CRAFT论文解读:细说字符区域感知的深度学习文本检测方法
需积分: 50 169 浏览量
更新于2024-07-16
收藏 2.83MB PPTX 举报
CRAFT.pptx是一份关于场景文本检测领域的研究论文,着重探讨了在深度学习时代背景下,针对文本检测方法的发展和改进。论文中提到,早期的传统方法,如基于人工特征的MSER和SWT,已被深度学习驱动的目标检测和实例分割技术所取代,比如SSD、Faster R-CNN和FCN。这些方法在处理文本检测时面临的挑战在于文本形状的不规则性和长宽比变化,为此,TextBoxes和DMPNet分别采用了调整卷积核和锚点设计以及融合四边形滑窗来适应不同形状。
Rotation-SensitiveRegressionDetector (RSDD) 利用旋转不变性,通过卷积核旋转来增强对各种形状文本的捕捉,但其结构限制了捕捉所有可能性。基于分割的文本检测策略,如SSTD,通过结合回归和注意力机制来减少背景干扰,强调文本区域的精确识别。TextSnake则通过预测文本区域、中心线和几何属性来实现端到端的文本检测。
端到端的检测方法,如FOTS和EAA,将文本检测与识别任务结合起来,利用识别结果提升检测准确度,如MaskTextSpotter通过统一模型将识别视为语义分割问题。这些方法显示出识别模块在增强文本检测器对复杂背景噪声的鲁棒性方面的重要性。
论文特别关注字符级别的检测,尽管通常以单词作为检测单元,但识别字母边界对于准确地形成文本实例至关重要。为此,研究引入了弱监督学习框架,能够在现有单词级标注数据上估计字符级的真实标签,从而实现对长、弯曲及任意形状文本的灵活检测。
CRAFT架构的核心是基于VGG16的全卷积网络,结合批量归一化层(BN),提供稳定的特征提取能力。解码器部分借鉴了U-Net的跳跃连接结构,这种设计有助于保留更多的上下文信息,从而优化文本区域的定位精度。
总结来说,CRAFT论文深入探讨了如何利用深度学习技术解决文本检测中的形状多样性问题,以及如何通过端到端训练和特征融合来提升检测性能。它提供了实用的算法和架构细节,对理解和开发高效文本检测系统具有重要意义。
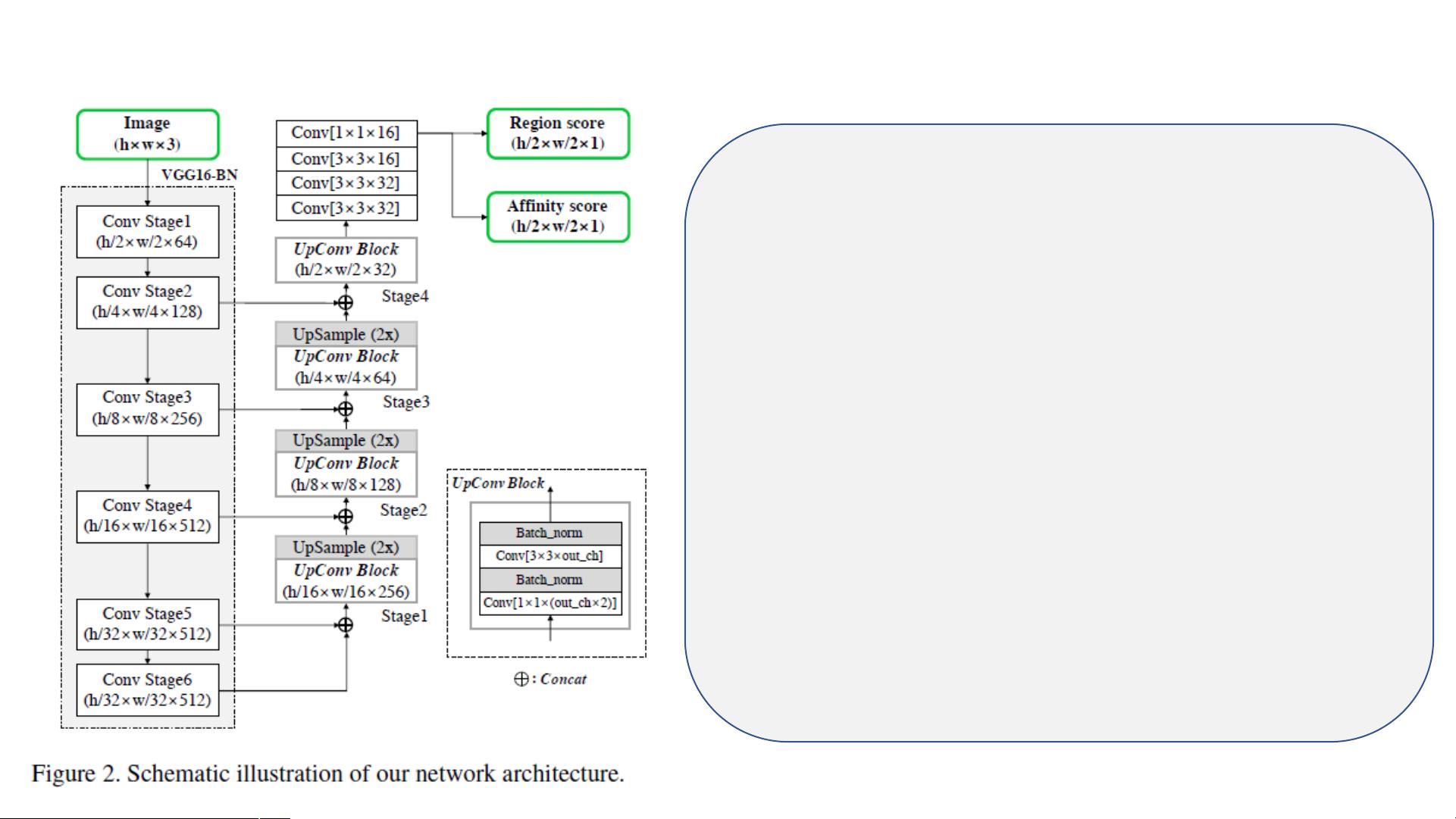
Architectu
re
backbone :基于 VGG16 的全卷积结构,加 bn 层
Decoder :有类似 U-net 的跳跃连接层,聚集低层次特
征图
Output :两个通道, the region score and the
a.nity score
•
the region score :代表给定像素是字符中心的概率;
(区域分数) 用来定位单个字符
•
the a.nity score :代表相邻字符间距中心的概率;
(关联分数) 用来把每个字符组合成实例
剩余16页未读,继续阅读
1693 浏览量
2024-01-07 上传
2021-10-20 上传
2021-10-11 上传
2021-09-24 上传
2021-11-20 上传
2021-10-08 上传
2021-10-09 上传

じんじん
- 粉丝: 504
 我的内容管理
展开
我的内容管理
展开







最新资源
- Web远程教学系统需求分析指南
- 禅道6.2版本发布,优化测试流程,提高安全性
- Netty传输层API中文文档及资源包免费下载
- 超凡搜索:引领搜索领域的创新神器
- JavaWeb租房系统实现与代码参考指南
- 老冀文章编辑工具v1.8:文章编辑的自动化解决方案
- MovieLens 1m数据集深度解析:数据库设计与电影属性
- TypeScript实现tca-flip-coins模拟硬币翻转算法
- Directshow实现多路视频采集与传输技术
- 百度editor实现无限制附件上传功能
- C语言二级上机模拟题与VC6.0完整版
- A*算法解决八数码问题:AI领域的经典案例
- Android版SeetaFace JNI程序实现人脸检测与对齐
- 热交换器效率提升技术手册
- WinCE平台CPU占用率精确测试工具介绍
- JavaScript实现的压缩包子算法解读
