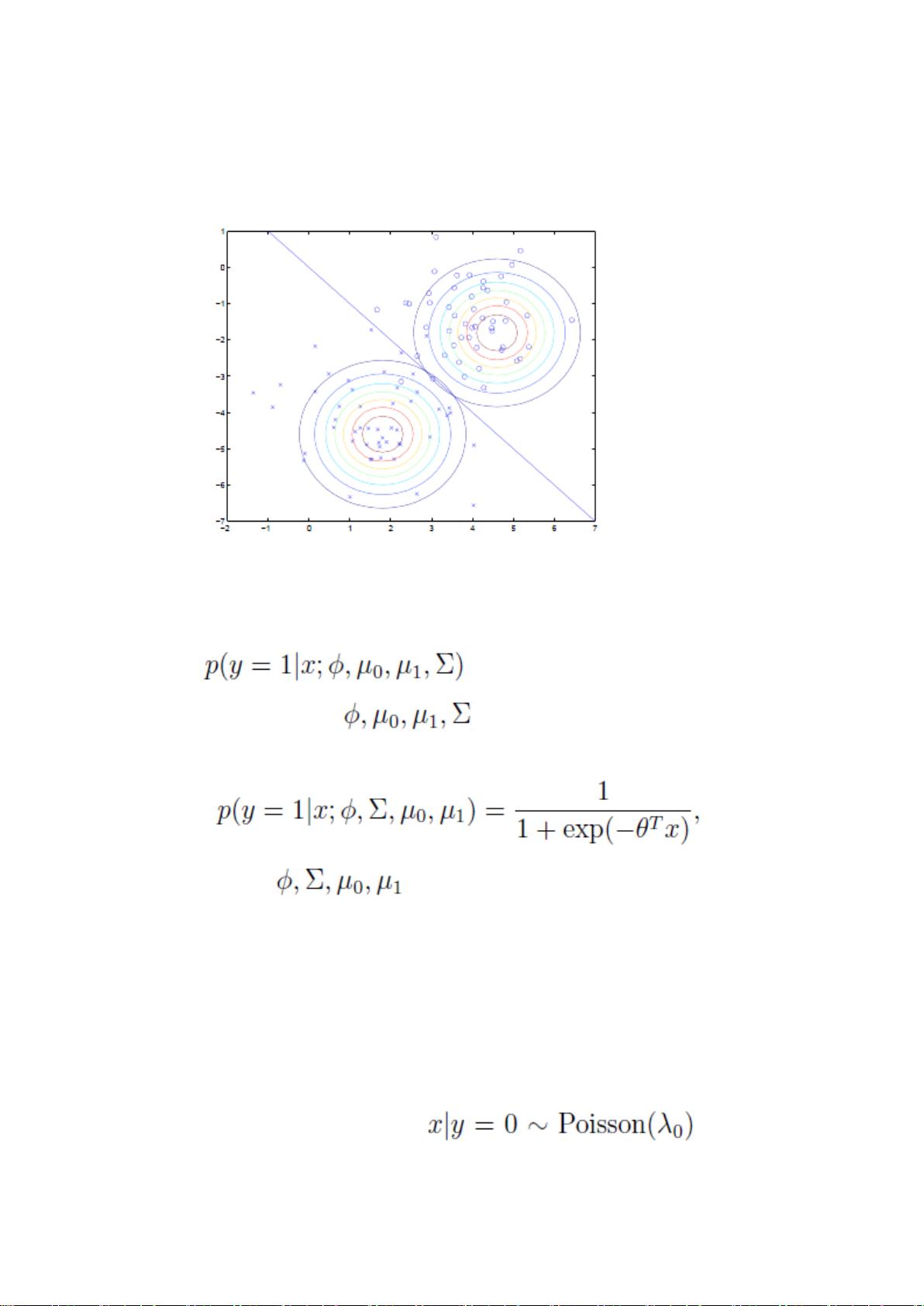
是 y=1 的样本中特征均值。
是样本特征方差均值。
如前面所述,在图上表示为:
直线两边的 y 值不同,但协方差矩阵相同,因此形状相同。不同,因此位置不同。
3) 高斯判别分析(GDA)与 logistic 回归的关系
将 GDA 用条件概率方式来表述的话,如下:
y 是 x 的函数,其中 都是参数。
进一步推导出
这里的是 的函数。
这个形式就是 logistic 回归的形式。
也就是说如果 p(x|y)符合多元高斯分布,那么 p(y|x)符合 logistic 回归模型。反之,
不成立。为什么反过来不成立呢?因为 GDA 有着更强的假设条件和约束。
如果认定训练数据满足多元高斯分布,那么 GDA 能够在训练集上是最好的模型。然
而,我们往往事先不知道训练数据满足什么样的分布,不能做很强的假设。Logistic
回归的条件假设要弱于 GDA,因此更多的时候采用 logistic 回归的方法。
例如,训练数据满足泊松分布,
13



剩余136页未读,继续阅读
2022-09-20 上传
2023-06-18 上传
581 浏览量
2024-12-17 上传
2024-12-17 上传
2024-12-17 上传
2024-12-17 上传
2024-12-17 上传
2024-12-17 上传

MachineLP
- 粉丝: 6387
- 资源: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入了解Django框架:Python中的网站开发利器
- Spring Boot集成框架示例:深入理解与实践
- 52pojie.cn捷速OCR文字识别工具实用评测
- Unity实现动态水体涟漪效果教程
- Vue.js项目实践:饭否每日精选日历Web版开发记
- Bootbox:用Bootstrap实现JavaScript对话框新体验
- AlarStudios:Swift开发教程及资源分享
- 《火影忍者》主题新标签页壁纸:每日更新与自定义天气
- 海康视频H5player简易演示教程
- -roll20脚本开发指南:探索roll20-master包-
- Xfce ClassicLooks复古主题更新,统一Linux/FreeBSD外观
- 自建物理引擎学习刚体动力学模拟
- Python小波变换工具包pywt的使用与实例
- 批发网导航程序:自定义模板与分类标签
- 创建交互式钢琴键效果的JavaScript库
- AndroidSunat应用开发技术栈及推介会议
