LDA模型详解:原理、应用与实战
LDA(Latent Dirichlet Allocation,潜在狄利克雷分配)是一种基于概率的主题模型,用于分析文本数据中的潜在主题结构。该模型由David Blei等人在2003年提出,主要用于文档聚类和主题发现。在给定的文档集合中,LDA假设每篇文档由多个主题混合而成,而每个主题又由一系列词语组成,这些词语的出现频率反映了主题的特性。
LDA模型的核心原理是使用贝叶斯网络(Bayesian Network)和 Expectation-Maximization (EM) 算法。EM算法是一种迭代优化方法,通过两个步骤进行:期望(Expectation)步骤,根据当前模型参数估计每个文档中每个词属于各个主题的概率;最大化(Maximization)步骤,更新主题和词语分布的参数,使得数据的似然性最大。同时,维特比算法(Variational Inference)也可用于近似求解,因为它提供了更高效的计算方法。
在使用LDA模型时,主要关注以下几个方面:
1. **文档主题**:模型能够识别出文档集中的关键主题,并分析每个文档如何组合这些主题。例如,一个新闻文档集合可能包含经济、科技和体育等多个主题,LDA能帮助我们识别出每篇文章中各个主题的占比。
2. **主题演化**:如果文档集合的时间跨度较长,LDA可以探索主题随时间的变化,比如某个主题的兴起和衰落。
3. **主题关系**:LDA揭示了不同主题之间的关联性,即哪些词语经常一起出现,从而形成主题间的联系。
4. **概率分布**:LDA利用多项分布和条件概率来量化词语在主题中的分布,以及文档中各个主题的分布。
5. **应用示例**:报告中提到了掷硬币和投掷骰子的例子,作为对LDA基本概念的直观解释,进而引申到实际文本数据中的应用,如分析博客文章或新闻文本的主题构成。
6. **进一步阅读与资源**:报告最后提供了进一步学习LDA模型及相关技术的参考资料,帮助读者深入理解和实践这一主题模型。
通过LDA,研究人员和分析人员能够更好地理解大量文本数据的内在结构,这对于信息检索、文本挖掘、舆情分析等领域具有重要意义。在实际操作中,选择合适的参数、预处理数据和评估模型性能都是使用LDA的关键步骤。

8
概率分布
— Dirichlet
分布
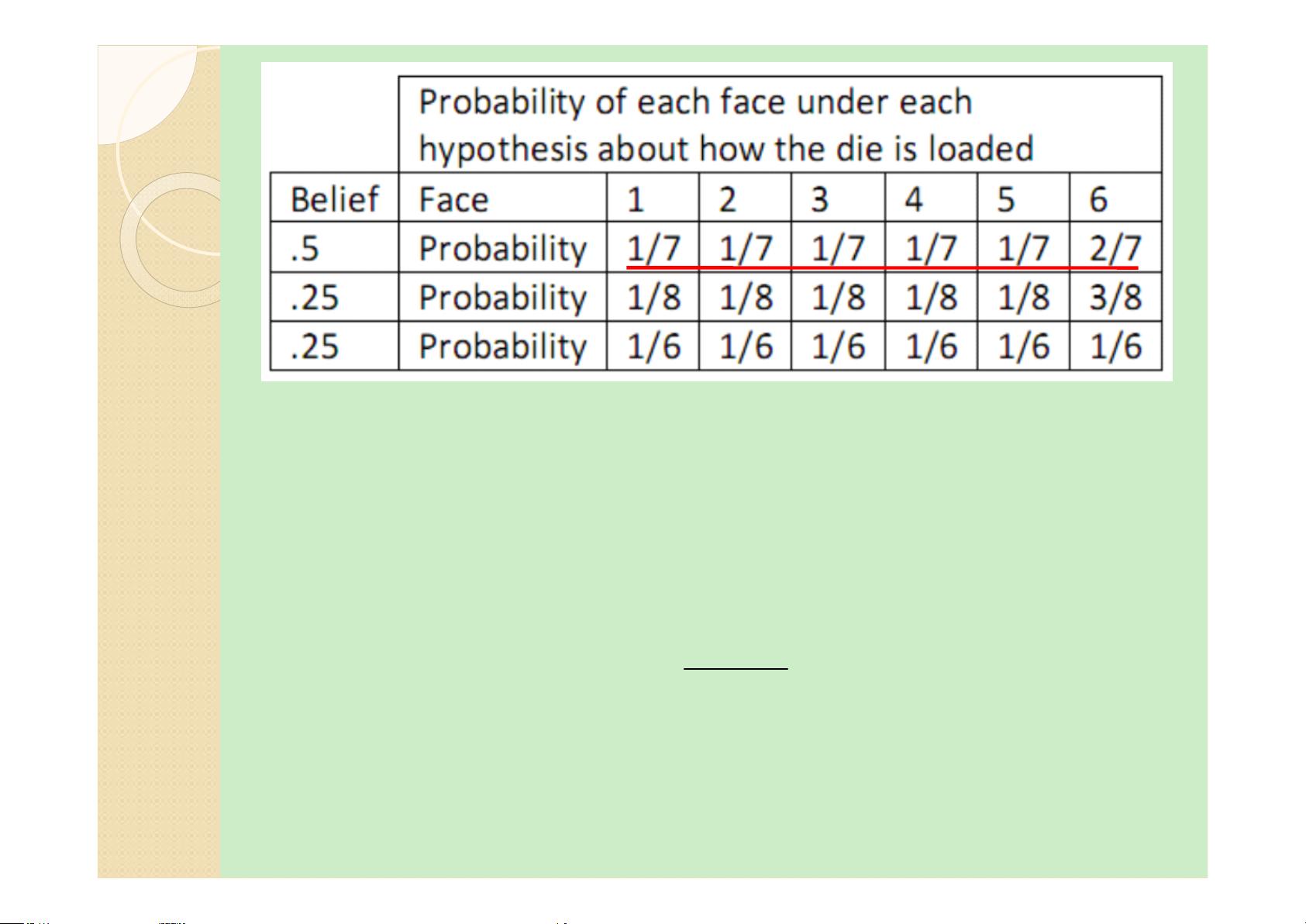
假设我们在和一个人玩掷骰子游戏。正
常情况下我们都会认为骰子的每个面出
现的概率是相等的,为
1/6
;但是现在
我们看到掷骰子的人连续掷出
6
,不免
心生猜测:
50%
的可能:
6
出现的概率为
2/7
,其他
各面为 1/7 ;
25%
的可能:
6
出现的概率为
3/8
,其他
各面为 1/8 ;
25%
的可能:各面的概率为
1/6
剩余42页未读,继续阅读
2022-08-04 上传
2016-03-12 上传
2021-03-02 上传
点击了解资源详情
点击了解资源详情
2008-11-16 上传
2021-06-04 上传

独孤剑
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 行业分类-设备装置-可移动平台的观测设备.zip
- study:学习
- trivia_db:琐事数据库条目
- SampleNetwork:用于说明数据源与模型之间的链接的示例网络
- commons-wrap:包装好的Apache Commons Maven存储库
- rdiot-p021:适用于Java的AWS IoT核心+ Raspberry Pi +适用于Java的AWS IoT设备SDK [P021]
- 测试工作
- abhayalodge.github.io
- 行业分类-设备装置-可调分辨率映像数据存储方法及使用此方法的多媒体装置.zip
- validates_existence:验证 Rails 模型belongs_to 关联是否存在
- 26-grupe-coming-soon
- aquagem-site
- cpp_examples
- Scavenge:在当地的食品储藏室中搜索所需的食物,进行预订,并随时了解最新信息! 对于食品储藏室管理员,您可以在此处管理食品储藏室信息和库存
- Hels-Ex7
- 行业分类-设备装置-可调式踏板.zip
