




深入理解Java HashMap:源码解析与特性分析
5 浏览量
更新于2024-08-31
收藏 145KB PDF 举报
"深入理解Java中的HashMap类及其与HashSet的关系"
HashMap类是Java编程语言中用于实现键值对存储的重要工具,属于Java Collection Framework的一部分。它实现了Map接口,允许以键值对的形式存储数据,其中键是唯一的。HashMap类的工作原理基于哈希表,通过哈希函数快速定位数据,提供高效的插入、删除和查找操作。
首先,HashMap与HashSet之间的关系值得一提。HashSet是Set接口的一个实现,它不包含重复元素,且没有顺序。HashSet内部使用HashMap来存储元素,因为哈希存储机制可以快速定位元素,确保高效的添加和查找。HashSet中每个元素被视为一个键,其对应的值为null。
HashMap的基本特性如下:
1. **允许null值**:HashMap允许键和值为null,这是与Hashtable的一个显著区别。Hashtable不接受null键和值。
2. **线程安全性**:HashMap是非线程安全的,这意味着在多线程环境中,如果不采取同步措施,可能会出现数据不一致的问题。相反,Hashtable是线程安全的,适合在多线程环境下使用。
3. **元素顺序**:HashMap中的元素顺序不是固定的,特别是在容量调整(resize)时,元素的位置可能会改变。这与LinkedHashMap不同,后者保持插入顺序或访问顺序。
4. **遍历效率**:遍历HashMap的时间复杂度与容量(capacity)和元素数量(size)有关。为了提高遍历效率,应适当地设置初始容量和负载因子(load factor),以避免过多的哈希冲突和不必要的扩容操作。
5. **fail-fast机制**:当HashMap在迭代过程中被修改(除了迭代器自身的remove()方法),迭代器会抛出ConcurrentModificationException,这是一种fail-fast行为,以防止数据的不一致性。
HashMap的数据结构主要由数组和链表组成。数组的每个元素称为桶(bucket),每个桶可能包含一个或多个键值对,通过链表链接。当哈希函数将键映射到相同的索引时,就会发生哈希冲突,此时键值对会被链接到同一个桶的链表中。
插入操作时,HashMap首先计算键的哈希值,然后将键值对放入对应索引的桶中。如果桶已满,就会形成链表。查找和删除操作也依赖于哈希函数,找到正确的桶后,通过键的equals()方法在链表中找到目标键值对。
为了优化性能,HashMap有一个负载因子,默认值为0.75。当元素数量达到容量的负载因子时,HashMap会自动扩容,通常会将容量翻倍,以减少哈希冲突的概率,保持较低的负载系数,从而维持较好的性能。
HashMap是Java中一个非常重要的数据结构,适用于需要快速查找、插入和删除操作的场景。然而,在多线程环境中,开发者需要自行处理同步问题,或者使用线程安全的替代品如ConcurrentHashMap。了解HashMap的工作原理和特性,有助于更好地利用它来解决实际问题。
全面解析全面解析Java中的中的HashMap类类
HashMap类为Java提供了键值对应的map类型,本文将从源码角度全面解析Java中的HashMap类,同时包括其各
种常用操作方法等,欢迎参考与借鉴
HashMap 和 HashSet 是 Java Collection Framework 的两个重要成员,其中 HashMap 是 Map 接口的常用实现类,HashSet
是 Set 接口的常用实现类。虽然 HashMap 和 HashSet 实现的接口规范不同,但它们底层的 Hash 存储机制完全一样,甚至
HashSet 本身就采用 HashMap 来实现的。
实际上,HashSet 和 HashMap 之间有很多相似之处,对于 HashSet 而言,系统采用 Hash 算法决定集合元素的存储位置,
这样可以保证能快速存、取集合元素;对于 HashMap 而言,系统 key-value 当成一个整体进行处理,系统总是根据 Hash 算
法来计算 key-value 的存储位置,这样可以保证能快速存、取 Map 的 key-value 对。
在介绍集合存储之前需要指出一点:虽然集合号称存储的是 Java 对象,但实际上并不会真正将 Java 对象放入 Set 集合中,
只是在 Set 集合中保留这些对象的引用而言。也就是说:Java 集合实际上是多个引用变量所组成的集合,这些引用变量指向
实际的 Java 对象。
一、一、HashMap的基本特性的基本特性
读完JDK源码HashMap.class中的注释部分,可以总结出很多HashMap的特性。
HashMap允许key与value都为null, 而Hashtable是不允许的。
HashMap是线程不安全的, 而Hashtable是线程安全的
HashMap中的元素顺序不是一直不变的,随着时间的推移,同一元素的位置也可能改变(resize的情况)
遍历HashMap的时间复杂度与其的容量(capacity)和现有元素的个数(size)成正比。如果要保证遍历的高效性,初始容量
(capacity)不能设置太高或者平衡因子(load factor)不能设置太低。
与之前的相关List同样, 由于HashMap是线程不安全的, 因此迭代器在迭代过程中试图做容器结构上的改变的时候, 会产生
fail-fast。通过Collections.synchronizedMap(HashMap)可以得到一个同步的HashMap
二、二、Hash table 数据结构分析数据结构分析
Hash table(散列表,哈希表),是根据关键字而直接访问内存存储位置的数据结构。也就是说散列表建立了关键字和存储地址之
间的一种直接映射
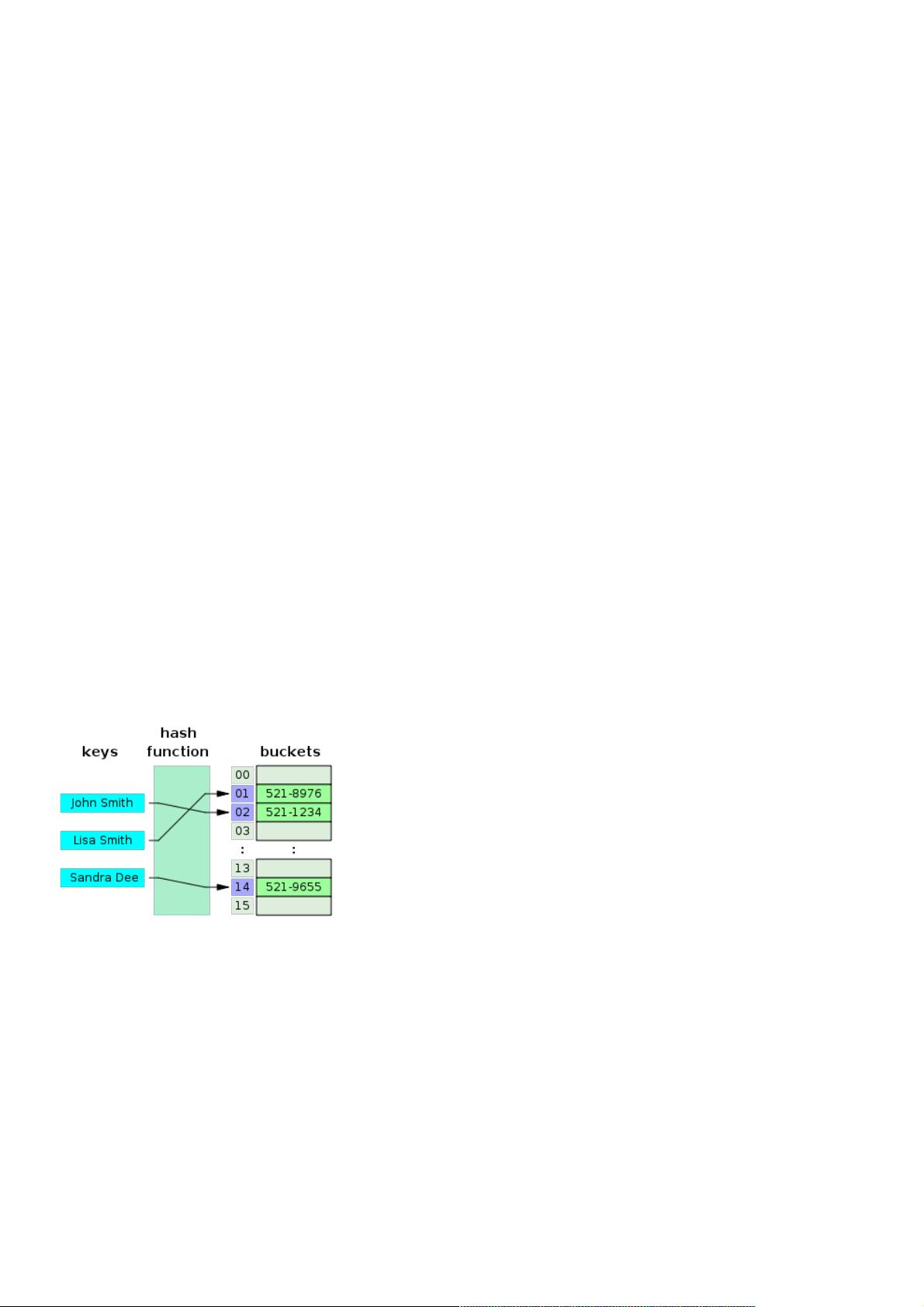
如下图, key经过散列函数得到buckets的一个索引位置。
通过散列函数获取index不可避免会出现相同的情况,也就是冲突。下面简单介绍几种解决冲突的方法:
Open addressing(开放定址法):此方法的基本思想就是遇到冲突时,顺序扫描表下N个位置,如果有空闲就填入。具体算法不
再说明,下面是示意图:
下载后可阅读完整内容,剩余6页未读,立即下载
555 浏览量
129 浏览量
点击了解资源详情
208 浏览量
378 浏览量
186 浏览量
178 浏览量
190 浏览量

weixin_38631729
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- Weka-3-7-9jre与libsvm集成安装使用指南
- XFileUpload:实现多文件和大文件上传的ASP.Net控件
- Zuerbig字体文件介绍与下载
- Loja-frontend:TypeScript前端开发详解
- 局域网计算机无法访问的解决方案
- 下载支持:亲测可用的apache-tomcat-8.0.37版本
- KX唱歌效果 - 体验YY唱歌的绝妙之处
- ADI推出全新差分放大器设计工具ADI Diff Amp Calculator
- 一键式SVN服务器绿色安装包使用教程
- JavaScript赛车游戏开发教程
- 蓝牙通信与控制技术详解
- C++实用算法集锦:从基础到高级技巧
- 批量视频截图软件:自定义截图数与文件夹读取
- CurrPorts汉化版:全面监控本地端口与进程信息
- Zladdi 字体:创意压缩包内含GIF与TTF格式文件
- WWW2Image1.7汉化绿色版:网页转图片与缩略图功能






















