理解机器学习:训练集与测试集的划分与过拟合、欠拟合
28 浏览量
更新于2024-08-30
收藏 210KB PDF 举报
"这篇资源是关于机器学习基础知识的笔记,主要讨论了训练集和测试集的划分、欠拟合和过拟合的概念以及偏差与方差的解释。"
在机器学习中,训练集和测试集的划分至关重要。这是因为我们需要评估模型在未知数据上的表现,而不仅仅是对已知数据的拟合程度。如果模型只使用训练数据进行评估,它可能会出现过拟合现象,即过度学习训练数据中的细节,包括噪声,导致在新数据上的预测效果不佳。因此,通常我们会将数据集划分为训练集(通常是70%或80%)和测试集(30%或20%),并在训练集上训练模型,用测试集来度量模型的泛化能力。
欠拟合和过拟合是机器学习中常见的两种问题。欠拟合指的是模型在训练集上的误差较高,这可能是因为模型过于简单,无法捕捉数据集中的复杂模式。解决欠拟合的方法通常包括增加模型复杂度,如添加更多的特征或者调整模型参数。
相反,过拟合是模型在训练集上表现很好,但在测试集上表现较差的情况。这通常是因为模型过于复杂,过度学习了训练数据,甚至学到了噪声,导致对新数据的泛化能力下降。防止过拟合的方法包括使用正则化、增加数据集大小、使用交叉验证或者采用更简单的模型结构。
偏差和方差是理解模型性能的两个关键指标。偏差是指模型预测的期望值与真实值之间的差距,反映了模型的预测能力;而方差则衡量了模型预测的离散程度,即预测值偏离期望值的程度。低偏差意味着模型对数据的总体趋势把握得较好,但高方差表示模型对数据的波动非常敏感,容易受到噪声的影响。过拟合往往伴随着低偏差和高方差,欠拟合则是高偏差和相对较低的方差。
以射击打靶为例,如果子弹总是偏左,那么这是高偏差的表现,意味着射击者需要调整瞄准策略;而如果子弹散布范围很大,即使中心点比较集中,这也表明高方差,意味着射击者需要提高射击稳定性。在机器学习中,我们需要找到一个平衡点,使得模型既不过于简单导致欠拟合,也不过于复杂导致过拟合,从而提高模型在实际应用中的预测精度和泛化能力。
机器学习基础(笔记机器学习基础(笔记1))
常见概念(常见概念(1))
为什么要有训练集和测试集?
我们想要利用收集的猫狗数据构建一个机器学习模型,用来预测新的图片,但在将模型用于新的测量数据之前,我们需要知道
模型是否有效,也就是说,我们是否应该相信它的预测结果。不幸的是,我们不能将用于构建模型的数据用于评估模型的性
能。因为我们的模型会一直记住整个训练集,所以,对于训练集中的任何数据点总会预测成正确的标签。这种记忆无法告诉我
们模型的泛化能力如何,即预测新样本的能力如何。我们要用新数据来评估模型的性能。新数据是指模型之前没见过的数据,
而我们有这些新数据的标签。通常的做法是,我们把手头上的数据分为两部分,训练集与测试集。训练集用来构建机器学习模
型,测试集用来评估模型性能。
如何划分训练集和测试集?
通常我们将手头数据的百分之 70 或 80 用来训练数据,剩下的百分之 30 或 20 作为测试用来评估模型性能。值得注意的是,
在划分数据集之前,我们要先把手头上的数据的顺序打乱,因为我们搜集数据时,数据可能是按照标签排放的。比如,现在有
100 张图片,前 50 张是猫,后 50 张是狗,如果将后面的 30 张照片当做测试集,这时测试集中只有狗狗一个类别,这无法告
诉我们模型的泛化能力如何,所以我们将数据打乱,确保测试集中包含所有类别的数据。
什么是欠拟合和过拟合?造成的原因?
欠拟合:模型在训练集上误差很高;
欠拟合原因:模型过于简单,没有很好的捕捉到数据特征,不能很好的拟合数据。
过拟合:在训练集上误差低,测试集上误差高;
过拟合原因:模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地
识别数据,模型泛化能力太差。
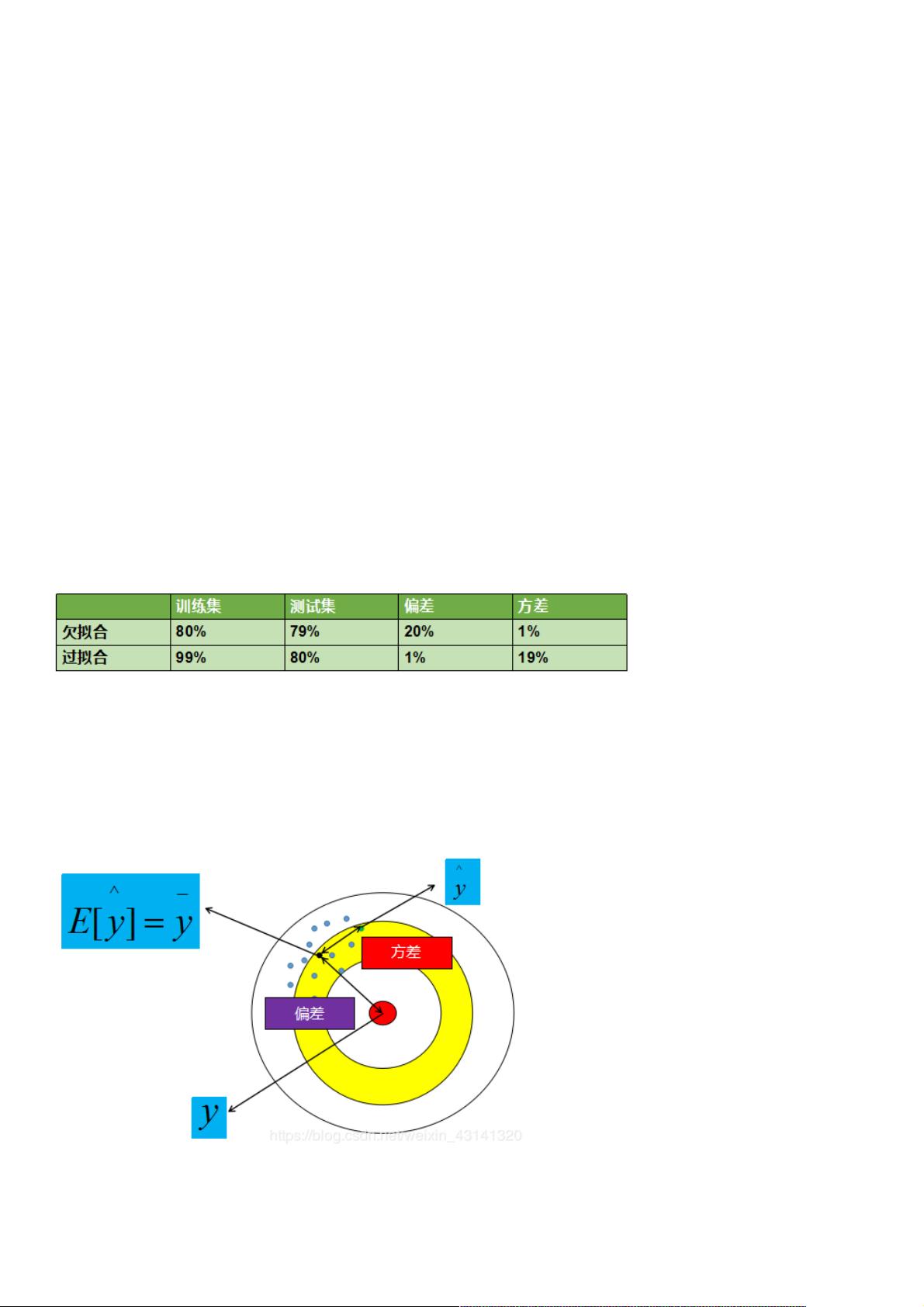
偏差与方差
模型在训练集上的误差来源主要来自于偏差,在测试集上误差来源主要来自于方差。
上图表示,如果一个模型在训练集上正确率为 80%,测试集上正确率为 79% ,则模型欠拟合,其中 20% 的误差来自于偏
差,1% 的误差来自于方差。如果一个模型在训练集上正确率为 99%,测试集上正确率为 80% ,则模型过拟合,其中 1% 的
误差来自于偏差,19% 的误差来自于方差。
可以看出,欠拟合是一种高偏差的情况。过拟合是一种低偏差,高方差的情况。
偏差:预计值的期望与真实值之间的差距;
方差:预测值的离散程度,也就是离其期望值的距离。
以射击打靶为例,蓝色的小点是我们在靶子上的射击记录,蓝色点的质心(黑色点)到靶心的距离为偏差,某个点到质心的距
离为方差。所以,某个点到质心的误差就是由偏差与方差所组成。那么,为什么欠拟合是一直高偏差情况,过拟合是一种低偏
差高方差情况呢?
下载后可阅读完整内容,剩余3页未读,立即下载
2023-11-03 上传
2018-03-28 上传
2022-06-10 上传
2021-01-06 上传
2023-11-07 上传
2018-02-06 上传
2022-08-08 上传

weixin_38685608
- 粉丝: 1
- 资源: 995
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python库 | Matador-4.0.2-py3-none-any.whl
- flutter-expenses-app:Flutter实践项目
- 现代法谱估计功率谱密度.rar
- 博客
- leafletmarkercluster
- 行业分类-设备装置-可逆热变色性水性墨组合物及使用了其的书写工具、书写工具套件.zip
- korlamarch-com:三月的个人网站
- arcolinux-iso
- 西特萨科
- reviewing-a-pull-request
- 程序禁止多开的方法之一-易语言
- 行业分类-设备装置-可编程控制器、可编程控制器系统及执行错误信息生成方法.zip
- themodernway-server-core
- Tulis_Aken:源代码Bot Nulis(仍在开发中)
- 面板:仪表盘
- Mascot-eat:物联网物联网副食品吉祥物
