Hadoop入门指南:从HDFS到环境搭建
需积分: 11 146 浏览量
更新于2024-07-09
收藏 3.49MB DOCX 举报
"这篇文档是关于Hadoop的学习入门资料,主要涵盖了Hadoop的概述、HDFS、YARN、MapReduce以及大数据技术生态体系,并详细介绍了Hadoop运行环境的搭建步骤,包括虚拟机环境准备和JDK的安装。"
在大数据领域,Hadoop是一个关键的开源框架,用于存储和处理大规模数据。本文档主要面向想要入门Hadoop的初学者,通过深入浅出的方式介绍相关知识。
1. HDFS(Hadoop Distributed File System)是Hadoop的核心组成部分,用于分布式存储。它设计的目标是处理和存储PB级别的数据,保证高容错性和高可用性。HDFS的主要特点是将大文件分割成多个固定大小的数据块(默认为128MB),并在集群的不同节点上复制这些块,以提高数据的可靠性。
1.1 HDFS的产出背景是为了应对传统单机文件系统无法处理大规模数据的问题。其定义是一种分布式文件系统,允许在廉价硬件上进行高吞吐量的数据访问。
1.2 HDFS的优点包括高容错性、可扩展性、简单性和高效的数据处理。缺点则有低延迟读写性能不足、不适用于小文件存储以及无法高效支持随机读取等。
1.3 HDFS由NameNode、DataNode、Secondary NameNode等组件构成,其中NameNode负责元数据管理,DataNode负责实际数据存储,Secondary NameNode则帮助NameNode定期合并元数据文件以减少NameNode的压力。
1.4 文件块大小的选择是根据系统需求和硬件配置来设定的,通常情况下,较大的块大小可以减少寻道时间,提高读写效率。
1.5 YARN(Yet Another Resource Negotiator)是Hadoop的资源管理系统,它将Hadoop的资源管理和计算任务调度功能分离,提供了一种通用的资源调度平台,使得Hadoop可以支持多种计算框架。
1.6 MapReduce是Hadoop的编程模型,用于处理和生成大数据集。它将计算过程分为Map和Reduce两个阶段。Map阶段将输入数据切分成键值对,然后并行处理;Reduce阶段接收Map阶段的结果,进行聚合和总结,生成最终结果。
1.7 大数据技术生态体系包括Hadoop之外的其他工具和技术,如Spark、Hive、Pig、HBase等,它们共同构成了一个复杂而全面的大数据处理环境。
3.1 Hadoop运行环境的搭建是学习Hadoop的第一步。这里描述了在虚拟机上设置Linux环境的步骤,包括配置静态IP、修改主机名、关闭防火墙、创建新用户、赋予用户sudo权限、创建文件夹以及安装JDK等。
3.2 安装JDK是必要的,因为Hadoop运行需要Java环境。文档详细说明了如何检查、卸载旧版本JDK,以及如何通过SecureCRT工具将JDK文件传输到虚拟机中。
以上是Hadoop入门学习的基本内容,涵盖了Hadoop的关键概念和技术,对于初学者来说,这是一个良好的起点,可以帮助理解Hadoop的工作原理和操作流程。
3.2 安装 JDK
1. 卸载现有 JDK
(1)查询是否安装 Java 软件:
[atguigu@hadoop101 opt]$ rpm -qa | grep java
(2)如果安装的版本低于 1.7,卸载该 JDK:
[atguigu@hadoop101 opt]$ sudo rpm -e 软件包
(3)查看 JDK 安装路径:
[atguigu@hadoop101 ~]$ which java
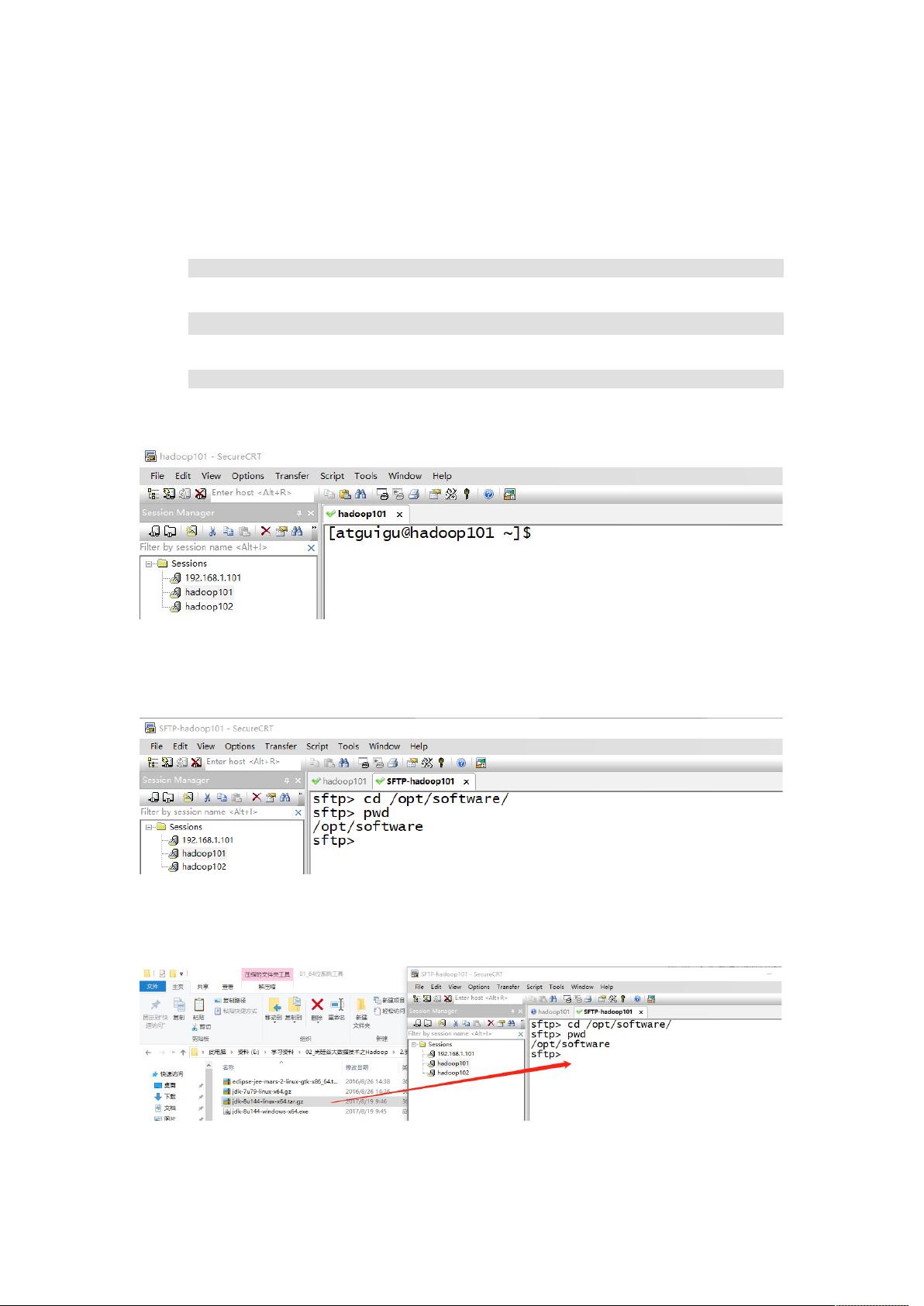
2. 用 SecureCRT 工具将 JDK 导入到 opt 目录下面的 software 文件夹下面,如图
2-28 所示
图 2-28 导入 JDK
“alt+p”进入 sftp 模式,如图 2-29 所示
图 2-29 进入 sftp 模式
选择 jdk1.8 拖入,如图 2-30,2-31 所示
图 2-30 拖入 jdk1.8

剩余31页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
134 浏览量
2022-11-24 上传
194 浏览量
2022-10-31 上传
115 浏览量
2024-12-26 上传

qq_58978878
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于YOLO神经网络的实时车辆检测代码
- TravelAdvisor
- uiGradients-Viewer-iOS::artist_palette:一个开放源代码应用程序,用于查看https上发布的渐变
- 15套动态和静态科技风光类PPT模板-共30套
- Tonite
- 正点原子精英Modbus_Master_Template.zip
- 聚合物制造:移至Polymertools monorepo
- AboutMe
- Trello克隆
- IT资讯网_新闻文章发布系统.rar
- Simple Math Trainer Game
- igloggerForSmali
- Tomate
- 4,STM32启动文件.rar
- pghoard:PostgreSQL备份和还原服务
- hw9
