




最大熵模型详解:NLP中的应用与算法步骤
下载需积分: 46 | PPT格式 | 1.05MB |
更新于2024-07-11
| 14 浏览量 | 举报
"本资源是一份关于最大熵模型在自然语言处理中的应用的详细讲解PPT,主要涵盖了最大熵模型的概念、计算方法、特征选择以及实际应用案例。"
最大熵模型是一种在统计学习中广泛使用的概率模型,特别是在自然语言处理领域。它的核心思想是寻找所有可能模型中不确定性最大的模型,即熵最大的模型。熵在信息论中表示的是一个系统的不确定性,最大熵模型通过最大化熵来避免过拟合,确保模型的泛化能力。
自然语言处理(NLP)涉及对人类语言的理解和生成,包括词性标注、句法分析、语义理解等多个任务。在NLP中,最大熵模型常用于解决诸如词性标注这样的序列标注问题。例如,给定一段文本,我们需要为每个词分配一个合适的词性标签。这可以看作是一个随机过程,其中每个词的词性依赖于它前面出现的词和已有词性的信息。
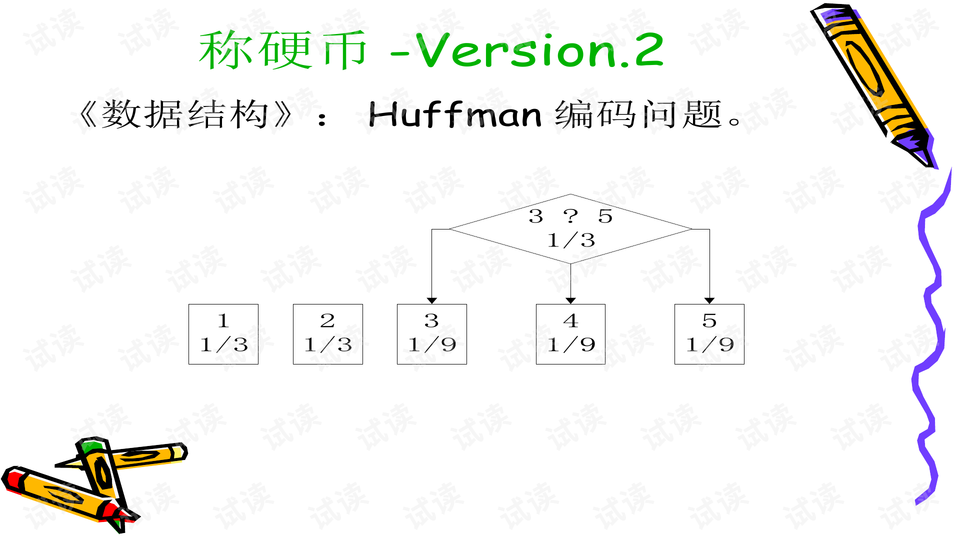
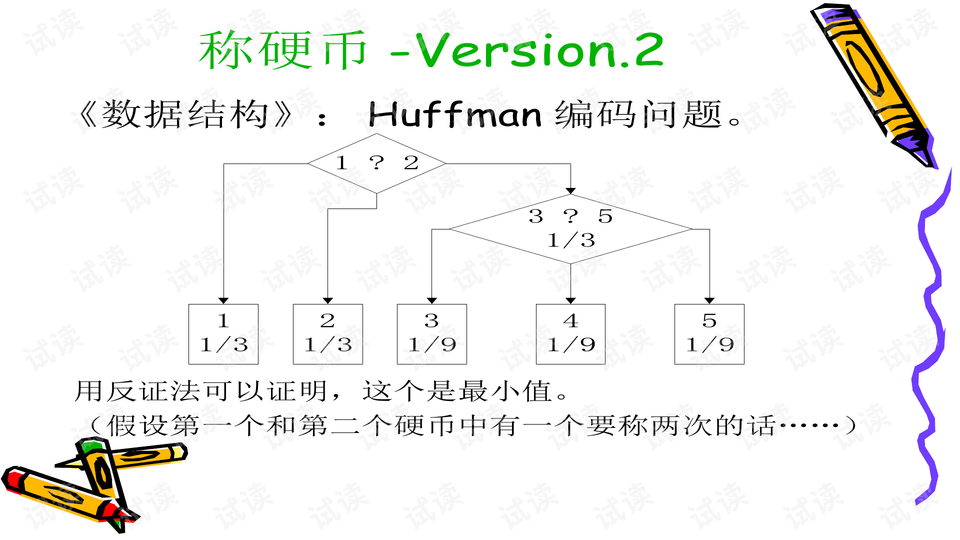
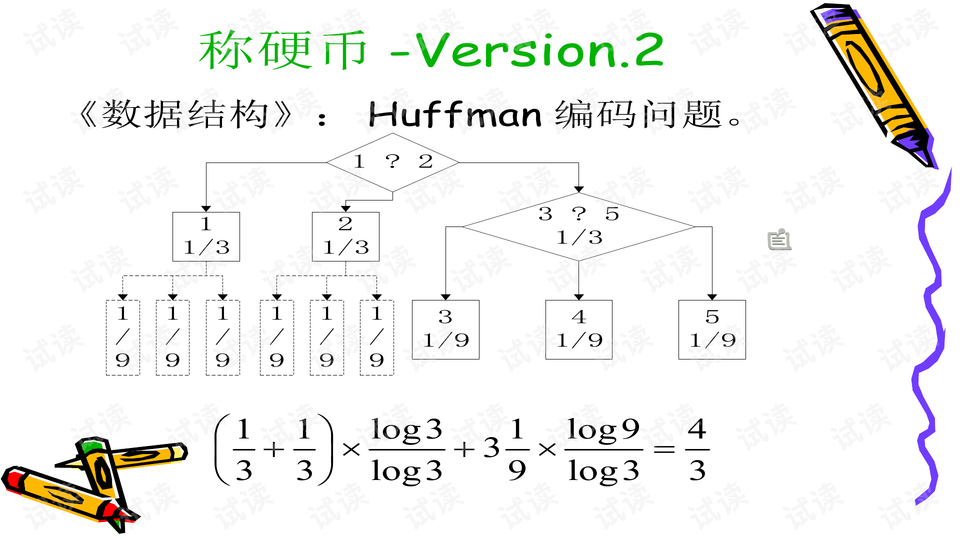
在最大熵模型的构建过程中,首先需要确定一组有效的特征集合E。初始时,特征集为空,模型的预测概率均匀分布。然后,通过迭代的方式逐步增加特征,每次增加一个特征fi,计算包含该特征的新模型的最大熵Hi(pi*)。这个过程会重复K次,每次都选择使模型熵增加最少的特征fm加入到E中,直到达到预设的迭代次数或满足特定的停止条件。
解决最大熵模型通常涉及到非线性规划,这可能包括求解对偶问题和最大似然估计。对偶问题是对原问题的一种等价形式,有时更容易求解。最大似然估计则是寻找使得数据出现概率最大的模型参数。
特征选取是最大熵模型中的关键步骤。特征应能够有效地捕获输入数据的关键信息,同时保持模型的简洁性,防止过拟合。特征可以是词的共现、词的位置信息、词的n-gram等。在NLP中,特征设计往往需要对语言学知识有深入理解。
应用实例可能包括命名实体识别、情感分析等,这些任务都要求模型能够根据上下文信息做出合理的判断。例如,在情感分析中,模型需要识别出文本中的情感倾向,而词性标注可以帮助确定词的情感色彩。
总结来说,最大熵模型是一种在自然语言处理中广泛应用的统计学习方法,它通过最大化熵来平衡模型复杂性和泛化性能,同时特征选择和优化技术对于模型的性能至关重要。通过理解和掌握这一模型,可以在实际NLP任务中构建更精准的预测系统。


相关推荐






郑云山
- 粉丝: 28
 我的内容管理
展开
我的内容管理
展开








最新资源
- C语言与Qt打造的LightMd Markdown编辑器
- 易语言实现QQ农场时间模块教程
- Oracle分区表在UNIX系统下的导出方法与技巧
- 超级兔子v12.2.4.0正式发布,全面优化电脑系统性能
- 用Ant和JUnit进行简单单元测试的实践教程
- 煤矿通风监控系统示意图说明书
- 免费超大文本查看工具LTFViewr5u使用体验
- STM32F4双模式温控风扇升级LCD显示教程
- Honeycam v1.2:简单易用的GIF动图制作工具
- 商用级别快速内存搜索算法支持32/64位与通配符
- 开源计分器项目完整源代码及相关开发指南
- C#系统监控软件实现全盘文件及子文件夹监控
- Windows平台下使用libusb传输YUV数据的方法
- Visual C++网络控制机器人编程教程
- NPOI 2.3.0.0发布,全新.NET库支持dotnet2和dotnet4
- Linux服务器搭建全方位指南






















