LightRNN:节省内存与计算资源的循环神经网络
需积分: 10 105 浏览量
更新于2024-07-19
收藏 766KB PDF 举报
“LightRNN: Memory and Computation-Efficient Recurrent Neural Networks PPT”
LightRNN是一种针对大规模文本语料库设计的高效且节省内存的循环神经网络(RNN)。传统的RNN模型在处理大量数据时面临模型过大、训练速度慢的问题。LightRNN通过创新的词向量表示方法,解决了这一难题。
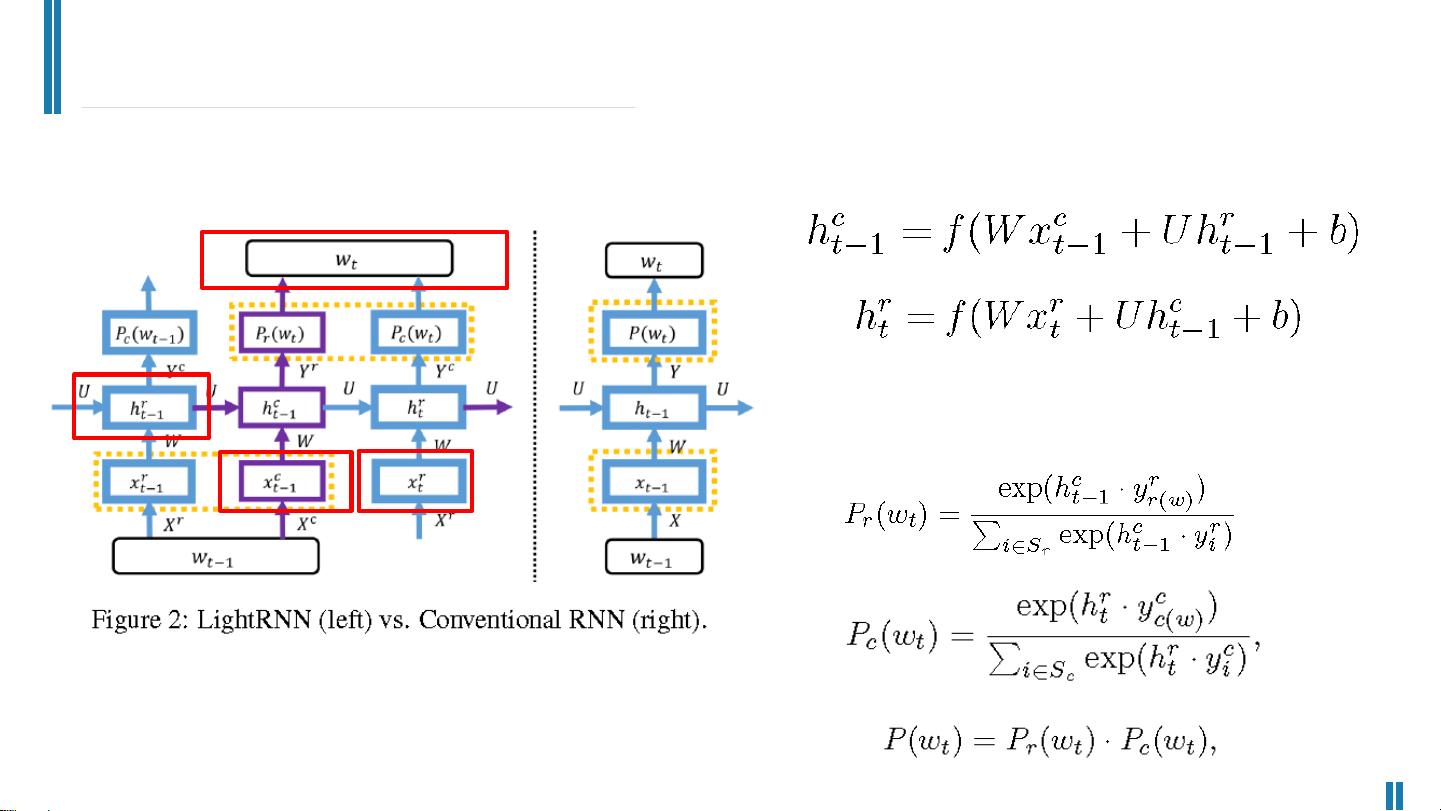
在RNN中,语言建模是其核心任务之一,它通过输入嵌入矩阵将one-hot编码的词转换为词向量,再通过输出嵌入矩阵将隐藏层的状态映射到词汇表,预测下一个词的可能性。然而,当词汇表非常庞大(如包含上千万个词)且每个词向量有1024维时,输入和输出嵌入矩阵的大小会变得极其可观,可能导致模型尺寸超过200亿个参数,远超现代GPU的内存限制。
为了解决这个问题,LightRNN提出了一种二分量共享词向量的方法。它将词汇表中的每个词映射到一个二维表格中,每行与一个向量相关联,每列与另一个向量关联。这样,每个行中的词共享同一个行向量,每列中的词共享同一个列向量,只需2 * √|V|个向量就能表示|V|个词,极大地减少了模型的大小。例如,对于1000万词汇量的模型,原本需要20亿个参数,现在只需要大约141,421个向量(假设|V|=10^6,√|V|≈1000)。
在计算隐藏状态向量时,LightRNN与标准RNN相比,其输入和输出词嵌入矩阵的维度保持不变,但整体大小显著减小。由于模型尺寸的减少,LightRNN在训练过程中能更有效地利用有限的GPU内存,从而加快训练速度,同时保持或提高模型的性能。
为了生成最优的词分配,LightRNN采用了bootstrap方法。首先,词被随机分配到词表中,然后训练LightRNN模型直到收敛。如果满足预设的停止条件(如达到最大迭代次数或困惑度阈值),则结束训练;否则,固定词向量,并根据损失函数最小化的原则调整词在词表中的位置,再重复训练过程。通过这个迭代优化的过程,可以生成一个高效的词分配表,进一步优化模型性能。
LightRNN通过独特的词向量表示和优化的训练策略,实现了在大规模语言建模任务中模型尺寸的大幅度压缩,提高了训练效率,同时也为在资源有限的环境中应用RNN模型提供了可能。
LightRNN
隐藏状态向量计算:
输出w
t
的概率:
输出
输入
剩余18页未读,继续阅读
2021-04-28 上传
2012-11-21 上传
2012-02-18 上传
2021-02-11 上传
2021-05-29 上传
2021-03-08 上传
2017-10-23 上传
2021-05-13 上传
2021-06-20 上传

immoshi
- 粉丝: 48
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
