
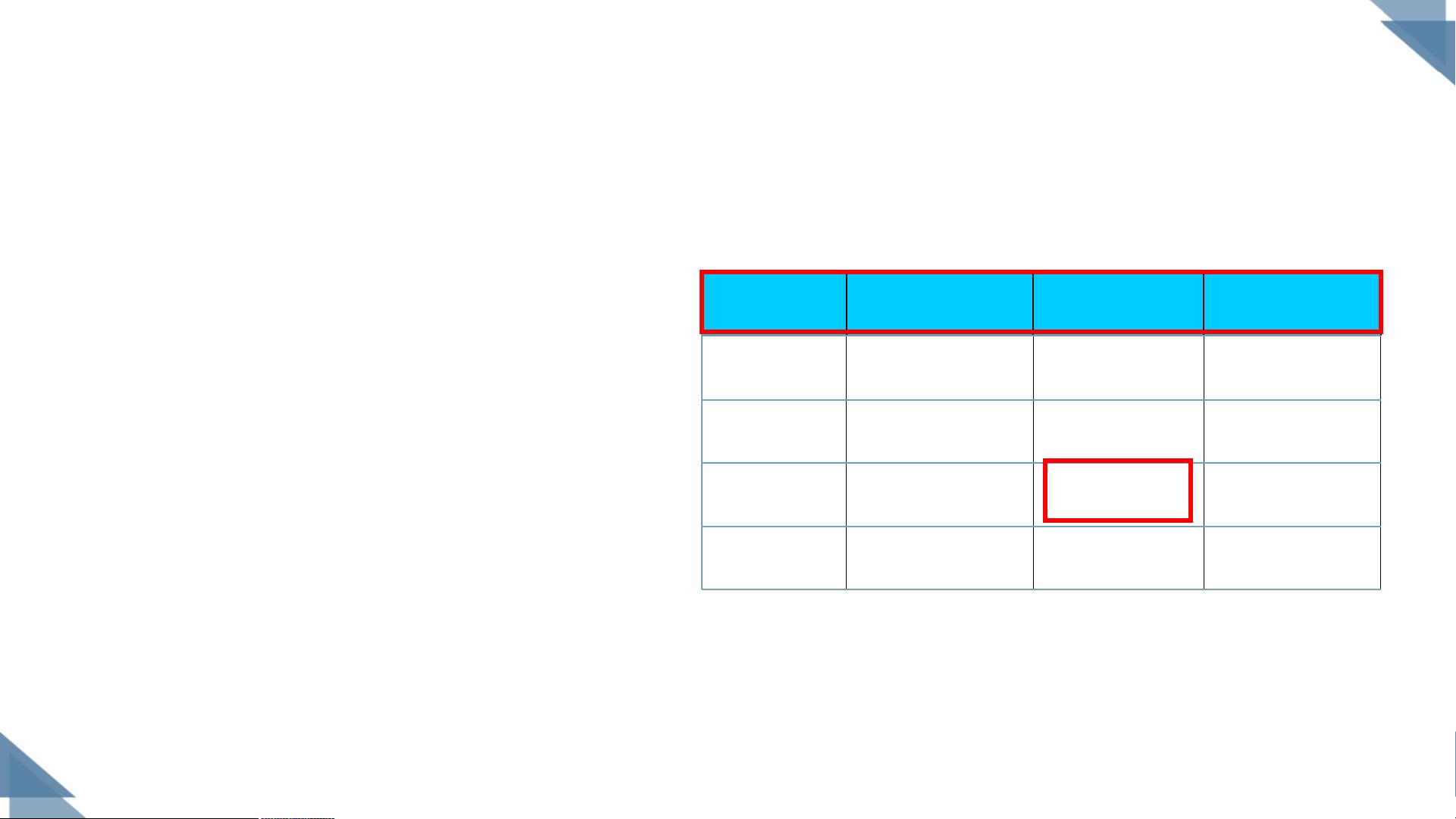
基础知识
色泽 根蒂 敲声 好瓜
青绿 蜷缩 浊响 是
乌黑 蜷缩 浊响 是
青绿 硬挺 清脆 否
乌黑 稍蜷 沉闷 否
• 输入空间,属性空间,样本空间
• 数据集;训练,测试
• 示例(instance),样例(example)
• 样本(sample)
• 属性(attribute), 特征(feature); 属性值
• 特征向量(featurevector)
剩余16页未读,继续阅读

知识世界
- 粉丝: 368
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


