HBase架构解析:核心模块与工作流程
97 浏览量
更新于2024-08-27
收藏 671KB PDF 举报
本文主要介绍了HBase架构的核心模块,包括HRegionServer、Client、Zookeeper以及Master,深入解析了HBase的工作流程和数据存储机制。
HBase架构核心模块:
HBase是一个分布式、版本化的NoSQL数据库,基于Google的Bigtable设计,运行在Hadoop HDFS之上。它的核心架构由几个关键组件组成,这些组件共同协作以提供高效的数据存储和检索服务。
1. HRegionServer:
HRegionServer是HBase的主要工作节点,负责处理客户端的读写请求。每个HRegionServer管理多个HRegion,每个HRegion对应表的一部分数据。对于每个表的HColumnFamily,HRegionServer会创建一个Store实例。每个Store包含一个或多个StoreFile,它们是HFile的轻量级封装,用于实际存储数据。数据写入时,首先写入HLog保证数据可靠性,然后写入内存中的MemStore。当MemStore达到一定大小或特定条件时,会被flush到磁盘形成新的StoreFile。
2. Client:
客户端是与HBase交互的接口,它负责整合集群入口,通过HBase RPC机制与HMaster和HRegionServer通信。客户端执行管理操作(如表操作)和读写操作,并维护缓存以加速访问,例如Region的位置信息。
3. Zookeeper:
Zookeeper在HBase中起到关键的协调和管理作用,确保只有一个运行中的HMaster,同时监控RegionServer状态。它存储所有Region的寻址信息,当RegionServer发生故障时,能及时通知HMaster进行处理。此外,Zookeeper还存储HBase的schema和表元数据。
4. Master:
HMaster是HBase的管理节点,负责表的生命周期管理(创建、删除、更改等),Region的分裂与分配,以及RegionServer的负载均衡。当RegionServer宕机时,HMaster会接管其上的Region,确保数据服务的连续性。即使HMaster失效,数据读取仍可继续,但元数据修改会受到影响。
5. RegionServer:
RegionServer是数据存储和处理的主体,它们持有Region并处理对应的I/O请求。RegionServer还负责Region的分裂,当Region变得过大时,会将其切分为两个更小的Region,以保持良好的性能和可扩展性。
HBase的工作流程:
写入过程中,数据首先被写入HLog,确保持久化,然后进入MemStore。当MemStore满或达到预设条件,会触发flush操作,数据被写入到一个新的StoreFile。随着时间推移,StoreFiles会积累,当满足合并条件时,会被合并成更少、更大的文件,以优化读取效率。
读取时,客户端首先查询Zookeeper获取Region的位置信息,然后直接与相应的RegionServer通信。RegionServer根据行键查找数据所在的StoreFile,读取最新版本的数据返回给客户端。
HBase通过这种分布式架构和精心设计的数据处理流程,实现了大数据场景下的高性能和高可用性。
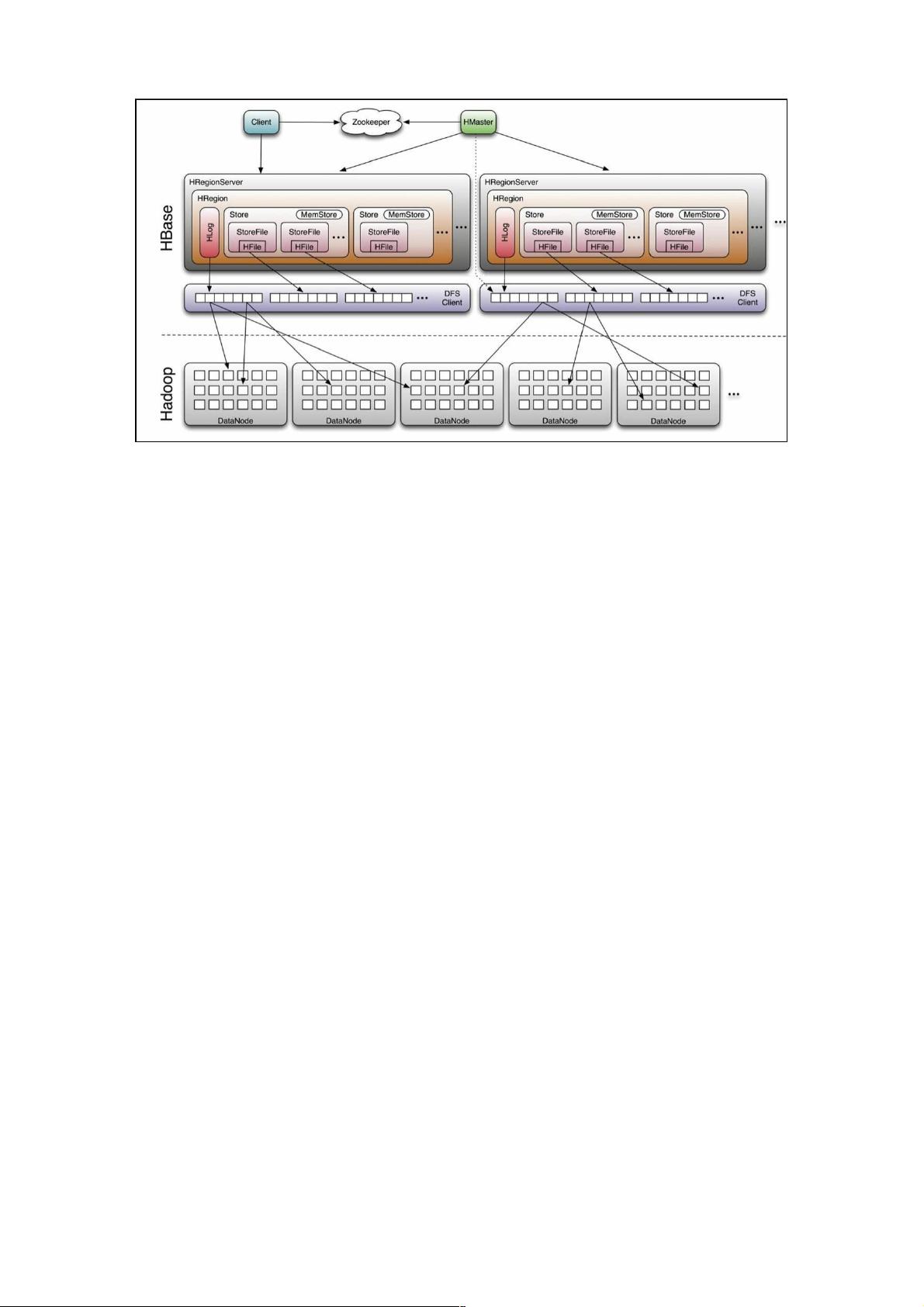
HBase架构核心模块架构核心模块
Hbase物理模型架构体系
hbase工作流程
HRegionServer负责打开region,并创建HRegion实例,它会为每个表的HColumnFamily(用户创建表时定义的)创建一个
Store实例,每个Store实例包含一个或多个StoreFile实例。是实际数据存储文件HFile的轻量级封装,每个Store会对应一个
MemStore。写入数据时数据会先写入Hlog中成功后在写入MemStore中。Memstore中的数据因为空间有限,所以需要定期
flush到文件StoreFile中,每次flush都是生成新的StoreFile。HRegionServer在处理Flush请求时,将数据写成HFile文件永久存
储到HDFS上,并且存储最后写入的数据序列号。
Client
(1)整合HBase集群的入口
(1)使用HBase RPC机制与HMaster和HRegionserver通信
(1)与HMaster通信进行管理类的操作
(1)与HRegionserver通信进行读写类操作
(1)包含访问hbase 的接口,client 维护着一些cache 来加快对hbase 的访问,比如regione 的位置信息
Zookeeper
保证任何时候,集群中只有一个running master,Master与RegionServers启动时会向ZooKeeper注册默认情况下,HBase 管
理ZooKeeper 实例,比如,启动或者停止ZooKeeperZookeeper的引入使得Master不再是单点故障
存贮所有Region 的寻址入口
实时监控RegionServer 的状态,将Regionserver 的上线和下线信息,实时通知给Master
存储Hbase的schema和table元数据
Master
管理用户对Table的增删改查操作
在RegionSplit后,分配新region的分配
负责regionserver的负载均衡,调整region分布
在RegionServer停机后,负责失效Regionserver上region的重新分配
HMaster失效仅会导致所有元数据无法修改,表达数据读写还是可以正常运行
Region Server
下载后可阅读完整内容,剩余7页未读,立即下载
2018-04-14 上传
2020-05-03 上传
2020-02-26 上传
2024-10-30 上传
2024-10-26 上传
2023-04-06 上传
2023-06-04 上传
2024-10-30 上传
2024-10-30 上传

weixin_38627603
- 粉丝: 0
- 资源: 897
 我的内容管理
展开
我的内容管理
展开







最新资源
- PureMVC AS3在Flash中的实践与演示:HelloFlash案例分析
- 掌握Makefile多目标编译与清理操作
- STM32-407芯片定时器控制与系统时钟管理
- 用Appwrite和React开发待办事项应用教程
- 利用深度强化学习开发股票交易代理策略
- 7小时快速入门HTML/CSS及JavaScript基础教程
- CentOS 7上通过Yum安装Percona Server 8.0.21教程
- C语言编程:锻炼计划设计与实现
- Python框架基准线创建与性能测试工具
- 6小时掌握JavaScript基础:深入解析与实例教程
- 专业技能工厂,培养数据科学家的摇篮
- 如何使用pg-dump创建PostgreSQL数据库备份
- 基于信任的移动人群感知招聘机制研究
- 掌握Hadoop:Linux下分布式数据平台的应用教程
- Vue购物中心开发与部署全流程指南
- 在Ubuntu环境下使用NDK-14编译libpng-1.6.40-android静态及动态库
