R语言与机器学习概述:数据挖掘、算法应用与实例解析
机器学习总结
在当今信息技术领域,机器学习是一种强大的工具,它使计算机系统能够通过数据自动改进其性能,无需显式编程。本篇总结涵盖了机器学习的核心概念、R语言在机器学习中的角色以及几个关键算法的应用。
R语言作为一门统计分析语言,不仅支持数据分析和可视化,还提供了丰富的环境来构建和部署机器学习模型。它拥有向量、因子(离散变量)、列表、数组、数据框和矩阵等数据结构,这些数据结构在处理不同类型的数据时尤为关键。
大数据时代的挑战在于处理海量数据,涉及的数据量可能达到Petabytes(PB)级。数据挖掘是应对这一挑战的重要手段,其中包括使用工具如Hadoop的MapReduce(MR)来进行大规模数据处理,以及通过协同过滤等算法来发现用户行为模式和兴趣。
人工智能的核心在于模拟人类智能,通过训练模型来预测和决策。在这个过程中,训练数据集用于构建模型,测试数据集则用来评估模型的准确性和泛化能力。例如,线性回归是预测模型的基础,简单线性回归只考虑一个自变量的影响,而多元线性回归则扩展到多个自变量,如保险案例中的年龄、性别、BMI、地区和吸烟等因素。
在实际应用中,确保数据的质量至关重要,如样本分布的均衡性。例如,保险案例中需要检查不同区域的样本是否足够均匀,以避免模型偏差。多元线性回归模型训练后,新来的个体数据可以通过与模型参数(w0, wn)相乘相加来预测其结果。
数据预处理是机器学习的关键步骤,包括特征工程,如将非线性关系转化为线性可处理的形式,如age^2对于年龄和费用的关系。这样做是因为线性模型假设输入和输出之间的关系是线性的,这样可以更好地适应算法要求。
此外,特征组合如bmi*smoker作为一个新的维度,是为了引入更复杂的交互效应,使得模型能够捕捉到数据中更深层次的关联。通过这样的处理,模型能更准确地反映真实世界的复杂性。
机器学习是一门综合了统计学、算法和计算机科学的技术,R语言为其提供了一个强大的工具箱。理解和掌握这些基础知识,对于在实际项目中设计、实现和优化机器学习模型至关重要。
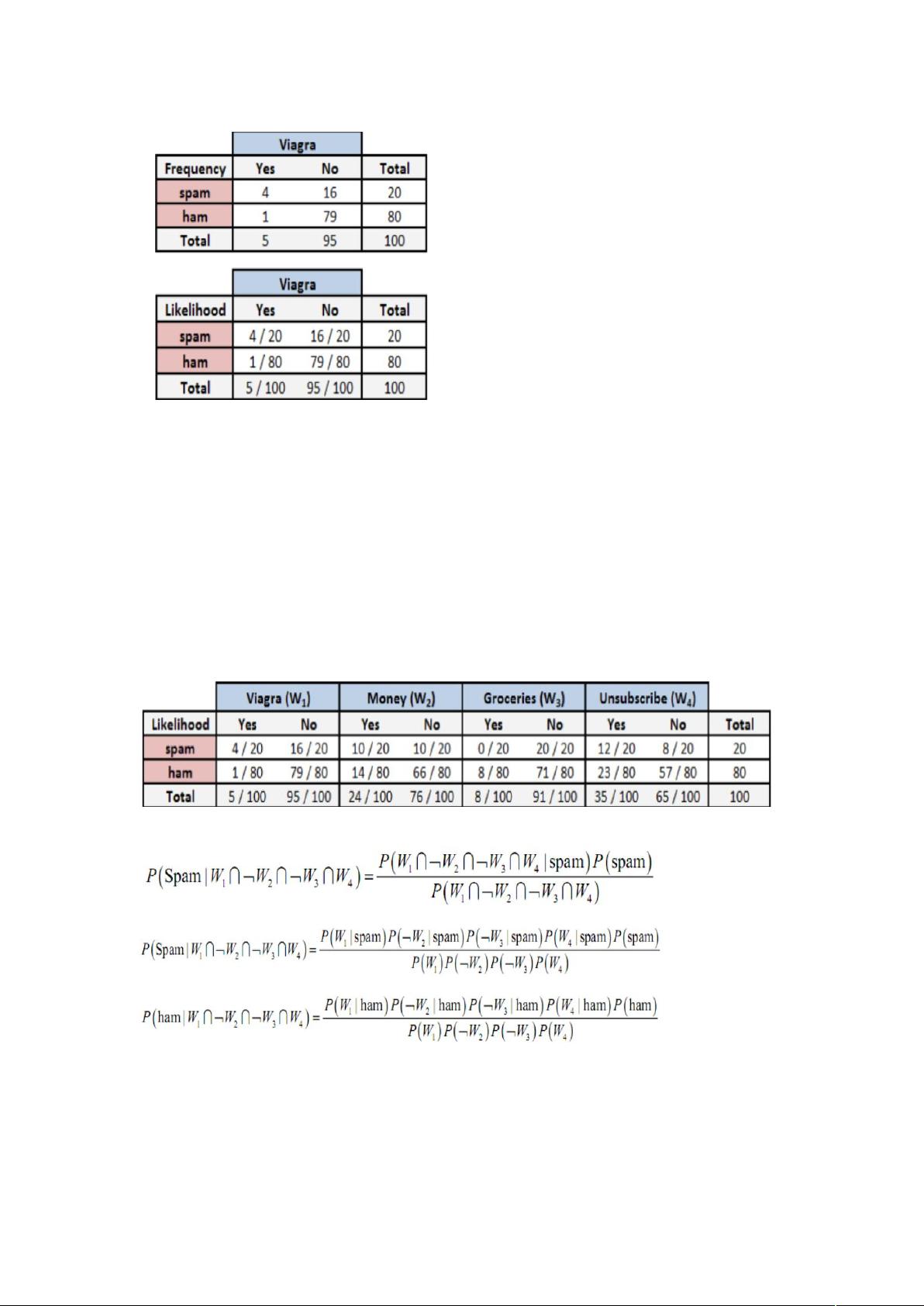
计算贝叶斯公式
• P(垃圾邮件|Viagra)=P(Viagra|垃圾邮件)*P(垃圾邮
件)/P(Viagra)=(4/20)*(20/100)/(5/100)=0.8(P(A|B)意思是发生 B 时间且发生 A
事件的概率)
• 因此,如果电子邮件含有单词 Viagra,那么该电子邮件是垃圾
邮件的概率为 80%。所以,任何含有单词 Viagra 的消息都需
要被过滤掉。
当有额外更多的特征是,这一概念如何被使用
利用贝叶斯公式,我们得到概率如下:
分母可以先忽略它,垃圾邮件的总似然为:
• (4/20)*(10/20)*(20/20)*(12/20)*(20/100)=0.012
• 非垃圾邮件的总似然为:
• (1/80)*(66/80)*(71/80)*(23/80)*(80/100)=0.002
• 将这些值转换成概率,我们只需要一步得到垃圾邮件概率为
剩余20页未读,继续阅读
2022-07-20 上传
2021-04-29 上传
2025 浏览量

Dillon_Wang
- 粉丝: 5
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
