用户消费行为分析:数据预处理、模型训练与价值评估
版权申诉
40 浏览量
更新于2024-06-16
收藏 2.4MB PDF 举报
"全国大学生数据统计与分析竞赛21年B题本科生组的优秀论文,主要探讨了用户消费行为价值分析,涉及数据预处理、数据分析、模型构建与评估、关联规则挖掘等多个方面,使用Python和R语言进行实现。"
这篇论文详细介绍了参赛团队在面对“用户消费行为价值分析”这一问题时,采取的策略和方法。首先,他们认识到在互联网时代,识别高价值用户和有效营销渠道的重要性。为了实现这一目标,他们对用户的行为数据进行深入分析,以确定用户价值,优化营销策略。
在数据预处理阶段,论文中提到了对缺失值、异常值和数据不平衡问题的处理。对于城市字段的缺失值,选择直接删除;异常值则利用随机森林和KNN算法进行处理;针对数据不平衡,应用了SMOTE算法平衡正负样本;最后,通过正态标准化规范化数据。此外,他们还整合了不同表格中的用户ID,以便后续分析。
在任务二中,团队使用Python对数据进行分组和聚合,借助Echarts、Plotly、Matplotlib等工具进行数据可视化,展示了用户的城市分布和登录情况。通过多种角度的可视化分析,如城市分布的人数排序、3D地图展示、城市分级统计以及用户登录的天数、开课数与添加客服好友、领券数的关系,以揭示用户行为模式。
任务三是构建预测用户购买行为的模型。团队选择了LightGBM和BP神经网络进行对比实验,通过8:2的比例划分数据集,并使用LightGBM的验证集调整参数。实验结果显示,LightGBM算法在测试集上的准确率和F1分数均优于BP神经网络,因此选择LightGBM作为最终模型。
最后,在任务四中,团队运用Apriori关联规则算法对数据特征与用户购买行为进行挖掘,寻找潜在的购买关联性,以期进一步优化推荐系统和提升用户转化率。
这篇论文展示了如何运用统计学和机器学习方法来解决实际商业问题,特别是在用户行为分析和预测方面,为其他企业和研究者提供了有价值的参考。

第 5 页 共 36 页
图 4-1-3 distance_day 处理异常值前箱线图
采用相同的方法,我们发现 login_day 数据集中 login_day(登录天数)、login_diff_time
(登录间隔时间)以及 user_info 数据集中 age_month(年龄)也含有数量较多的异常值。
2)异常值处理
对于异常值主要使用随机森林和 KNN 插补方法进行填充,处理后的数据展示如下(同
样以 distance_day 为例):
图 4-1-4 distance_day 处理异常值后箱线图
从上图中,我们可以发现,处理完异常值,数据分布更加正常平稳。
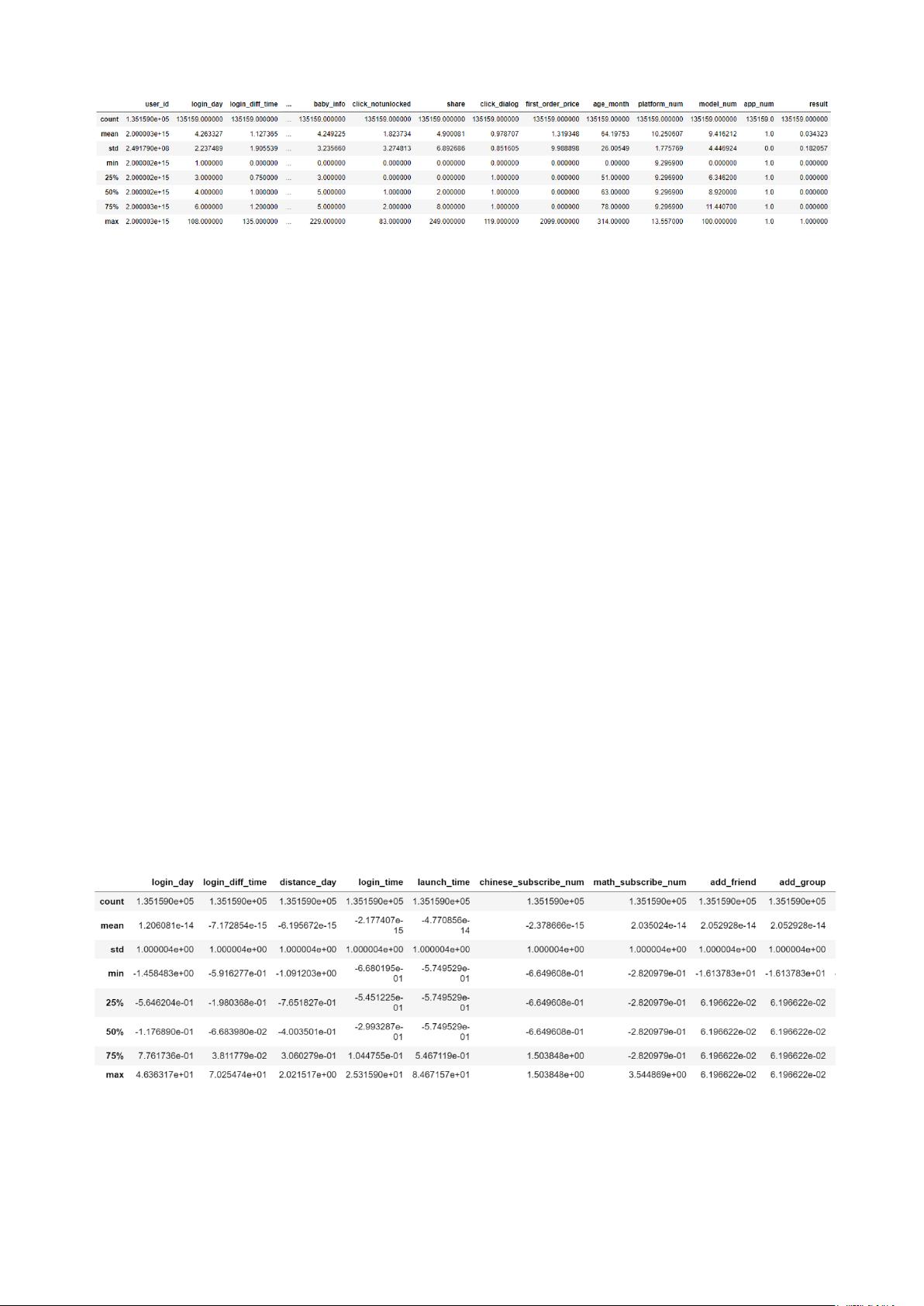
4. 数据合并
紧接着,我们将前面预处理过的数据使用 pandas 库 merge 函数对 login_day、user_info、
visit_info、result 数据进行整合,具体展示如下:
剩余37页未读,继续阅读
2024-03-10 上传
2024-03-10 上传
2024-03-10 上传
2024-03-10 上传
2024-03-10 上传

阿拉伯梳子
- 粉丝: 2461
- 资源: 5734
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
