贝壳找房的HBase应用与优化实践
需积分: 10 93 浏览量
更新于2024-07-18
1
收藏 3.84MB PDF 举报
"贝壳找房利用HBase进行大数据处理和分析,尤其在多维分析和楼盘字典等核心项目中发挥了重要作用。演讲者分享了在HBase实践中遇到的问题和性能优化经验,涵盖了HBase的基本概念、数据模型、逻辑架构以及在贝壳找房内部的具体应用领域。"
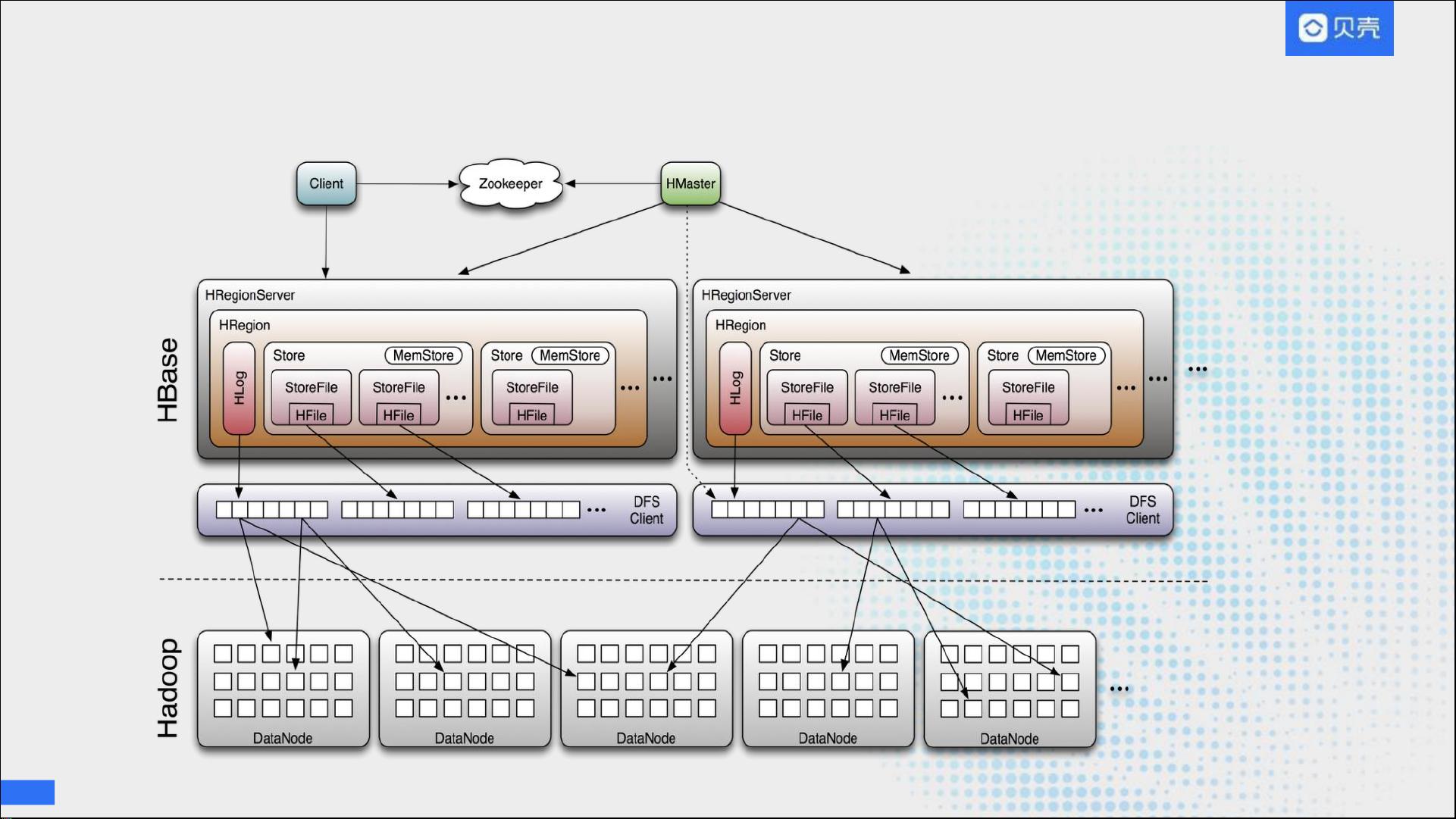
在贝壳找房的应用实践中,HBase扮演着关键角色。HBase是一个开源的分布式数据库,它是Google Bigtable的开源实现,专为处理大规模半结构化数据而设计。它基于Hadoop HDFS作为持久化存储,确保数据的可靠性和一致性,并依赖Zookeeper进行服务发现和状态管理。
HBase的数据模型由表、行键、列簇、列和版本组成,形成一个多维映射表,允许高效地存储和查询大量数据。这种设计特别适合那些需要快速随机读取和写入操作的场景,例如贝壳找房的房客源轨迹追踪、指标平台(包括使用Kylin进行的多维分析)以及用户画像构建等业务。
在贝壳找房的系统架构中,HBase被用于支持多种业务需求。房客源轨迹分析能够帮助公司理解用户行为,为个性化推荐和服务提供数据支持。通过集成Kylin,贝壳找房可以实现快速的多维数据分析,这对于决策支持和业务洞察至关重要。用户画像则能够帮助构建更精准的用户模型,提升用户体验和产品推荐效果。此外,HBase还应用于日志统计和其他分析任务,以提取有价值的信息并优化业务流程。
在实际使用过程中,贝壳找房积累了丰富的HBase性能调优经验。这可能包括但不限于表设计优化、读写策略调整、资源分配、以及对HBase的配置参数进行精细化调整,以确保在处理大量数据时保持系统的高效运行和稳定性。
演讲者邓钫元在Hadoop、HBase和Kylin等大数据生态组件方面有着深厚的专业知识,并且对开源社区有所贡献。他的分享不仅揭示了HBase在贝壳找房的核心作用,也提供了宝贵的实际操作经验和最佳实践,对于其他希望在大数据处理上进行类似探索的企业具有很高的参考价值。
WE ARE BEIKE, 2018 BEIKE ALL RIGHTS RESERVED
8
系统架构

剩余43页未读,继续阅读
2248 浏览量
1960 浏览量
2056 浏览量
2023-09-09 上传
321 浏览量
221 浏览量
2022-03-18 上传
2022-03-04 上传
112 浏览量

过往记忆
- 粉丝: 4401
- 资源: 274
 我的内容管理
展开
我的内容管理
展开







最新资源
- GEN32“创世纪32“监控组态软件.rar
- valle-input:很棒的valle输入元素-使用Polymer 3x的Web组件
- Simple Picture Puzzle Game in JavaScript Free Source Code.zip
- ssm高考志愿填报系统设计毕业设计程序
- MyApplication:组件化、
- wc-core:Mofon Design的Web组件核心
- odrViewer.zip_odrViewer_opendrive_opendrive viewer_opendrive可视化_
- Simple Table Tennis Game using JavaScript
- 同步安装文件2.rar
- GalaxyFighters-开源
- STM32+W5500 Modbus-TCP协议功能实现
- Excel做为数据库登录的三层实现_dotnet整站程序.rar
- konsave:Konsave允许使用保存您的KDE Plasma自定义设置并非常轻松地还原它们!
- make-element:创建没有样板的自定义元素
- MachineLearning
- Simple Platformer Game using JavaScript
