互联网用户购买行为预测:lightGBM+LR模型应用
版权申诉
"全国大学生数据统计与分析竞赛21年B题本科生组的一篇优秀论文,探讨了基于lightGBM+LR的用户购买行为预测研究。论文涉及数据预处理、数据可视化、特征构造和模型建立等多个方面,最终模型达到99.8%的预测准确率,并对比了xgboost和catboost的效果。"
这篇论文详细阐述了一个数据科学项目的过程,旨在预测用户是否会下单。以下是论文中涵盖的关键知识点:
1. **数据预处理**:这是数据分析的第一步,包括检查数据完整性、去除重复值、处理缺失值和噪声。这些步骤对于确保模型在干净、准确的数据上训练至关重要。
2. **数据可视化**:使用Matplotlib、Seaborn和Bokeh等库来展示用户所在城市分布和登录情况,帮助理解数据的结构和潜在模式,为后续的特征工程提供指导。
3. **特征工程**:特征选择和构建是预测模型性能的关键。论文提到了one-hot编码,这是一种将非数值特征转化为数值表示的方法,用于构造稀疏矩阵,使得算法能够处理分类变量。
4. **模型建立**:
- **lightGBM**:这是一个梯度提升决策树模型,以其高效性和准确性著称,特别适合大规模数据集。
- **LR(逻辑回归)**:简单且易于解释的分类模型,常用于二分类问题,可以用于对lightGBM的结果进行进一步处理。
- **lightGBM+LR组合**:论文提出先用lightGBM预测,然后将结果输入到LR中,这种集成学习策略可以提升模型的预测性能。
- **xgboost和catboost**:作为比较,这两个也是梯度提升模型,常用于竞赛和实际业务场景,通过比较它们与lightGBM+LR的表现,可以评估模型的稳定性和泛化能力。
5. **SMOTE**:这是一种过采样技术,用于解决类别不平衡问题,通过创建合成少数类样本来平衡数据集,提高模型对少数类的识别能力。
6. **模型训练与评估**:论文中涉及到训练集和测试集的划分,以及模型的训练和评估过程。在训练模型时,通常会使用交叉验证来避免过拟合,并通过评估指标如准确率来度量模型的性能。
论文最后对公司的建议可能基于上述分析结果,例如优化营销策略,针对高概率购买用户进行精准推广,或者改进数据收集和处理方法以提升模型预测效果。这篇论文为理解和实施数据驱动的用户行为预测提供了详实的步骤和实践经验。
第
4
页 共
25
页
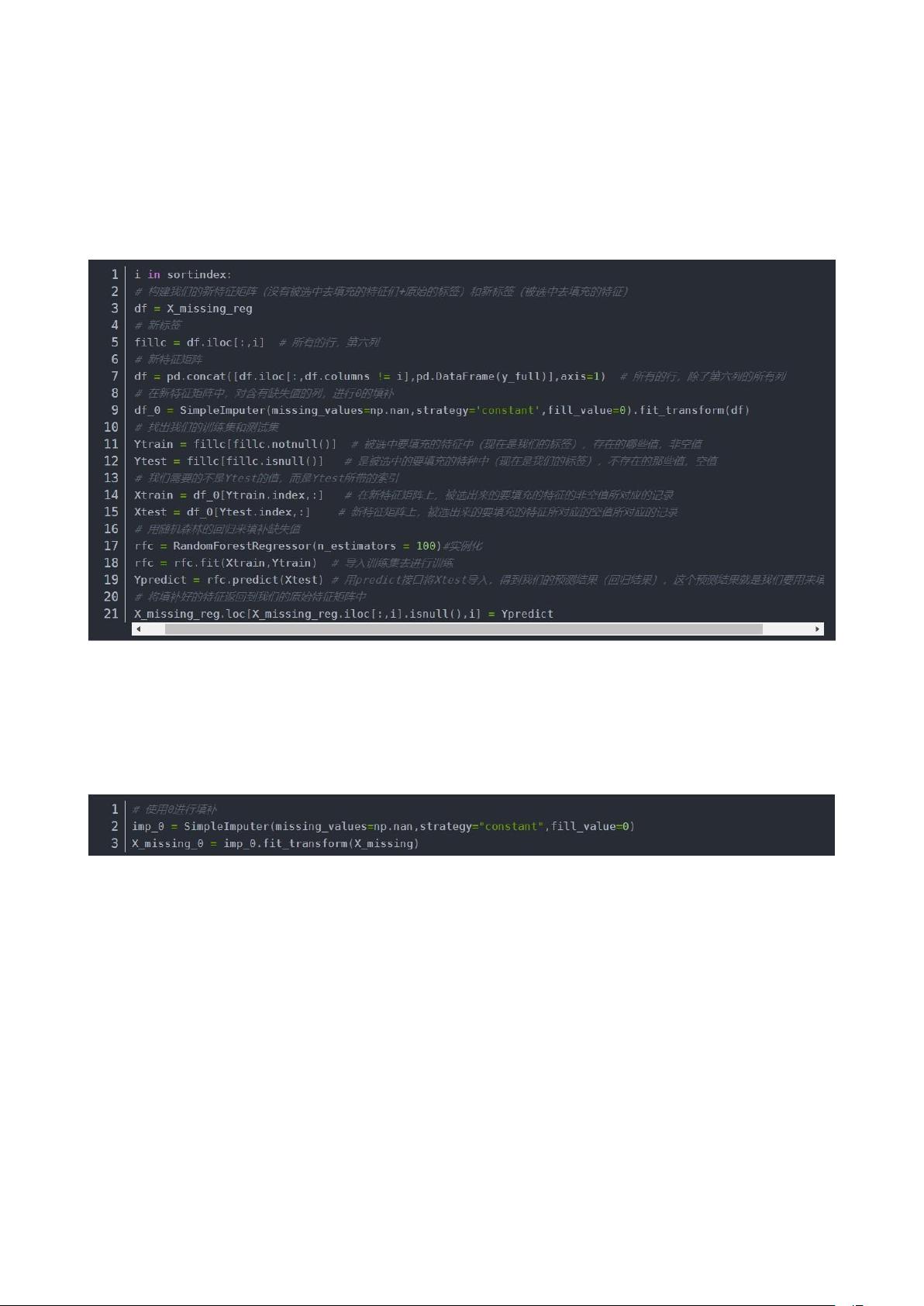
(2)缺失字段处理。我们采用随机森林回归填补缺失值的方法对原始数据中存在缺失字段的
数据进行处理。使用随机森林回归填补缺失值任何回归都是从特征矩阵中学习,然后求解连
续型标签 y 的过程,之所以能够实现这个过程,是因为回归算法认为,特征矩阵和标签之前
存在着某种联系。实际上,标签和特征是可以相互转换的,比如说,在一个“用地区,环境,
附近学校数量”预测“房价”的问题中,我们既可以用“地区”,“环境”,“附近学校数
量”的数据来预测“房价”,也可以反过来,用“环境”,“附近学校数量”和“房价”来
预测“地区”。而回归填补缺失值,正是利用了这种思想。下面是核心算法:
图 3-6 随机森林回归填补缺失值核心算法
以 处 理 用 户 信 息 数 据 为 例 , 通 过 对 用 户 信 息 进 行 数 据 分 析 , 发 现 在 用 户 信 息 表
(user_info.csv)的表格中,有许多用户城市一栏的数据缺失,数据缺失的的原因可能是由于
采样异常或者用户信息未完善所导致,所以对其填充 0(表示未知),并在第二问对用户所
在城市分布情况进行可视化展示时不予考虑。
图 3-7 使用 0 进行填补算法
(3)噪声数据处理。即对数据中非法数据及异常数据进行去除。本次数据集的研究是为了根
据用户信息预测用户是否下单购买,对所给数据进行分析,对不属于本次预测范围的数据进
行检索。通过数据检索,除重复 user_id 之外,未发现异常数据。
2. 将处理好的四个表格取交集,并整合成新的数据源。
部分表格示例如图所示,详情见附录
剩余26页未读,继续阅读
相关推荐



阿拉伯梳子
- 粉丝: 2803
 我的内容管理
展开
我的内容管理
展开







最新资源
- 32位TortoiseSVN_1.7.11版本下载指南
- Instant-gnuradio:打造定制化实时图像和虚拟机GNU无线电平台
- PHP源码工具PHProxy v0.5 b2:多技术项目源代码资源
- 最新版PotPlayer单文件播放器: 界面美观且功能全面
- Borland C++ 必备库文件清单与安装指南
- Java工程师招聘笔试题精选
- Copssh:Windows系统的安全远程管理工具
- 开源多平台DimReduction:生物信息学的维度缩减利器
- 探索Novate:基于Retrofit和RxJava的高效Android网络库
- 全面升级!最新仿挖片网源码与多样化电影网站模板发布
- 御剑1.5版新功能——SQL注入检测体验
- OSPF的LSA类型详解:网络协议学习必备
- Unity3D OBB下载插件:简化Android游戏分发流程
- Android网络编程封装教程:Retrofit2与Rxjava2实践
- Android Fragment切换实例教程与实践
- Cocos2d-x西游主题《黄金矿工》源码解析
