中文分词算法解析:基于字符串、理解与统计的比较
版权申诉
17 浏览量
更新于2024-08-04
收藏 26KB DOCX 举报
"本文主要探讨了中文分词的三种主要算法——基于字符串匹配的分词、基于理解的分词和基于统计的分词,并分析了它们在歧义识别、新词识别、词典依赖和语料库需求方面的优劣。"
在中文自然语言处理中,分词是至关重要的一步,它直接影响到后续的文本分析和理解效果。以下是这三种分词算法的详细比较:
1. 基于字符串匹配的分词:这种方法主要依赖于一个庞大的电子词典,将输入的文本与词典中的词汇进行匹配。它的优点在于效率高,实现简单,但缺点也很明显,即无法处理歧义和新词。由于仅与词典中的词语进行比较,遇到多义词或未登录词时,无法做出准确判断。
2. 基于理解的分词:这种方法试图通过理解句子的上下文和语义来确定词语边界,因此在歧义识别方面具有较强的能力。它可以较好地处理一些复杂的语境和新词,特别是那些符合语言规则的新词。然而,这种方法的实现复杂,计算成本较高,且对系统的要求较高,需要具备一定的自然语言理解和推理能力。
3. 基于统计的分词:这种方法利用大量语料库中的数据进行统计学习,找出词语出现的频率和模式,以此来确定分词结果。在处理歧义和新词识别上表现出色,尤其是在处理网络新词和一些有规律的未登录词时。但它也需要词典,但依赖程度较低,而且必须依赖大规模的语料库进行训练,否则可能产生误判。
在实际应用中,每种算法都有其适用场景。基于字符串匹配的分词适合处理已知词汇的文本,如新闻报道;基于理解的分词在学术研究和高级语言处理任务中更有优势;而基于统计的分词则适用于处理大量网络文本,尤其是新兴词汇丰富的环境。
选择哪种分词算法取决于具体的应用需求,如处理速度、准确度、资源限制以及对新词识别和歧义处理的要求。在实际开发过程中,往往还会结合多种方法,通过集成学习或深度学习等方式提高整体的分词效果,以适应不同场景下的中文分词挑战。
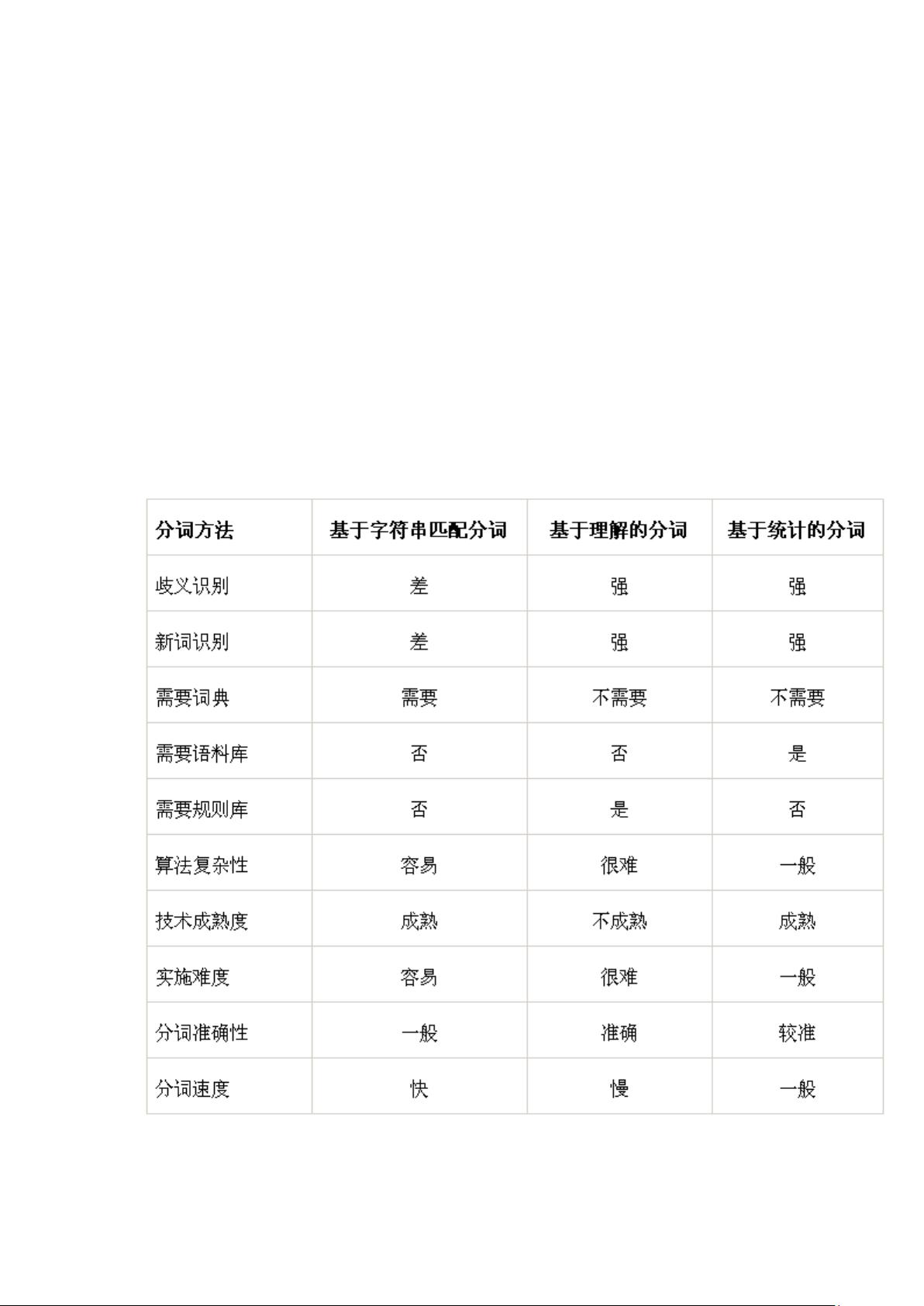
三种中文分词算法优劣比较
目前为止,中文分词包括三种方法:1)基于字符串匹配的分词;2)基于理解的分词;3)
基于统计的分词。
到目前为止,还无法证明哪一种方法更准确,每种方法都有自己的利弊,有强项也有致命弱
点,简单的对比见下表所示:
各种分词方法的优劣对比:
下载后可阅读完整内容,剩余3页未读,立即下载
2023-09-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-23 上传
2023-04-07 上传
2023-04-26 上传
2008-03-07 上传
2012-10-28 上传

小小哭包
- 粉丝: 1934
- 资源: 4081
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
