Kafka面试题解析:数据一致性原理及应用 解析实例 深度解读【最新】
需积分: 3 150 浏览量
更新于2024-01-21
收藏 565KB DOCX 举报
Kafka是一个高性能、可扩展的分布式消息队列系统,被广泛应用于大数据领域。在Kafka的面试中,数据一致性原理是一个重要的考点。本文将从分区副本、ISR列表、高水位线等方面介绍Kafka的数据一致性原理。
在Kafka中,每个分区都有多个副本,其中一个副本被选举为Leader,其余副本则是Followers。数据一致性的目标是确保不论是老的Leader还是新选举的Leader,Consumer都能读取到一致的数据。
假设一个分区的副本数为3,副本0是Leader,副本1和副本2是Followers,并且在ISR列表(In-Sync Replicas)里面。假设副本0已经写入了Message4,但是Consumer只能读取到Message2。这是因为所有的ISR都同步了Message2,只有高水位线以上的消息才能支持Consumer的读取。
高水位线取决于ISR列表里偏移量最小的分区,对应于副本2。这个原理类似于木桶原理,只有足够多的副本复制了消息,这些消息才被认为是"安全的"。如果Leader发生崩溃,另一个副本成为新的Leader,那么这些尚未复制的消息很可能会丢失。如果允许消费者读取这些消息,可能会破坏数据的一致性。
举个例子,一个消费者从当前Leader(副本0)读取并处理了Message4,这个时候Leader挂掉了,选举了副本1为新的Leader,这时另一个消费者再去从新Leader读取数据,但由于Message4尚未被复制到副本1,这个消费者将无法读取到Message4,这会破坏数据的一致性。
为了保证数据的一致性,Kafka引入了ISR列表的机制。ISR列表是一个有序的副本列表,只有在ISR列表中的副本才能参与数据的读写。当副本从ISR列表中移除时,它将无法参与数据的读写。只有当副本恢复并追赶上Leader的进度时,才能重新加入ISR列表。
通过ISR列表的机制,Kafka确保了数据的可靠性和一致性。只有足够多的副本复制了消息,并且ISR列表中的副本均已同步了这些消息,这些消息才会被认为是"安全的",可以供Consumer进行读取。
总结来说,Kafka的数据一致性原理通过ISR列表的机制来保证。只有在ISR列表中的副本才能参与数据的读写,确保了不论是老的Leader还是新选举的Leader,Consumer都能读到一致的数据。通过高水位线的机制,Kafka可以确定可靠和安全的消息,避免了数据丢失和一致性的破坏。
以上就是对Kafka数据一致性原理的总结,希望能对读者理解Kafka的一致性机制有所帮助。
这个删除只是标记这个主题删除,并不是立即删除。在重启 kafka 之后才会删除。
也可以在 server.propertise 中配置 delete.topic.enable=true 表示立即删除
上述命令必须有环境变量
8、 kafka 的消费者是 pull(拉)还是 push(推)模式,这种模式有什么好处?
producer 将消息推送到 broker,consumer 从 broker 拉取消息。
优点
pull 方式 consumer 能自己决定是否批量拉取,拉取速度可控。而 push 模式的速度由 broker
决定,过于依赖 broker 性能,速度太快造成消费者崩溃,太慢又浪费性能。
缺点
如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询,直到新消息到到
达。为了避免这点,Kafka 有个参数(timeout)可以让 consumer 阻塞知道新消息到达(当
然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发送)。
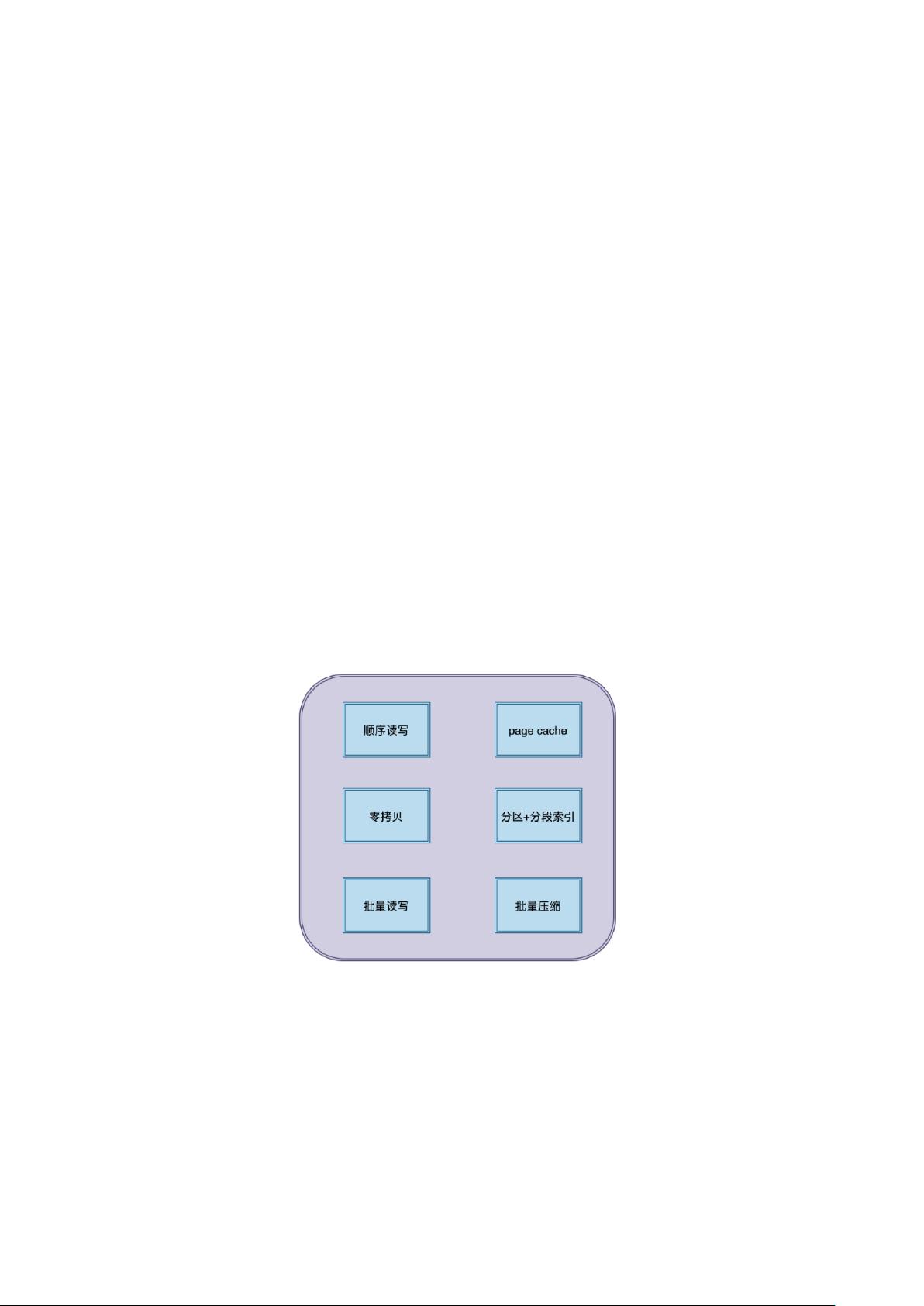
9、 kafka 为什么这么快?
1.顺序读写磁盘分为顺序读写与随机读写,基于磁盘的随机读写确实很慢,但磁盘的顺序读
写性能却很高,kafka 这里采用的就是顺序读写。
2.Page Cache 为了优化读写性能,Kafka 利用了操作系统本身的 Page Cache,就是利用操作
系统自身的内存而不是 JVM 空间内存。
3.零拷贝 Kafka 使用了零拷贝技术,也就是直接将数据从内核空间的读缓冲区直接拷贝到内
核空间的 socket 缓冲区,然后再写入到 NIC 缓冲区,避免了在内核空间和用户空间之间
穿梭。
4.分区分段+索引 Kafka 的 message 是按 topic 分 类存储的,topic 中的数据又是按照一个
剩余16页未读,继续阅读
2023-04-04 上传
2023-04-04 上传
2023-04-04 上传
2020-09-17 上传
2021-11-18 上传
2024-01-30 上传
2024-01-30 上传
2024-01-31 上传

中本王
- 粉丝: 171
- 资源: 320
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
