XML文档聚类:技术与挑战
下载需积分: 7 | PDF格式 | 554KB |
更新于2024-07-23
| 37 浏览量 | 举报
随着XML文档的日益增多和异构性增强,处理这些半结构化数据的问题也随之浮现。XML文档的表示和管理变得至关重要,尤其是在知识提取和资源管理方面。近年来,为了有效地对XML文档进行聚类和分析,研究者们提出了一系列方法,并发展了多种不同的相似度度量,同时在某些情况下还考虑了语义因素。
本文的主要焦点在于XML文档聚类技术,包括树形和向量表示法的运用,以及各种相似度度量的比较。作者Elaheh Asghari和 Mohammad Reza Keyvan Pour在《人工智能评论》(ArtifIntellRev)上发表的文章《XML文档聚类:技术和挑战》(XML document clustering: techniques and challenges)回顾了这些方法,并提出了一种分类体系来组织这些提议的技术。他们探讨的主题涵盖了以下几个关键点:
1. **XML文档的表示**:XML因其简单、自描述和灵活的特性而受到青睐,这使得它在数据存储和传输中有广泛的应用。为了便于分析,研究人员发展了多种文档表示方法,如基于树结构的表示(如XML解析树)和基于向量的表示,以便将文档转换为数值形式便于算法处理。
2. **相似度度量**:不同的聚类算法需要不同的相似度度量作为基础。这些度量可以是基于字符的、词汇的、结构的或者语义的,例如Edit Distance、Jaccard相似度、TF-IDF等。选择合适的相似度度量对于获得高质量的聚类结果至关重要。
3. **聚类算法**:文章中涵盖了多种聚类算法,如层次聚类(Hierarchical Clustering)、K-means、DBSCAN、谱聚类等,每种算法都有其适用的场景和优缺点,适用于不同类型的XML文档和需求。
4. **聚类质量评估**:聚类算法的性能评估也是关键部分,作者可能讨论了如轮廓系数、Calinski-Harabasz指数等常用的评价指标,以衡量聚类结果的凝聚度和分离度。
5. **语义聚类**:考虑到XML文档可能包含丰富的语义信息,研究者探讨了如何在聚类过程中考虑上下文和领域特定的知识,以提高聚类的准确性和实用性。
总结来说,这篇文章深入剖析了XML文档聚类领域的挑战与技术,为理解和应用这些方法提供了宝贵的参考,对于从事XML数据分析和信息检索的读者具有很高的价值。
E. Asghari, M. KeyvanPour
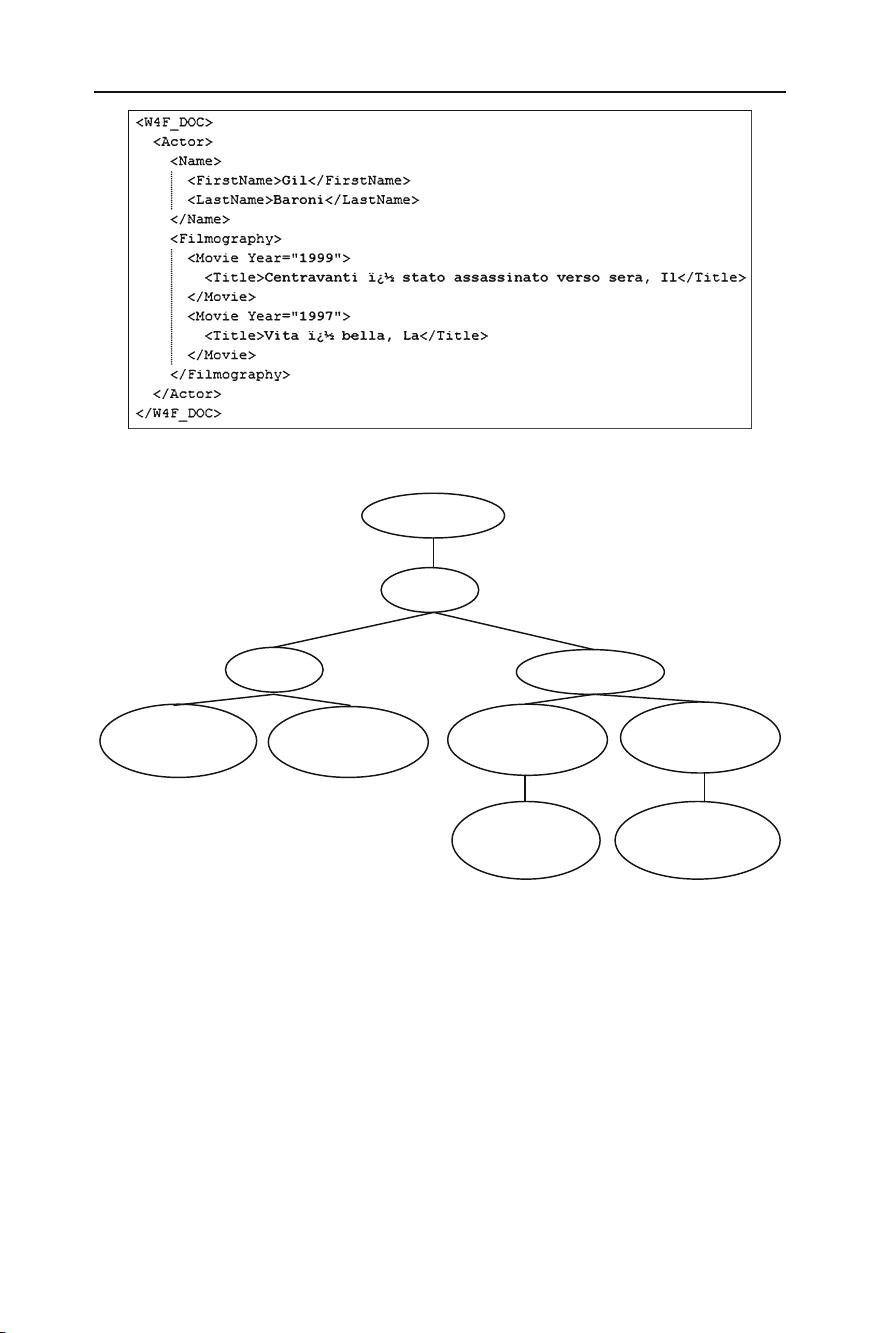
Fig. 1 An XML document sample
W4F_DOC
Name
Actor
Filmography
FirstName=
"Gil"
LastName=
"Baroni"
Movie
Year="1999
"
Title= "Vita …"
Title=
"Centravanti …"
Movie
Year="1997"
Fig. 2 The XML document tree
capable of manipulating the structure of contents as well as the contents themselves besides
considering to the semantics.
Mining of XML documents significantly differs from structured data mining and text
mining. XML allows the representation of semi-structured and hierarchal data containing the
values of individual items and the relationships between data items.
XML mining includes mining both the structure and the contents from XML documents.
Mining of structure, which is essentially mining the XML schema, includes intra-structure
mining (mining the structure inside an XML document) and inter-structure mining (mining
the structures between XML documents). Mining of content involves content analysis and
structure clarification. Content analysis is concerned with analyzing texts within the XML
document. Structural clarification is concerned with determining the similar documents based
on their content.
123
剩余19页未读,继续阅读
相关推荐


qq_17589997
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- NLP_practices:涉及日常实验室和作业
- HierarchicalComputerFileSystem:C ++程序,可模拟简单的分层计算机文件系统
- app开发之React Native教程合集.zip_zipapp lite
- Python二级编程题.zip
- laravel-web-to-pdf
- 大学物理实验目录及正文.rar
- v2ex-ios::globe_showing_Europe-Africa: v2ex - 创意工作者社区
- E-Comm-laravel
- 女性个人简历信息响应式网页模板
- 网上购物系统:AT Project Sem-5
- Python_ProgramingExperience_to_Pythonic。记录编程过程中遇到的一些问题和解决资料.zip
- tcbot:Tcbot 是 IRC 到 WoW Channel 桥接机器人
- lein-git-inject:Leiningen中间件,它在构建时从环境git上下文中计算“版本”(请考虑最新标签)
- grbl1.1f20170801-stm32f103c8t6
- 微信小程序Demo:小费计算器
- 《Python编程:从入门到实践》、《笨办法学Python》练习题.zip
