"尚硅谷大数据技术之 Flink简介及起源介绍"
 已收录资源合集
已收录资源合集
需积分: 0 88 浏览量
更新于2023-12-20
1
收藏 2.78MB DOCX 举报
Flink 是一个由 Stratosphere 项目演变而来的顶级 Apache 项目,起源于2010年至2014年间的柏林大学和其他欧洲大学的合作研究项目。在2014年4月,Stratosphere的代码被复制并捐赠给了Apache软件基金会,随后项目成为了Apache软件基金会的顶级项目。Flink这个词在德语中表示快速和灵巧,正是这种特点使得Flink成为了大数据处理领域中备受瞩目的项目。
Flink的logo是一只可爱的松鼠,这既是因为松鼠本身具有快速和灵巧的特点,也因为柏林的松鼠有着一种迷人的红棕色。而Flink的松鼠logo的尾巴的颜色与Apache软件基金会的logo颜色相呼应,显示出了项目与Apache软件基金会的紧密联系。
Flink是一个流式处理和批处理的分布式数据处理引擎,提供高效的容错处理、精确一次的状态一致性和丰富的流式处理能力。Flink可用于构建大规模的、实时的数据流应用程序,并且能够处理包括事件驱动、实时分析和数据管道等多种场景。总的来说,Flink作为一个开源的数据处理引擎,在大数据领域有着广泛的应用前景。
值得注意的是,与其他的数据处理引擎相比,Flink具有更高的吞吐量和更低的延迟,这使得它适用于对实时性能有要求的场景。同时,Flink支持丰富的流式处理算子,包括窗口操作、基于时间的操作以及基于状态的操作等功能,这使得用户能够更加灵活地处理流式数据。
除了流式处理之外,Flink还支持批处理模式,用户可以使用相同的API和运行时环境来开发和部署流式处理和批处理应用。这种统一的编程模型使得用户能够更加方便地管理和维护数据处理应用,同时也提高了开发效率。
总的来说,Flink作为一个开源的流式处理和批处理引擎,在大数据领域具有广泛的应用前景。它的高效、低延迟和丰富的功能使得其成为了越来越多企业和组织的首选。未来,随着大数据技术的不断发展,相信Flink会在数据处理领域发挥越来越重要的作用。
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
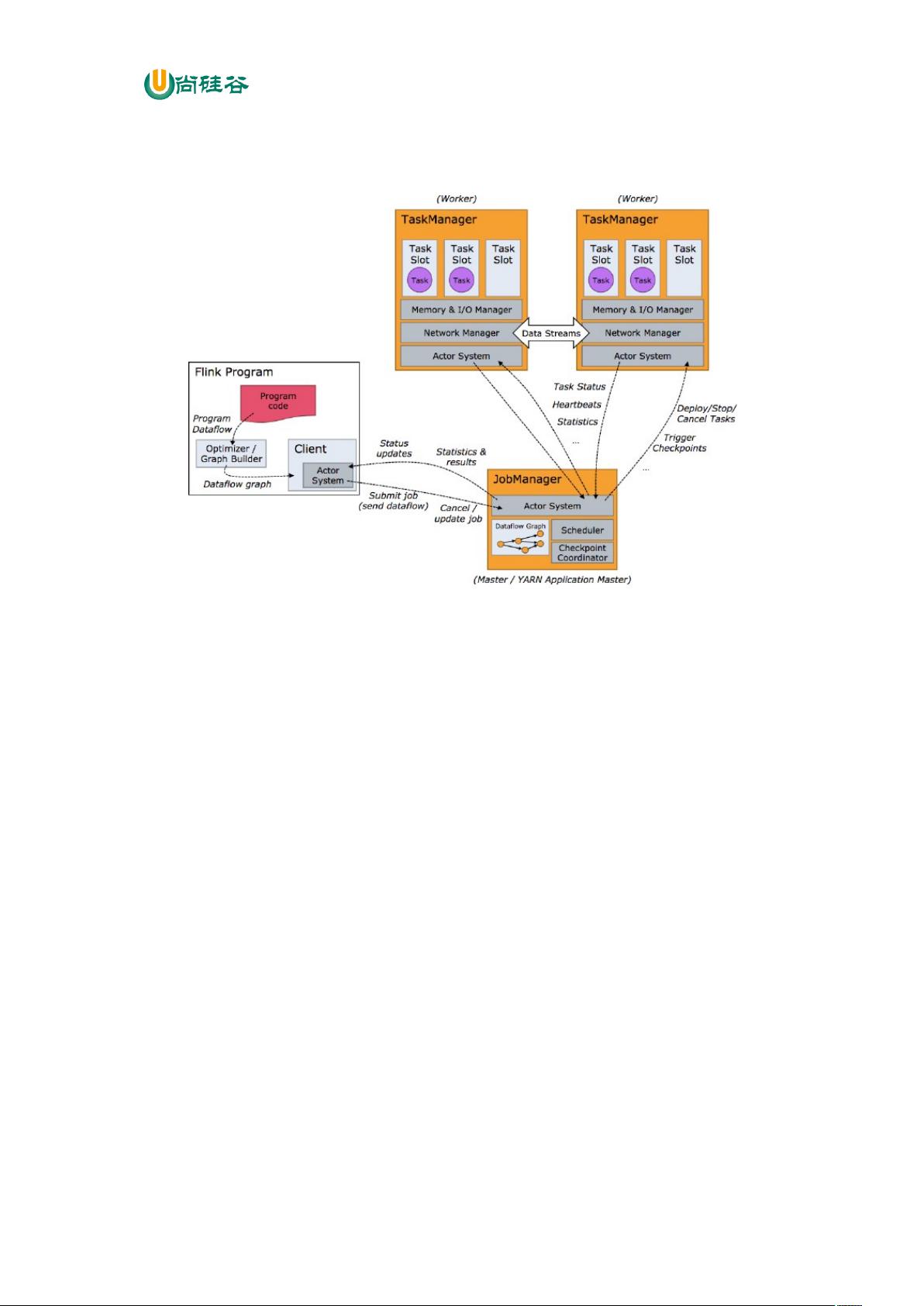
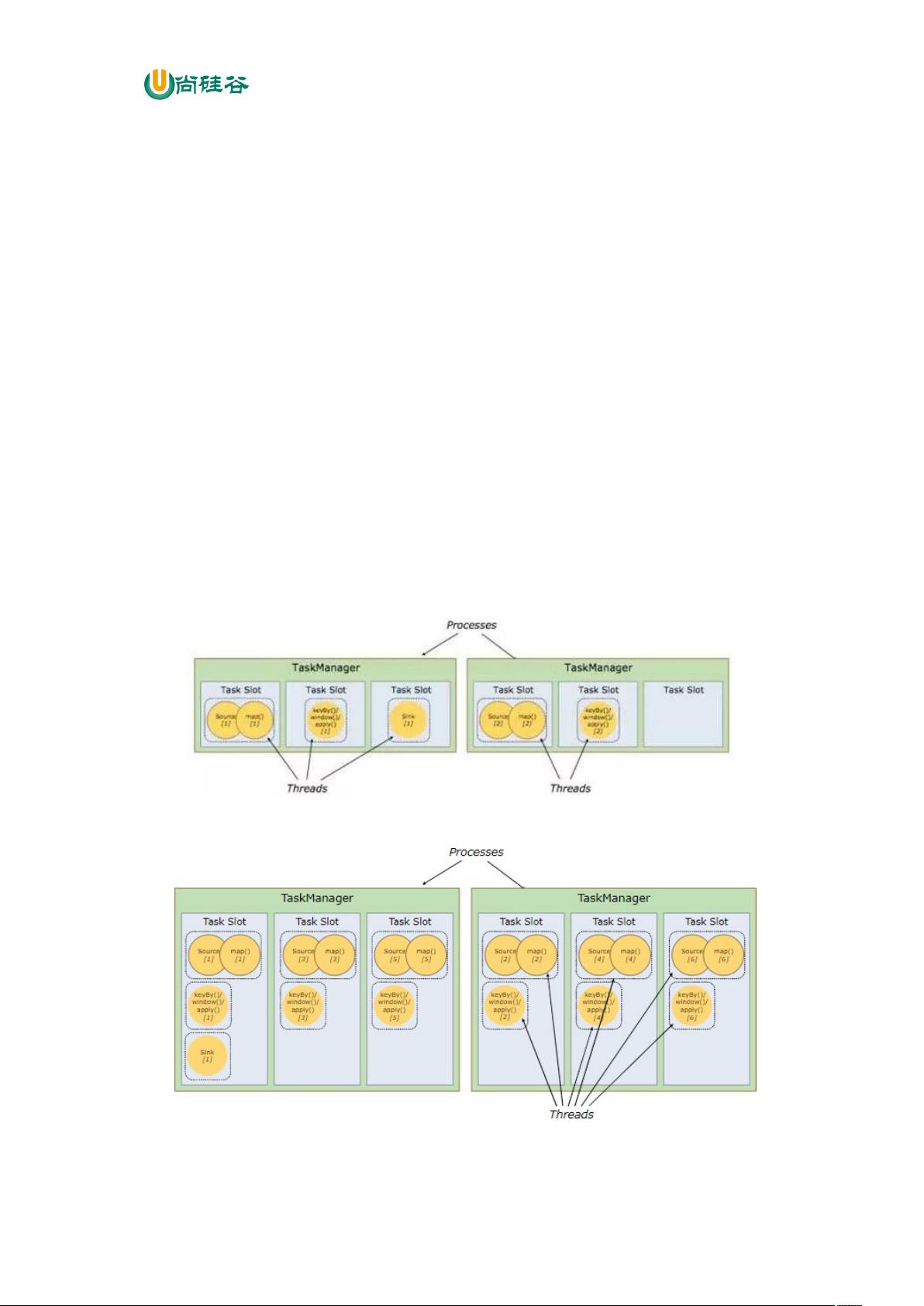
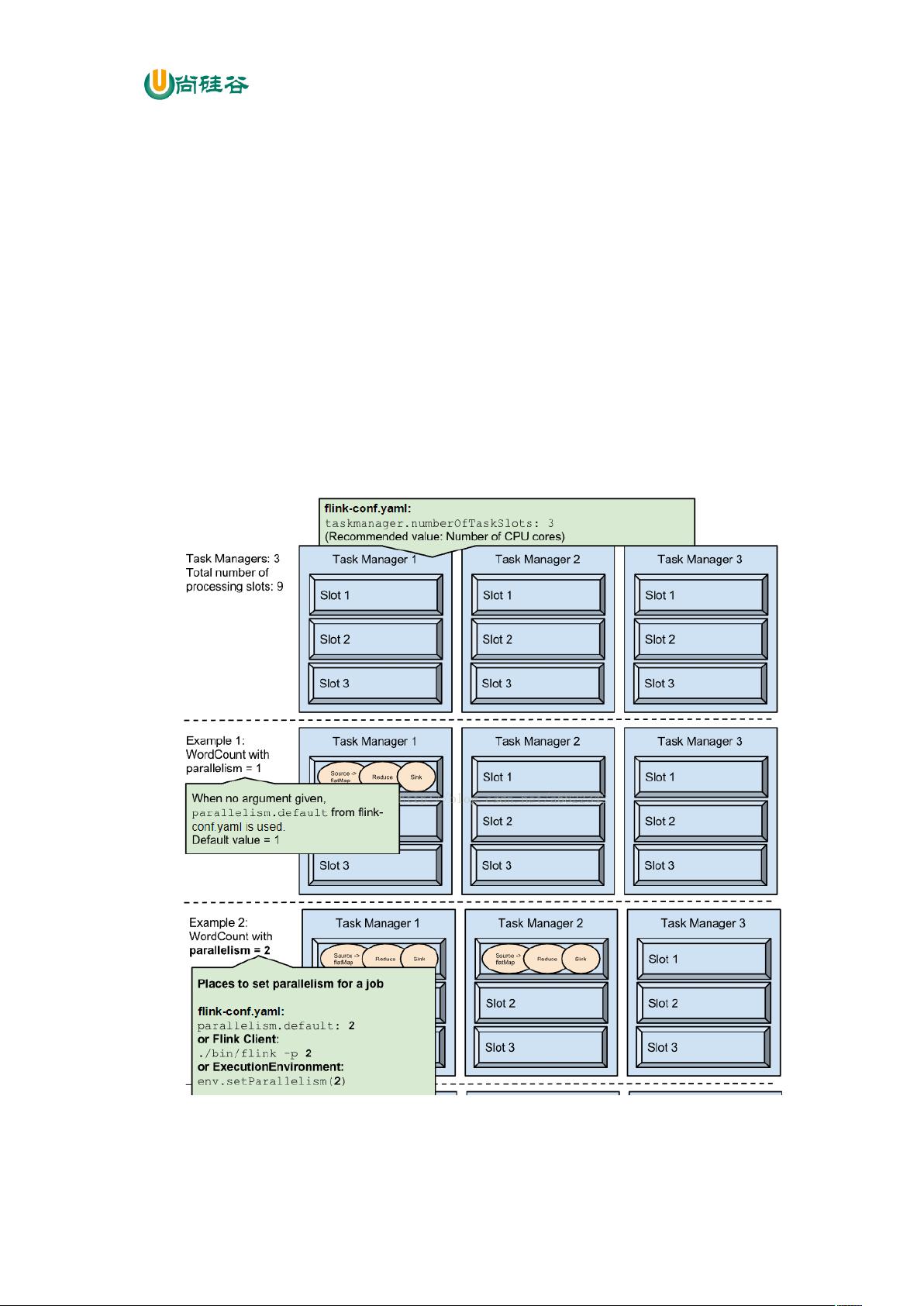
尚硅谷大数据技术之 Flink
—————————————————————————————
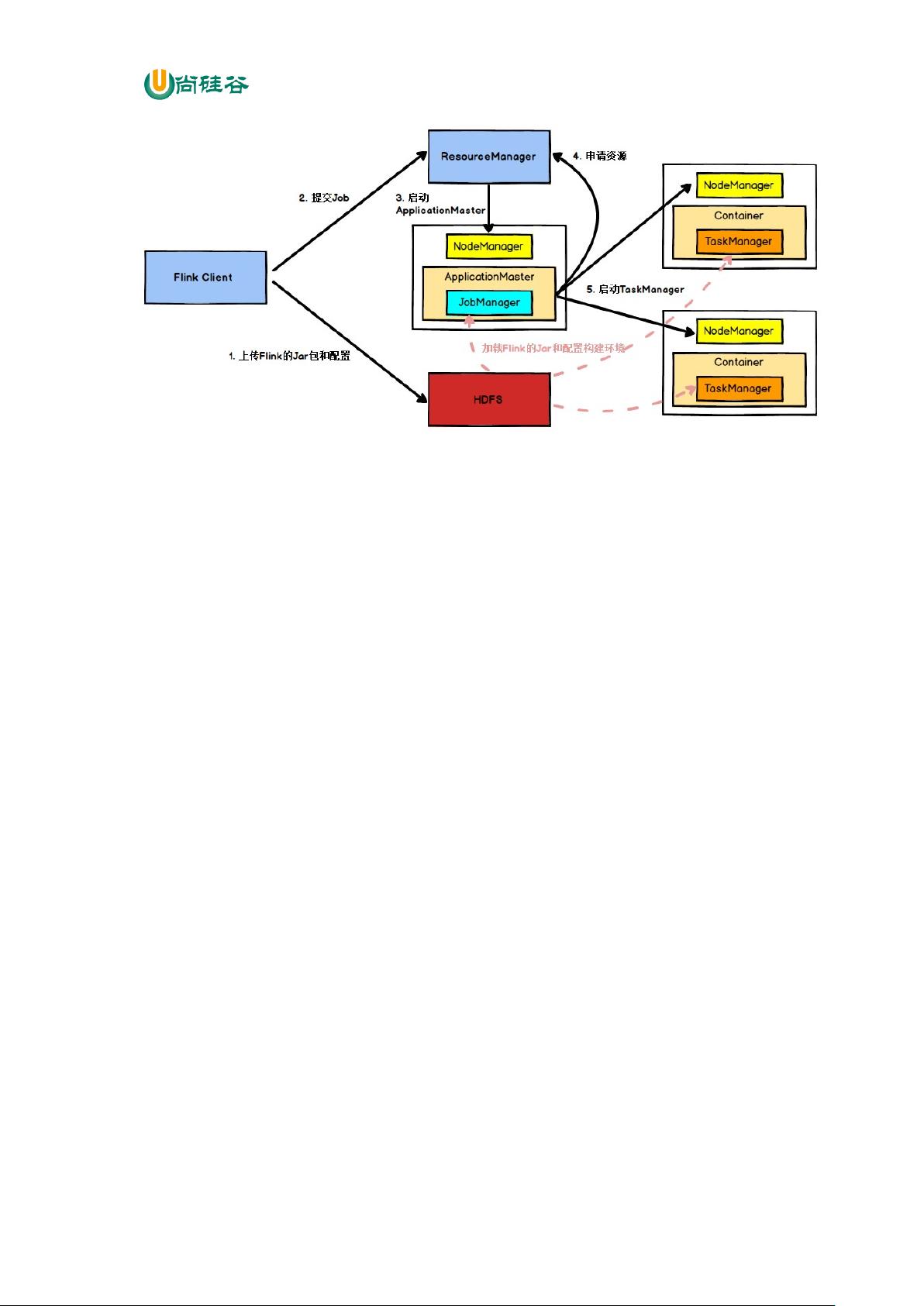
图 Yarn 模式任务提交流程
Flink 任务提交后, Client 向 HDFS 上传 Flink 的 Jar 包和配置, 之后向 Yarn
ResourceManager 提交任务, ResourceManager 分 配 Container 资 源 并 通 知 对 应 的
NodeManager 启动 ApplicationMaster, ApplicationMaster 启动后加载 Flink 的 Jar 包
和配置构建环境,然后启动 JobManager,之后 ApplicationMaster 向 ResourceManager
申 请 资 源 启 动 TaskManager , ResourceManager 分 配 Container 资 源 后 , 由
ApplicationMaster 通 知 资 源 所 在 节 点 的 NodeManager 启 动 TaskManager ,
NodeManager 加载 Flink 的 Jar 包和配置构建环境并启动 TaskManager,TaskManager
启动后向 JobManager 发送心跳包, 并等待 JobManager 向其分配任务。
剩余99页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-09-30 上传
2024-02-02 上传
2022-08-03 上传
2020-11-23 上传
2022-08-04 上传
2019-02-12 上传

AIAlchemist
- 粉丝: 893
- 资源: 304
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
