Spark全面解析:从基础到优化
版权申诉
"Spark知识体系吐血总结【无水印版】.pdf"
Spark是大数据处理领域中的一个关键工具,以其高效、灵活和易用性而受到广泛关注。本资料全面总结了Spark的核心知识,涵盖了从基础概念到高级特性的各个层面。
首先,Spark的发展史讲述了其如何从一个小型项目成长为大数据处理的主流框架。Spark之所以流行,得益于其对Hadoop MapReduce的改进,提供了内存计算,大大提高了数据处理速度。与Hadoop相比,Spark不仅在速度上有所提升,还在编程模型上更加简单,支持多种数据处理任务,如批处理、交互式查询、流处理和图形计算。
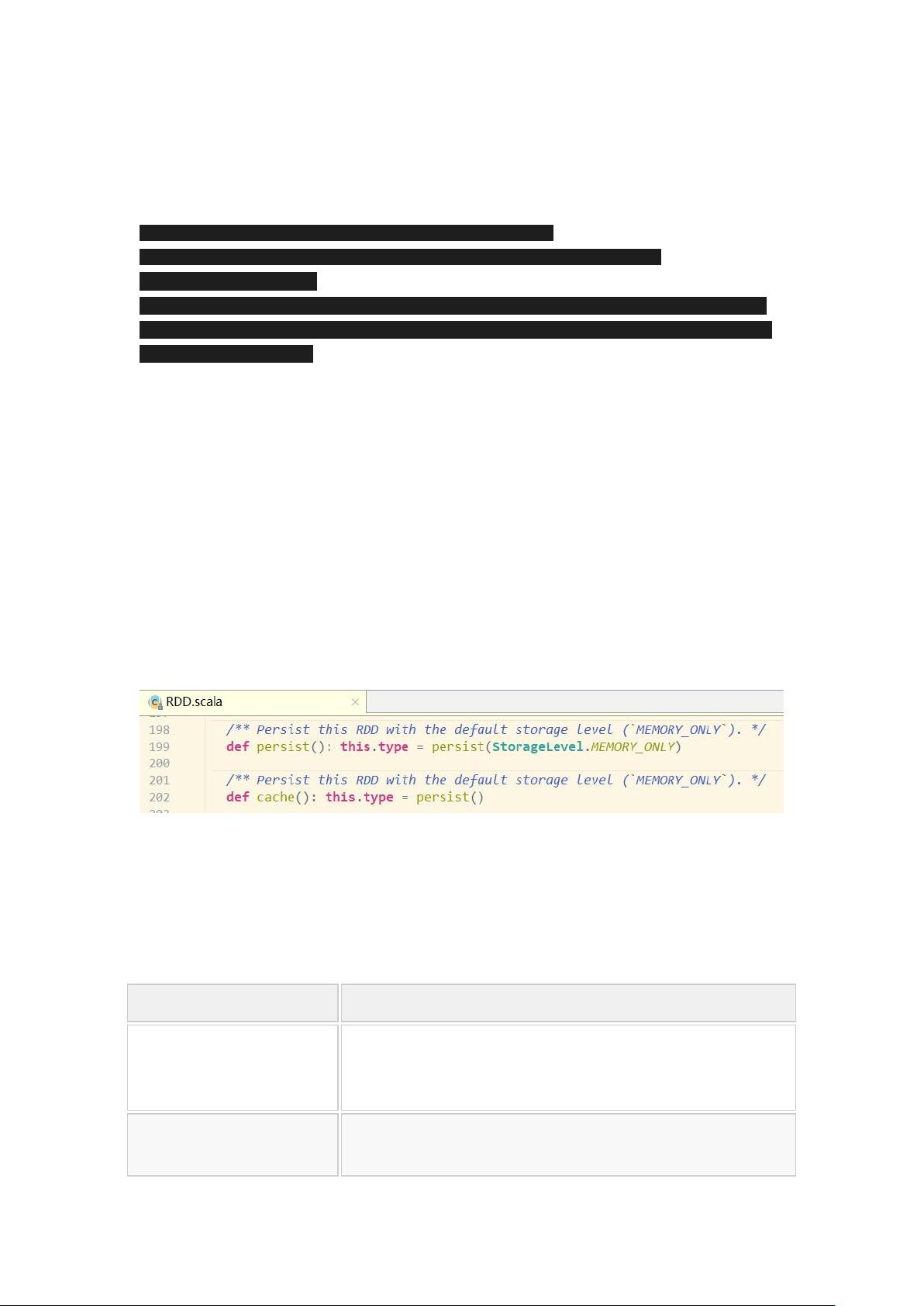
SparkCore是Spark的基础,其中最重要的概念是弹性分布式数据集(RDD)。RDD是一种不可变、分区的数据集合,可以并行操作。RDD的API包括创建、转换和行动操作,同时支持持久化和缓存以优化性能。RDD的容错机制包括Checkpoint,通过保存中间结果以恢复失败的任务。DAG的生成和划分Stage是Spark调度的基础,用于优化任务执行。
SparkSQL是Spark用于结构化数据处理的部分,它提供了一种与SQL类似的接口,使得开发人员能够方便地进行数据分析。SparkSQL可以与Hive集成,支持多种数据源,并通过DataFrame和Dataset提供了强大的数据抽象,适应各种数据分析场景。
SparkStreaming处理实时数据流,通过DStream抽象来表示连续的数据块。DStream可以进行多种操作,如窗口、转换和合并,以实现复杂的实时处理逻辑。StructuredStreaming是Spark的下一代流处理框架,提供类似SQL的API,基于微批处理模型,确保精确一次的语义,并广泛应用于实时数据处理场景。
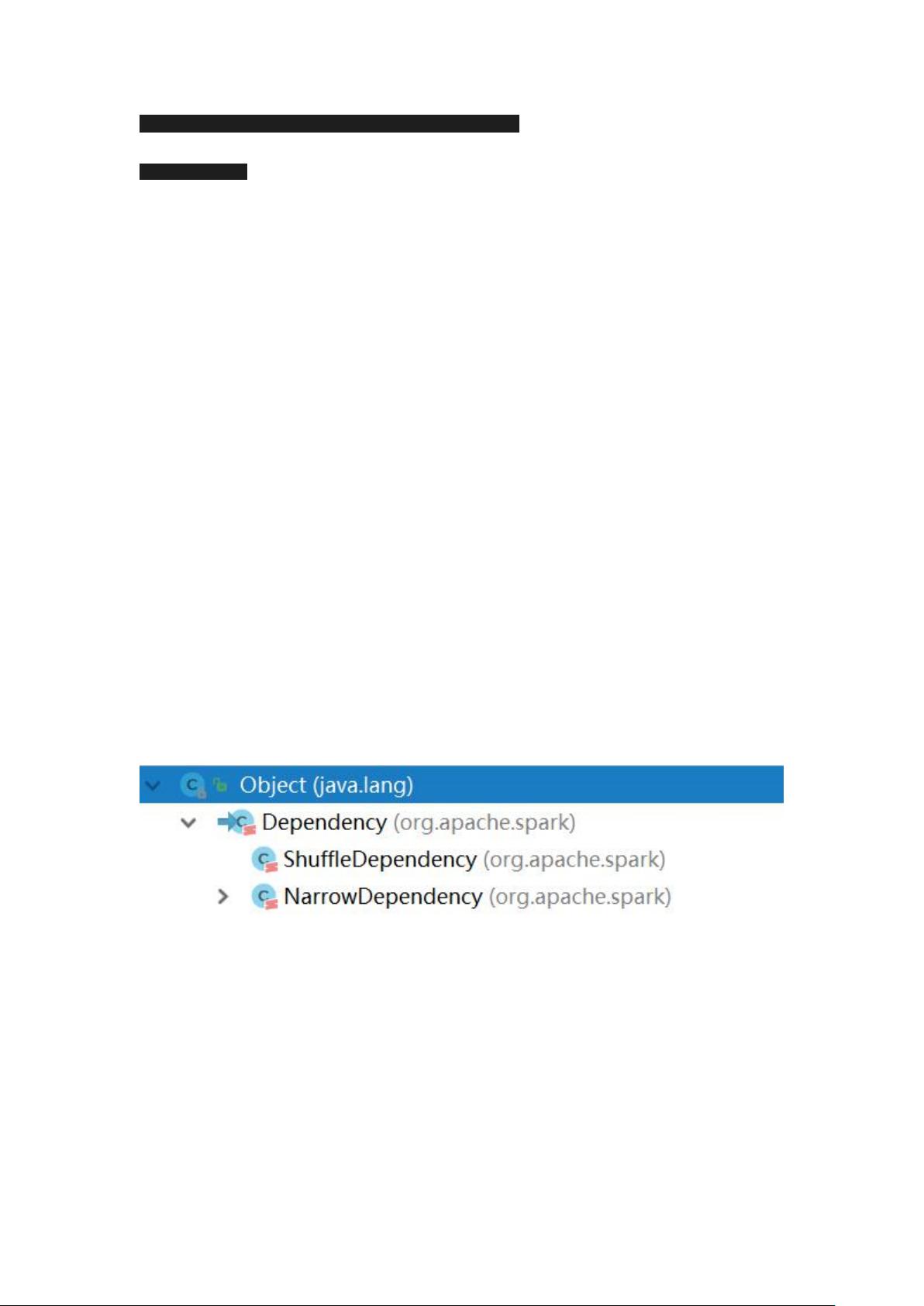
Spark的核心Shuffle是数据重新分布的过程,包括HashShuffle和SortShuffle。 Shuffle对于优化性能至关重要,但也会带来额外的I/O开销。理解并优化Shuffle可以显著提升Spark作业的效率。
深入到Spark的底层执行原理,了解Spark运行流程和架构特点有助于理解任务的调度和执行。例如,Spark的任务调度、Stage划分以及DAGScheduler和Executor的角色。
数据倾斜是Spark中常见的问题,会导致部分节点负载过高。解决数据倾斜的方法包括预聚合、调整reduce并行度、使用mapjoin等策略,以达到负载均衡。
最后,Spark性能优化是提升系统效率的关键。这包括选择合适的RDD算子,如避免不必要的shuffle,使用mapPartition和foreachPartition优化迭代操作,以及合理设置并行度等。此外,repartition和coalesce可以用于调整数据分区,以平衡计算资源的使用。
这份资料详尽地梳理了Spark的各个方面,无论你是初学者还是资深开发者,都能从中获取宝贵的知识,进一步提升对Spark的理解和应用能力。

16 / 109
动作算子
含义
take(n)
返回一个由数据集的前 n 个元素组成的数组
takeSample(withReplacement,num,
[seed])
返回一个数组,该数组由从数据集中随机采样的
num 个元素组成,可以选择是否用随机数替换不
足的部分,seed 用于指定随机数生成器种子
takeOrdered(n, [ordering])
返回自然顺序或者自定义顺序的前 n 个元素
saveAsTextFile
(path)
将数据集的元素以 textfile 的形式保存到
HDFS 文件系统或者其他支持的文件系统,对于每
个元素,Spark 将会调用 toString 方法,将它
装换为文件中的文本
saveAsSequenceFile(path)
将数据集中的元素以 Hadoop sequencefile 的格
式保存到指定的目录下,可以使 HDFS 或者其他
Hadoop 支持的文件系统
saveAsObjectFile(path)
将数据集的元素,以 Java 序列化的方式保存到
指定的目录下
countByKey()
针对(K,V)类型的 RDD,返回一个(K,Int)的 map,
表示每一个 key 对应的元素个数
foreach(func)
在数据集的每一个元素上,运行函数 func 进行
更新
foreachPartition(func)
在数据集的每一个分区上,运行函数 func
统计操作:
算子
含义
count
个数
mean
均值
sum
求和
max
最大值
min
最小值
variance
方差
sampleVariance
从采样中计算方差
stdev
标准差:衡量数据的离散程度


剩余108页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-08-23 上传
2022-08-04 上传
2017-11-22 上传
2017-09-28 上传
2020-02-20 上传

AI研究院
- 粉丝: 77
- 资源: 694
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
