揭秘流处理SQL基石:Apache Beam与四大组件深度探讨
需积分: 0 196 浏览量
更新于2024-07-18
收藏 24.01MB PPTX 举报
"《流式SQL的基础》是一篇探讨了Apache Beam、Apache Calcite、Apache Kafka和Apache Flink社区中的核心理念的文章,由Tyler Akidau(Apache Beam PMC成员,Google的软件工程师)在QCon London 2018会议上分享。文章涵盖了这些开源框架在处理实时流数据时的关键概念,包括但不限于Julian Hyde、Fabian Hueske、Shaoxuan Wang、Kenn Knowles等业内专家的思考和贡献。
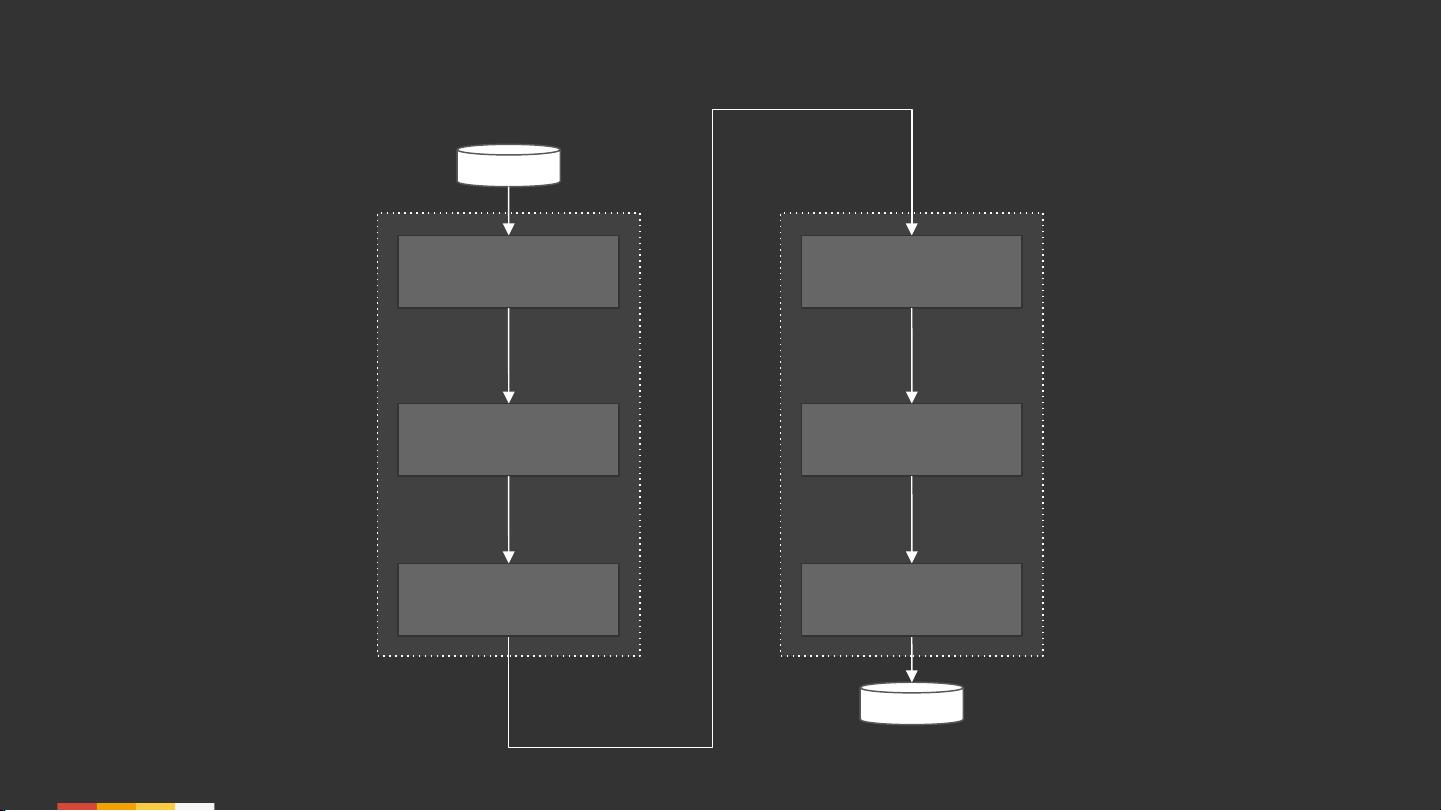
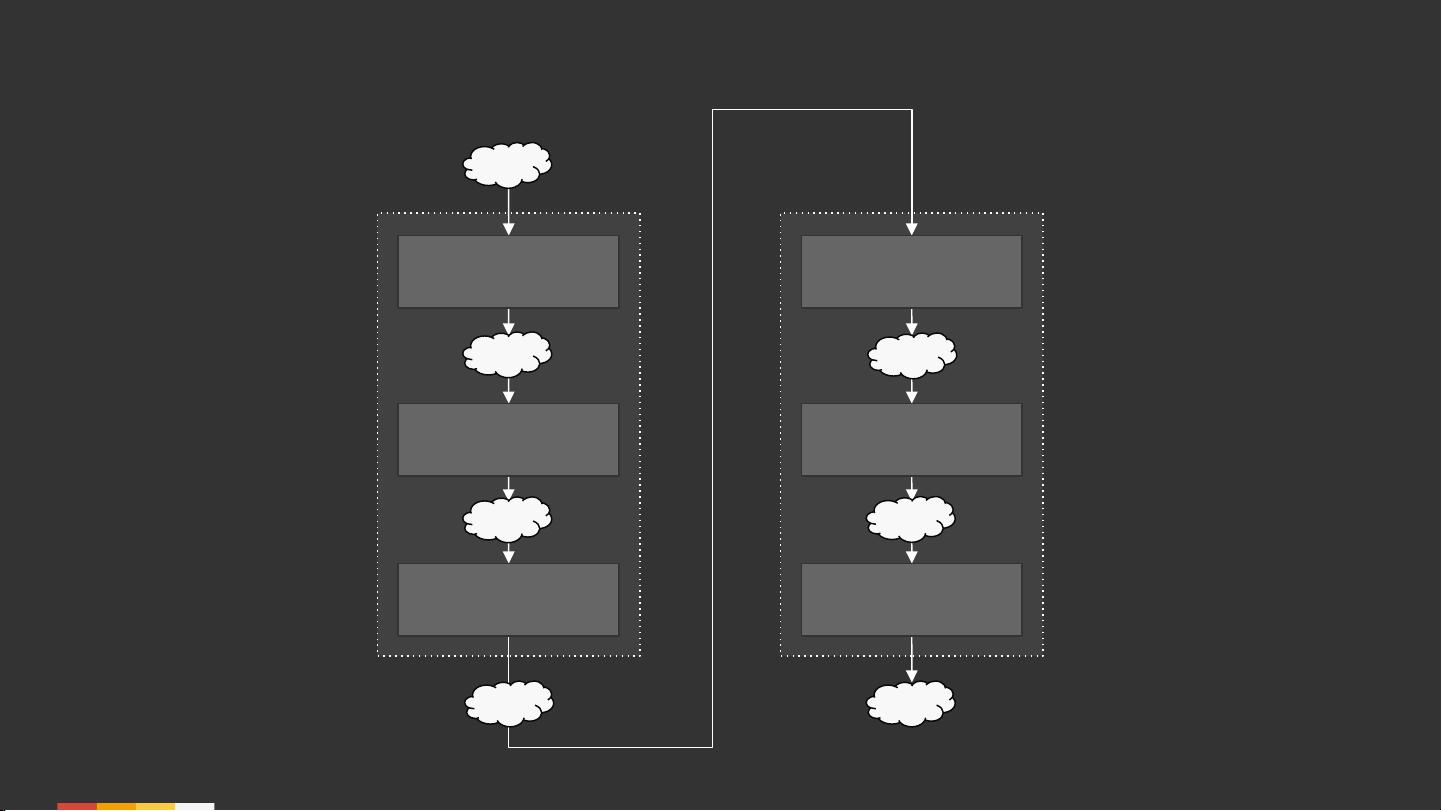
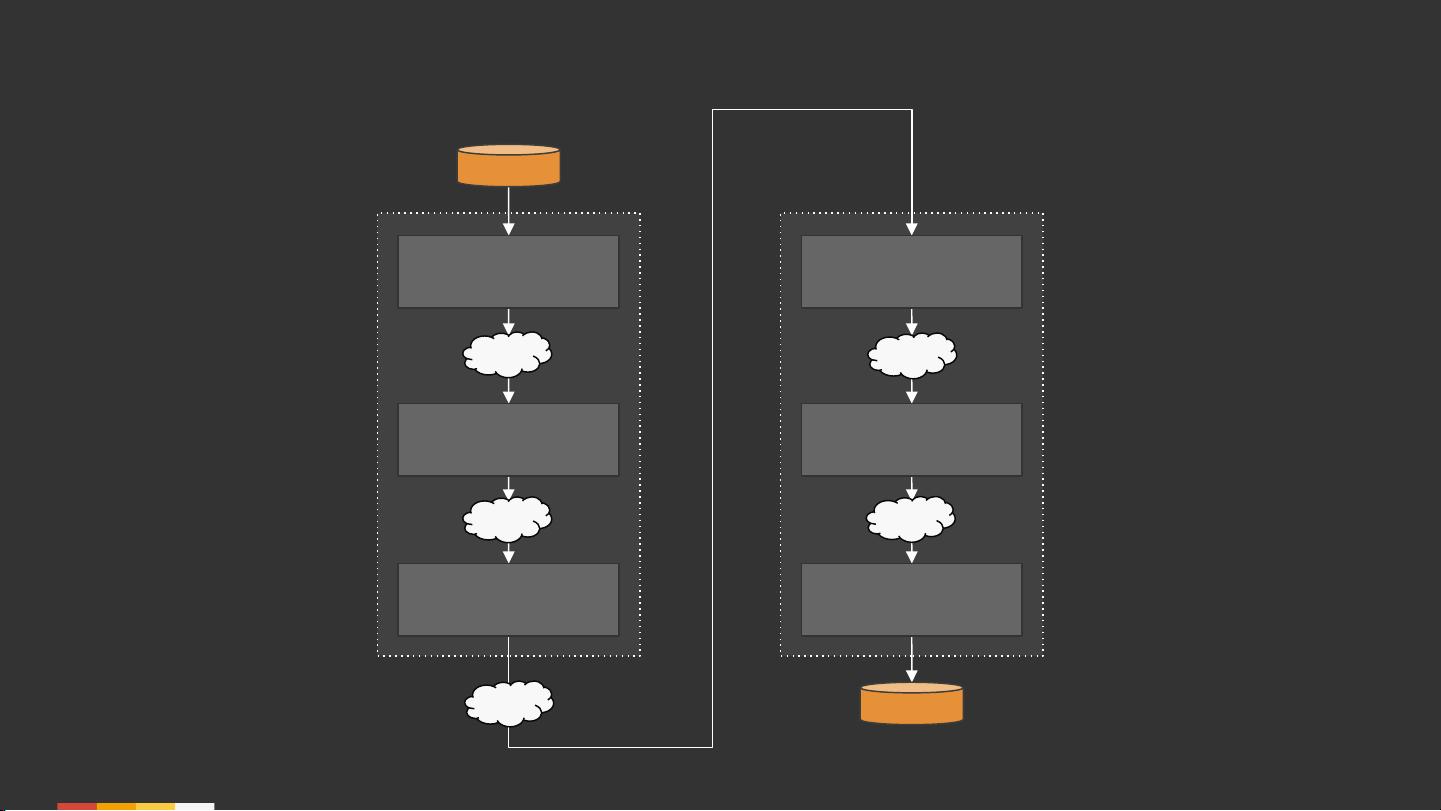
文章首先阐述了流式计算与表格理论的基本概念,指出许多现代流处理技术其实借鉴了数据库领域的长期发展成果。在这个基础部分,它提到了如何理解流数据和表格数据之间的关系,以及如何通过Apache Beam模型来处理实时数据流。流被视为不断更新的关系,而表格则代表静态的数据集合,两者之间存在着双向转换的理论:从流到表的聚合操作,以及反过来从表到流的实时更新。
在文章的第七章和第九章,深入探讨了时间变异关系的概念,即如何处理随时间变化的数据,这对于实时分析至关重要。这包括对SQL语言的扩展,使其能够适应流式环境,比如支持窗口函数、事件时间处理和持续查询等特性。
此外,文章还引用了Confluent的一些资源,如《理解流处理的意义》和《介绍Kafka Streams:使简单流处理成为可能》,强调了将数据库理论应用于实践的重要性。在实际应用中,理解流与表的相对性,以及如何在这些模型之间灵活转换,是设计高效流处理系统的关键。
《流式SQL的基础》提供了一个综合的视角,帮助读者掌握流式数据处理的核心原理和技术,以及如何利用现有的开源工具如Apache Beam、Apache Calcite等进行实时数据分析和处理。这篇内容丰富、结合实践经验的指南,对于从事IT特别是数据处理领域的专业人士具有很高的参考价值。"
276 浏览量
162 浏览量
2025-01-03 上传
2025-01-03 上传

过往记忆
- 粉丝: 4401
- 资源: 274
 我的内容管理
展开
我的内容管理
展开







