Tree Echo State Networks for Structured Data Learning
需积分: 14 172 浏览量
更新于2024-07-17
收藏 1.01MB PDF 举报
"这篇资源是关于 Extreme Learning Machine (ELM) 的一篇研究论文,具体讨论了 Tree Echo State Networks (Tree ESN)。论文由 Claudio Gallicchio 和 Alessio Michelin 在2013年发表在《Neurocomputing》上,主要探讨了树结构的回声状态网络在结构化数据学习中的应用。ELM是一种快速且有效的机器学习算法,而Tree ESN则是其在树形结构数据上的扩展。"
**极端学习机(Extreme Learning Machine, ELM)**
ELM是一种单层隐藏神经网络的学习方法,它的特点是隐层节点的权重在训练过程中不需要被优化。ELM通过随机初始化隐层节点的权重,然后利用线性代数的方法快速求解输出层权重,从而实现高效的学习过程。这种方法避免了传统的反向传播算法的复杂性,适用于大量输入输出数据的快速训练。
**回声状态网络(Echo State Network, ESN)**
回声状态网络是 reservoir computing 的一种形式,其核心思想是创建一个动态系统(称为“reservoir”),它能够保留过去的输入信息并产生复杂的内部状态。ESN的输入层接收外部信号,而输出层的权重是通过训练确定的,用于将reservoir的状态转换为预测或分类结果。ESN的隐层权重通常是随机生成且固定不变的,只有输出层权重需要训练。
**树回声状态网络(Tree ESN)**
在该论文中,作者提出了Tree ESN,这是一种针对树结构数据的扩展。传统的ESN处理的是线性序列数据,而Tree ESN则能够处理具有层次结构的数据。树状结构允许网络更好地捕获数据之间的关系,特别是在处理具有层级关系的问题时,如语义分析、树形图的分析等。Tree ESN的内部状态更新机制考虑到了树结构的特点,能够有效地学习和处理非线性关系。
**马尔科夫特性与状态映射**
文章还讨论了树结构下的reservoir动态的马尔科夫特性,这表明Tree ESN的状态转移函数具有收缩性,从而确保了网络行为的稳定性和可预测性。此外,作者研究了两种状态映射函数,这些函数将Tree ESN的树结构状态转换为固定大小的特征表示,以便进行分类或回归任务。
**应用场景**
Tree ESN的应用可能包括自然语言处理(如句法分析、词性标注)、图像分析(如分层图像分割)、生物信息学(如基因树的分析)等,任何需要处理具有内在层次关系问题的领域都可能是Tree ESN的有效应用场合。
这篇论文提供了对Tree ESN模型的深入理解,展示了如何在结构化数据中利用这种技术进行高效学习,并探讨了其内在的数学特性,对于研究和应用ELM及树结构数据处理的读者具有很高的参考价值。
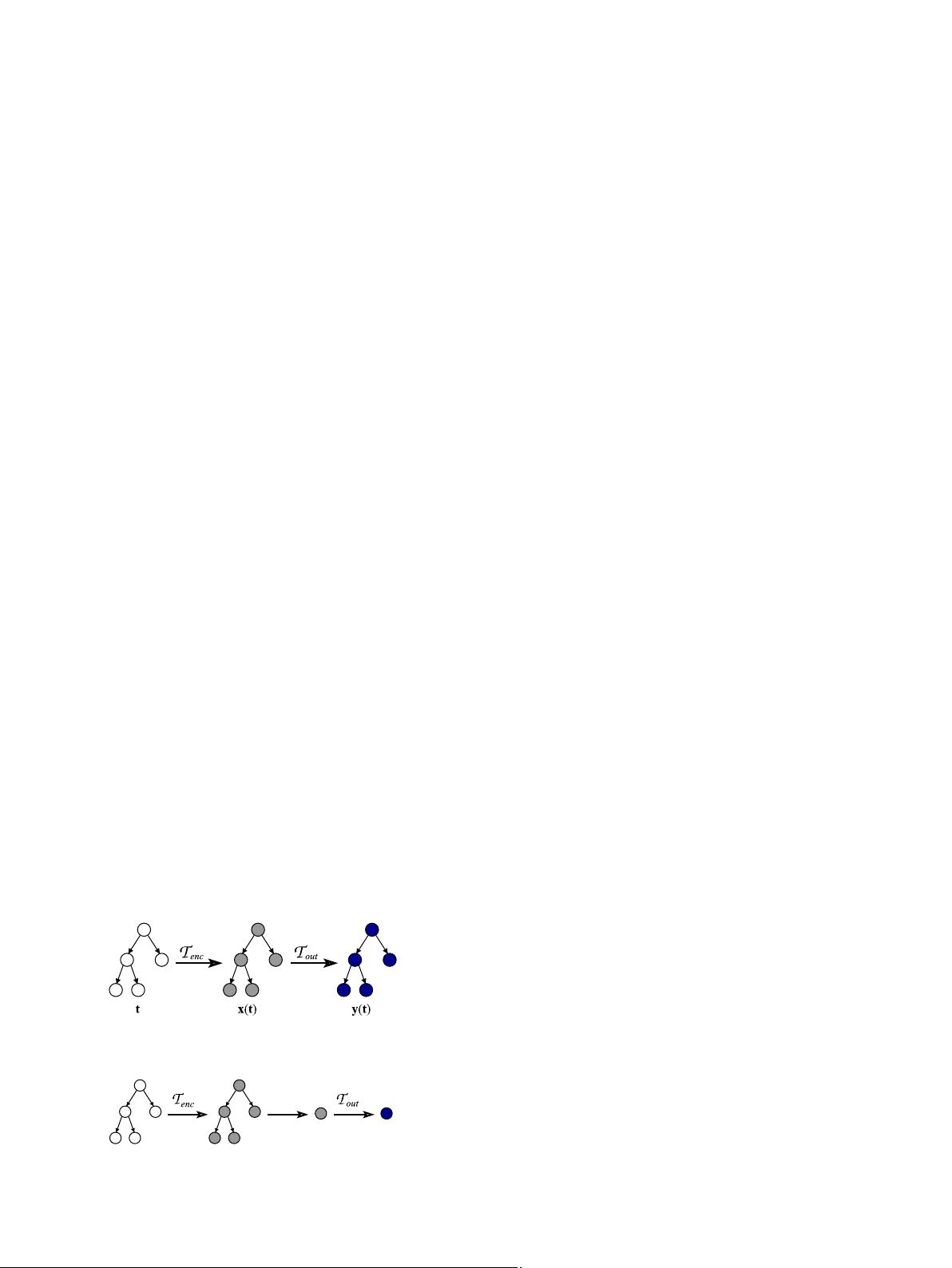
where yðtÞ represents the structured output associated to t.
T
out
canbecomputedbyresortingtoanode-wise output function g:
g :
R
N
R
-
R
N
Y
yðnÞ¼gðxðnÞÞ ð8Þ
where yðnÞA
R
N
Y
is the (unstructured) output associated to node n.In
this case yðtÞ is computed by applying function g to every node of t.
Fig. 2 summarizes the computation of t ree-to-tree structural
transductions.
For tree-to-element transductions, a state mapping function
w
is
preliminarily applied to the structured state computed by T
enc
,in
order to obtain a single fixed-size feature state, representative of
the whole input structure:
w
: ð
R
N
R
Þ
#k
-
R
N
R
ð9Þ
The unstructured fixed-size output is then computed by applying
the node-wise output function g of Eq. (8) only to the output of
the state mapping function:
yðtÞ¼gð
w
ðxðtÞÞÞ ð10Þ
In this case, yðtÞA
R
N
Y
denotes the unstructured output associated
to t. Moreover, input and output domains of T
out
of Eq. (7)
actually degenerate into the unstructured vectorial spaces
R
N
R
and
R
N
Y
respectively, and the computation of the whole transduc-
tion can be expressed as the composition of the encoding
transduction, the state mapping function and the output trans-
duction:
T ¼ T
out
JwJ
T
enc
ð11Þ
Fig. 3 graphically shows the steps of the computation of a tree-to-
element structural transduction.
Considering a supervised learning paradigm, a training set of
input trees with maximum degree k is represented by T ¼
fðt, y
target
ðtÞÞ : A ð
R
N
U
Þ
#k
, y
target
ðtÞA ð
R
N
Y
Þ
#k
g, where y
target
ðtÞ is the
target output associated to tree t in the general case of a tree
structured output (tree-to-tree transduction). In the following of
the paper, we focus on tree-to-element transductions which allow
us an immediate assessing of the TreeESN (provided with differ-
ent state mapping functions) on known problems modeling a
variety of interesting tasks on tree domains, such are classifica-
tions of trees. For the specific case of regression tasks related to
tree-to-element transductions, y
target
ðtÞ is a fixed size vector in
R
N
Y
. In the case of classification tasks with M target classes,
y
target
ðtÞ is an M-dimensional binary vector in which, for the
instances used in the experiments, the element corresponding
to the correct classification is equal to 1 and all the other
elements are equal to 0.
2.3. RecNNs and related models for processing structural
transductions
When the node-wise encoding and output functions of a
structural transduction, i.e.
t
and g in the above definitions
(Eqs. (5) and (8), respectively) are computed by neural networks,
we get RecNN models [21,7]. In the simplest architectural setting,
a RecNN consists of a recursive hidden layer, which is responsible
for the computation of
t
, and a feed-forward output layer, which
is responsible for the computation of g. Structural transductions
computed by RecNNs are usually characterized by causality,
stationarity and adaptivity, as the parameters of both the hidden
and the output layers are trained from examples. RecNNs
have been successfully applied to several real-world applica-
tive domains of relevant interest, including cheminformatics
(e.g. [25,45,29]), natural language processing [26,28] and image
analysis [24,27]. In addition, a number of results concerning
the computational capabilities of RecNN models have been
established, including universal approximation theorems for tree
domains processing [23,22]. The recursive dynamics can also be
exploited for unsupervised learning, as introduced in [46] using
self-organizing maps, or more in general in [42,43]. A recent
RecNNs variant is represented by the RelNN model [30,31], in
which encoding is based on a sequential processing of the
children of each node. The GNN model [32], based on a trained
encoding process under contractive constraints, extends the
recursive approaches allowing cyclic dynamics in the definition
of the state to process graph structures (and hence also tree
structures).
However, training RecNNs can face similar problems to those
encountered with RNNs [14,33,34], such as high computational
training costs, local minima, slow convergence and vanishing of
the gradients [47]. In particular, training RecNNs can be even
more computationally expensive than training RNNs. In this
regard, the RC paradigm represents a natural candidate for
investigating efficient approaches to RecNN modeling. Section 3
describes the TreeESN model, a first extension of the RC paradigm
to structured domains processing.
3. TreeESN model
TreeESNs are RecNNs implementing causal, stationary and
partially adaptive transductions on tree structured domains.
A TreeESN is composed of an untrained hidden layer of recursive
non-linear units (a generalized reservoir) and of a trained output
layer of feed-forward linear units (the readout). The reservoir
implements a fixed encoding transduction, whereas the readout
implements an adaptive output transduction. For tree-to-element
transductions, a state mapping function is used to obtain a single
fixed-size feature representation. The following sub-sections
describe the components of a TreeESN model.
3.1. Reservoir of TreeESN
The reservoir consists of N
R
recursive (typically) non-linear
units, which are responsible for computing the encoding of a tree
transduction by implementing the node-wise encoding function
t
of Eq. (5), which takes the role of a recursive state transition
function. Accordingly, the state corresponding to node n of a tree t
is computed as follows:
xðnÞ¼f W
in
uðnÞþ
X
k
i ¼ 1
^
Wxðch
i
ðnÞÞ
!
ð12Þ
where W
in
A
R
N
R
N
U
is the input-to-reservoir weight matrix
(which might also contain a bias term),
^
W A
R
N
R
N
R
is the
Fig. 2. Computation of a tree-to-tree structural transduction T .
x(t) y(t)
t
χ
χ(x(t))
Fig. 3. Computation of a tree-to-element structural transduction T .
C. Gallicchio, A. Micheli / Neurocomputing 101 (2013) 319–337322
剩余18页未读,继续阅读
2019-08-12 上传
2019-08-12 上传
2019-08-12 上传
2019-08-12 上传
2019-08-12 上传
2019-08-12 上传
2019-08-12 上传
2019-08-12 上传
2019-08-12 上传

weixin_39841882
- 粉丝: 445
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
