Python网络爬虫进阶教程:实战笔记与技巧
版权申诉
79 浏览量
更新于2024-07-05
收藏 13.16MB PDF 举报
网络爬虫与数据采集笔记更新2是由雨霓同学在2020年11月19日整理的学习记录,由泠鸢组织,针对Python网络爬虫的系统教程。本笔记覆盖了从基础入门到高级进阶的多个关键知识点,旨在帮助读者掌握爬虫技术。
1. **初始阶段** (O001): 学习者将了解网络爬虫的基本概念,包括理解爬虫的工作原理和目标,以及如何开始编写简单的爬虫脚本。
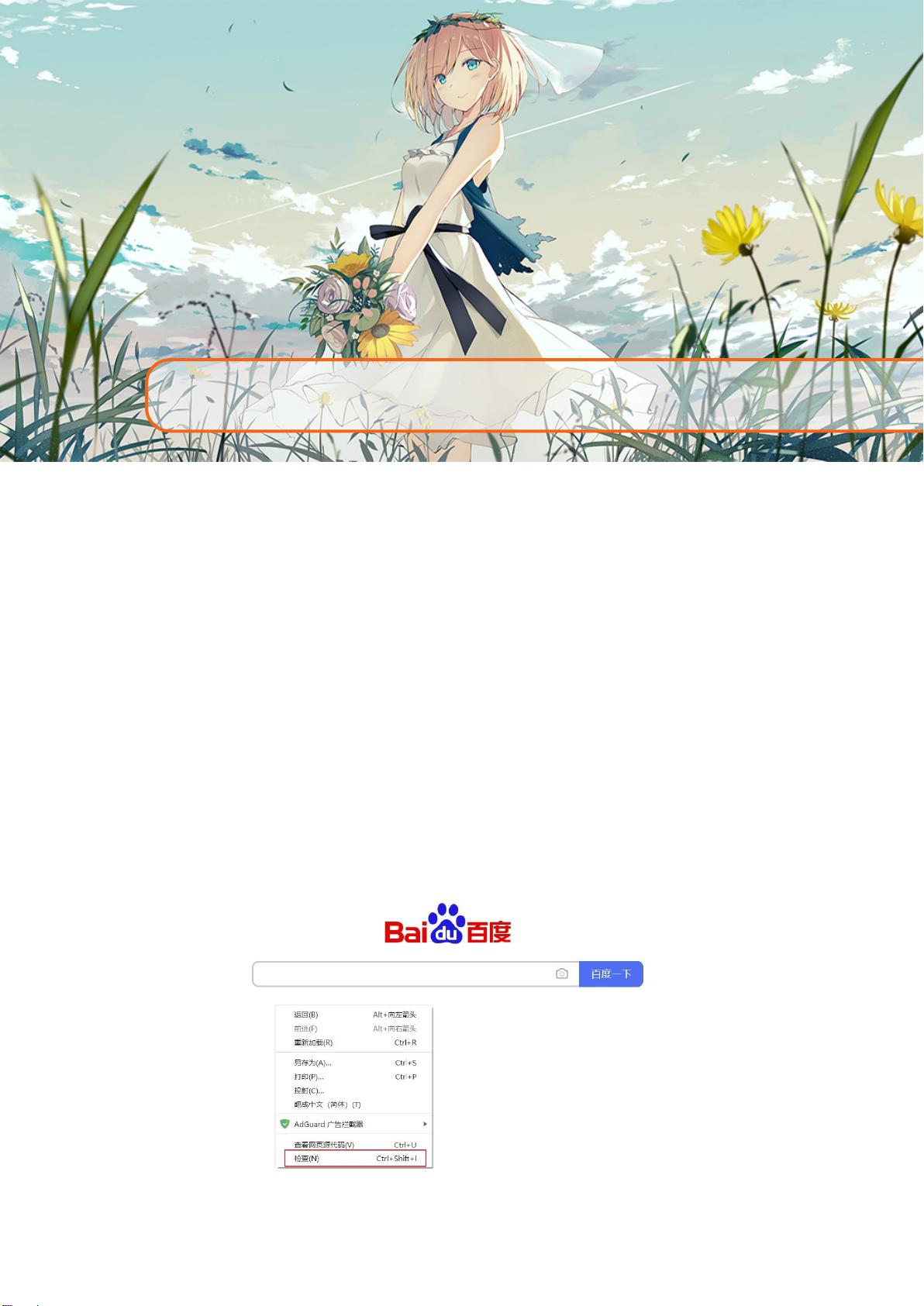
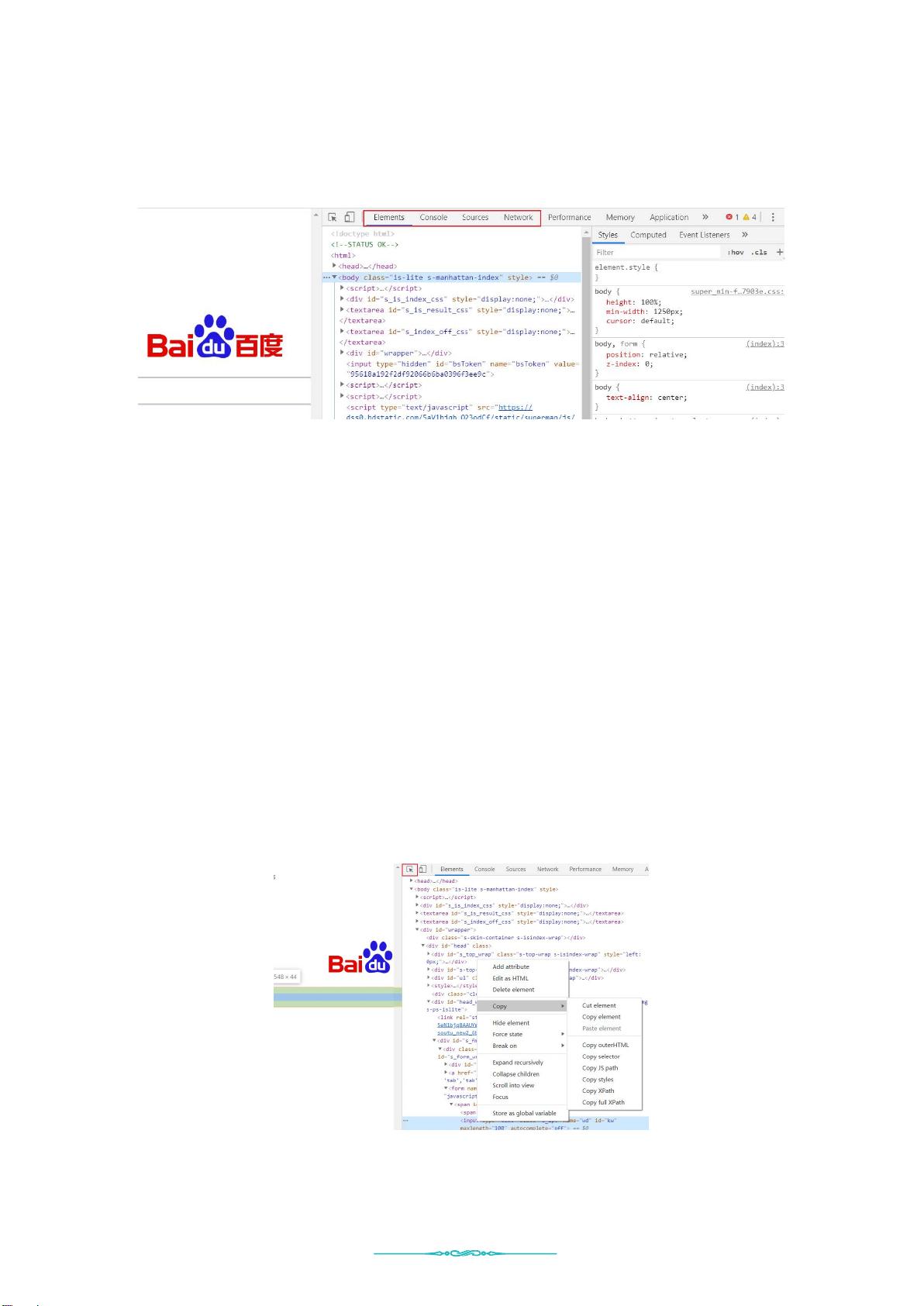
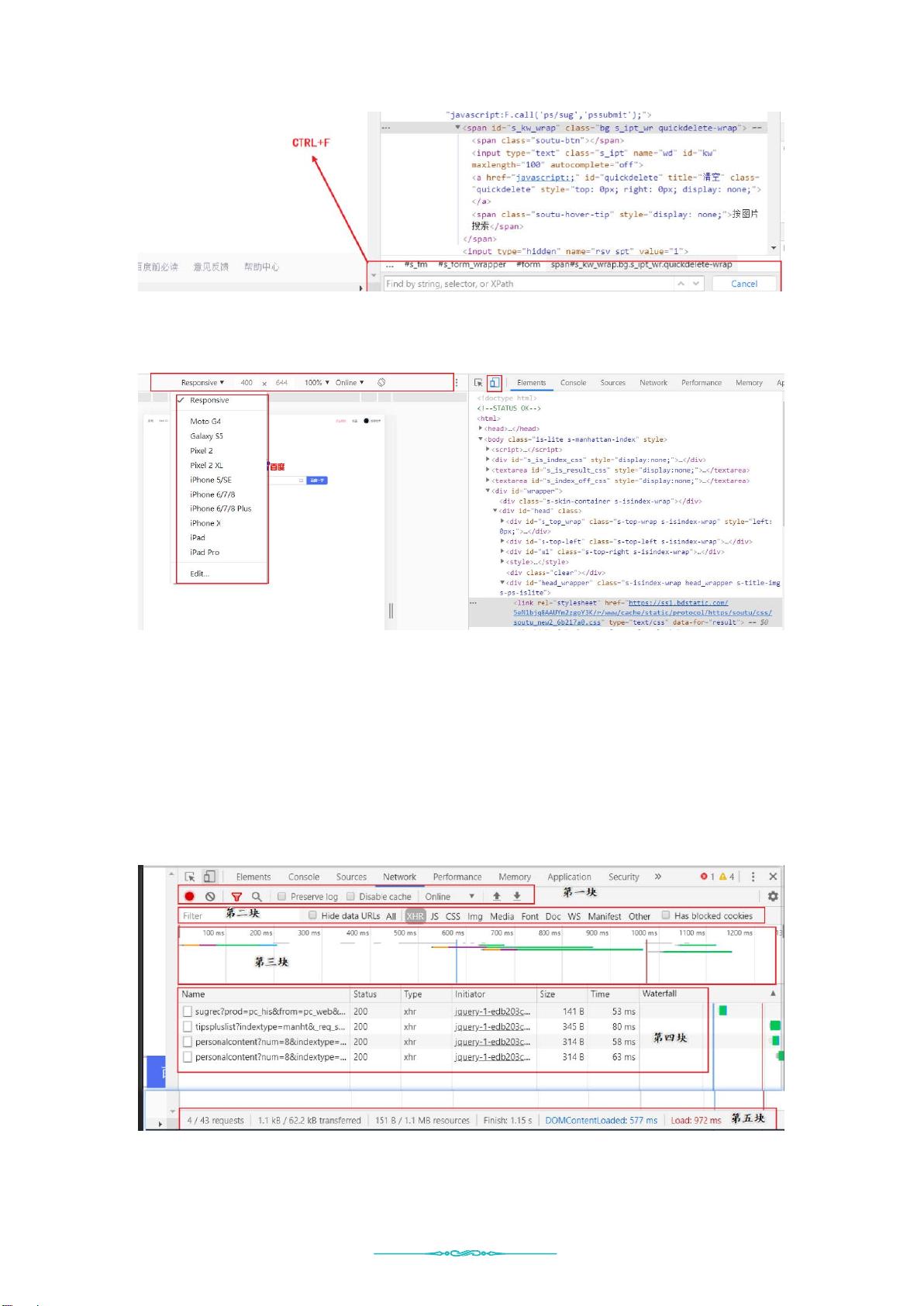
2. **浏览器开发者工具使用** (O002): 这部分介绍了如何利用浏览器开发者工具进行网络请求分析和调试,这对于理解和优化爬虫策略至关重要。
3. **HTTP与HTTPS协议** (O003): 学习者将深入理解这两种常用网络通信协议,包括它们的区别、安全性和在爬虫中的应用。
4. **Requests库基础** (O004): Requests库是Python中常用的HTTP客户端,讲解如何通过它发送HTTP请求并处理响应。
5. **XPath与lxml模块** (O005): XPath用于解析XML文档,lxml是一个高效的XML和HTML处理库,这两者结合能有效提取网页数据。
6. **正则表达式与re模块** (O006): 学习者会学习如何使用正则表达式匹配和处理网页中的特定模式,这是数据抓取的重要工具。
7. **CSS选择器与BS4库** (O007): BeautifulSoup库基于CSS选择器来解析HTML文档,是处理网页数据的常见选择。
8. **jQuery与PyQuery模块** (O008): jQuery和PyQuery是JavaScript库的Python接口,它们提供了更简洁的DOM操作方式。
9. **Json数据与Json模块** (O009): Json数据格式在爬虫中广泛应用,学习者会掌握Json模块的使用以解析和生成Json数据。
10. **数据存储** (O010-11): 包括Pandas用于数据分析和CSV文件的处理,以及如何将数据存储到关系型数据库(如MySQL)和NoSQL数据库(如MongoDB)。
11. **进阶技术** (O012-18): 提升技能,如Selenium模拟浏览器行为、多进程、多线程、协程和异步爬虫,甚至使用Scapy进行网络协议分析,以及分布式爬虫设计。
12. **APP爬虫** (O019): 针对移动应用的数据抓取,探讨如何处理App接口和权限问题。
13. **反爬虫策略** (O020): 介绍如何识别和应对网站的反爬虫机制,保护爬虫免受封禁。
在学习过程中,雨霓同学提供了多个社区资源和支持渠道,如GitHub、博客园、微信公众号、QQ群等,鼓励读者参与讨论和协作。此外,尽管存在OCR识别可能存在的问题,但这些笔记仍为学习者提供了一个实用的学习框架和指南。通过学习这些内容,读者能够逐步掌握网络爬虫和数据采集的实战技巧。

1.7 Python 爬虫相关库 – 8 –
∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼·∼· ∼·
举个例子,如果你把大众点评上的所有公开信息都抓取了下来,自己复制了一个一模
一样的网站,并且还通过这个网站获取了大量的利润,这样也是有问题的。
一般情况下,爬虫都是为了企业获利的,因此需要爬虫开发者的道德自持和企业经营
者的良知才是避免触碰法律底线的根本所在。
v 违法的爬虫
1. 爬虫不能涉及个人隐私!
“一个程序员写了个爬虫程序,整个公司 200 多人被端了。”
如果爬虫程序采集到公民的姓名、身份证件号码、通信通讯联系方式、住址、账号密
码、财产状况、行踪轨迹等个人信息,并将之用于非法途径的,则肯定构成非法获取
公民个人信息的违法行为。
也就是说你爬虫爬取信息没有问题,但不能涉及到个人的隐私问题,如果涉及了并且
通过非法途径收益了,那肯定是违法行为。
另外,还有下列三种情况,爬虫有可能违法,严重的甚至构成犯罪:
2. 爬虫程序规避网站经营者设置的反爬虫措施或者破解服务器防抓取措施,非法获取相
关信息,情节严重的,有可能构成“非法获取计算机信息系统数据罪”。
3. 爬虫程序干扰被访问的网站或系统正常运营,后果严重的,触犯刑法,构成“破坏计
算机信息系统罪”
4. 爬虫采集的信息属于公民个人信息的,有可能构成非法获取公民个人信息的违法行为,
情节严重的,有可能构成“侵犯公民个人信息罪”。
1.7 Python 爬虫相关库
v 请求库
urllib3 库
提供很多 Python 标准库里所没有的重要特性:线程安全,连接池,客户端 SSL/TLS
验证,文件分部编码上传,协助处理重复请求和 HTTP 重定位,支持压缩编码,支持
HTTP 和 SOCKS 代理,100% 测试覆盖率
urllib 库
Python 内置的 HTTP 请求库,提供一系列用于操作 URL 的功能
requests 库
基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库
selenium Selenium 是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动
作,如点击、下拉等操作,对于一些 JavaScript 渲染页面来说,这种抓取方式非常有效。
ChromeDriver
谷歌浏览器的的驱动,只有安装了浏览器驱动,才能使用 selenium 来驱动谷歌浏览器
完成相应的操作
v 解析库
正则表达式
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。正则表
达式是繁琐的,但它是强大的
lxml 的

剩余132页未读,继续阅读
2024-12-13 上传
925 浏览量
1004 浏览量
232 浏览量
383 浏览量
292 浏览量
549 浏览量
111 浏览量
416 浏览量

爱吃苹果的Jemmy
- 粉丝: 87
 我的内容管理
展开
我的内容管理
展开







最新资源
- 隐私数据清洗工具Java代码实践教程
- UML与.NET设计模式详细教程
- 多技术领域综合企业官网开发源代码包及使用指南
- C++实现简易HTTP服务端及文件处理
- 深入解析iOS TextKit图文混排技术
- Android设备间Wifi文件传输功能的实现
- ExcellenceSoft热键工具:自定义Windows快捷操作
- Ubuntu上通过脚本安装Deezer Desktop非官方指南
- CAD2007安装教程与工具包下载指南
- 如何利用Box平台和API实现代码段示例
- 揭秘SSH项目源码:实用性强,助力开发高效
- ECSHOP仿68ecshop模板开发中心:适用于2.7.3版本
- VS2012自定义图标教程与技巧
- Android新库Quiet:利用扬声器实现数据传递
- Delphi实现HTTP断点续传下载技术源码解析
- 实时情绪分析助力品牌提升与趋势追踪:交互式Web应用程序
