大数据Linux V3.0:从入门到VM安装详解
需积分: 0 165 浏览量
更新于2024-07-15
收藏 8.09MB DOCX 举报
本文档深入探讨了大数据技术在Linux环境中的应用,特别关注了Linux版本V3.0,主要分为两个章节:Linux入门和VM与Linux的安装。
**第1章 Linux入门**
1.1 概述:本章首先介绍了Linux的基本概念,包括其在大数据处理中的优势,如开源、稳定性和性能优化等。Linux作为大数据平台的基石,提供了丰富的工具和库,如Hadoop、Spark等,以支持大数据处理任务。
1.2 Linux和Windows区别:此处详细比较了Linux与Windows操作系统在性能、安全性、灵活性和成本上的差异。Linux以其免费、可定制和高度可扩展性在大数据环境中占据优势。
**第2章 VM与Linux的安装**
2.1 VMware安装:
- 详细步骤涵盖了VMware Workstation Pro的安装过程,包括安装向导、许可协议的理解和激活,以及软件的更新和维护。
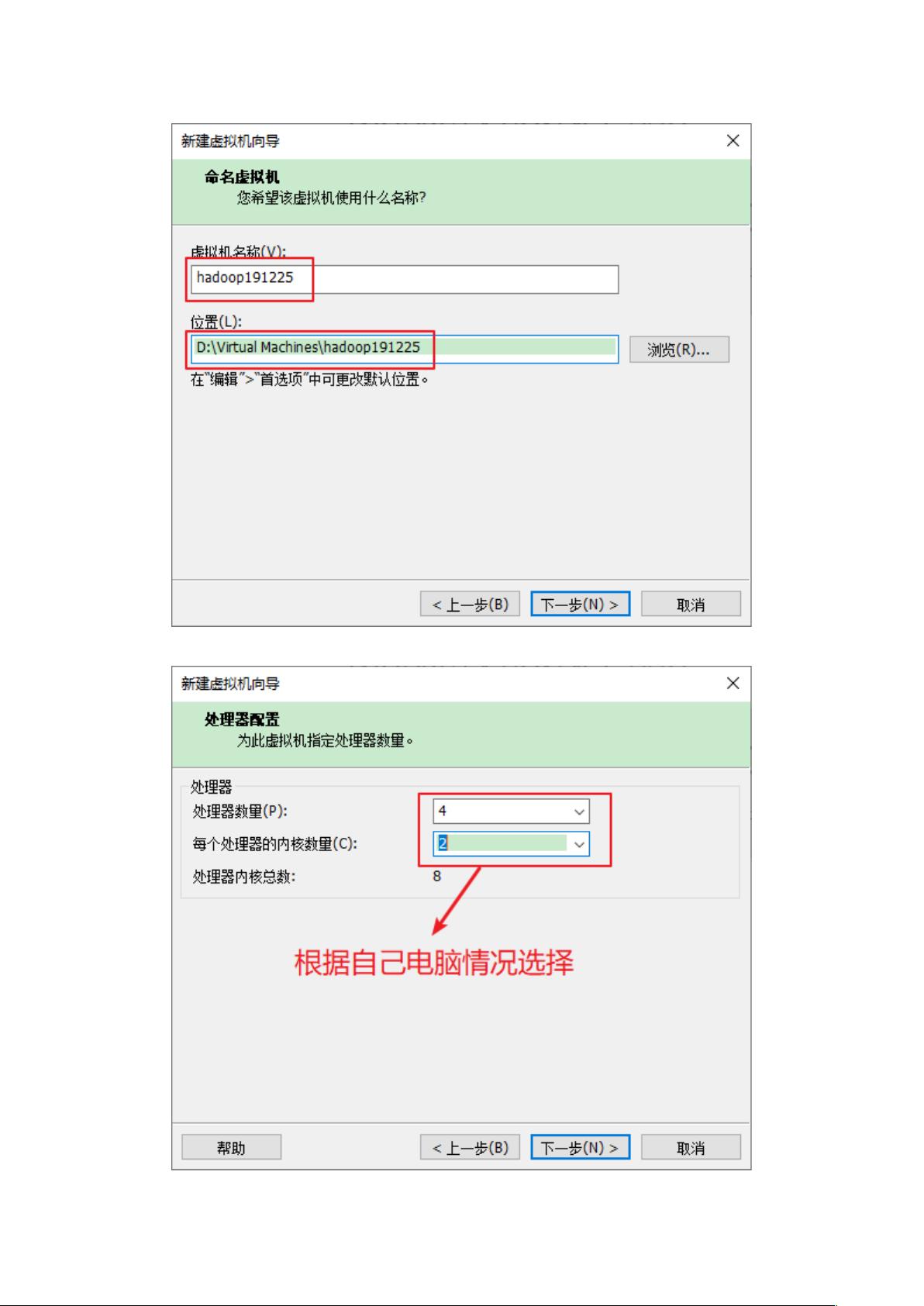
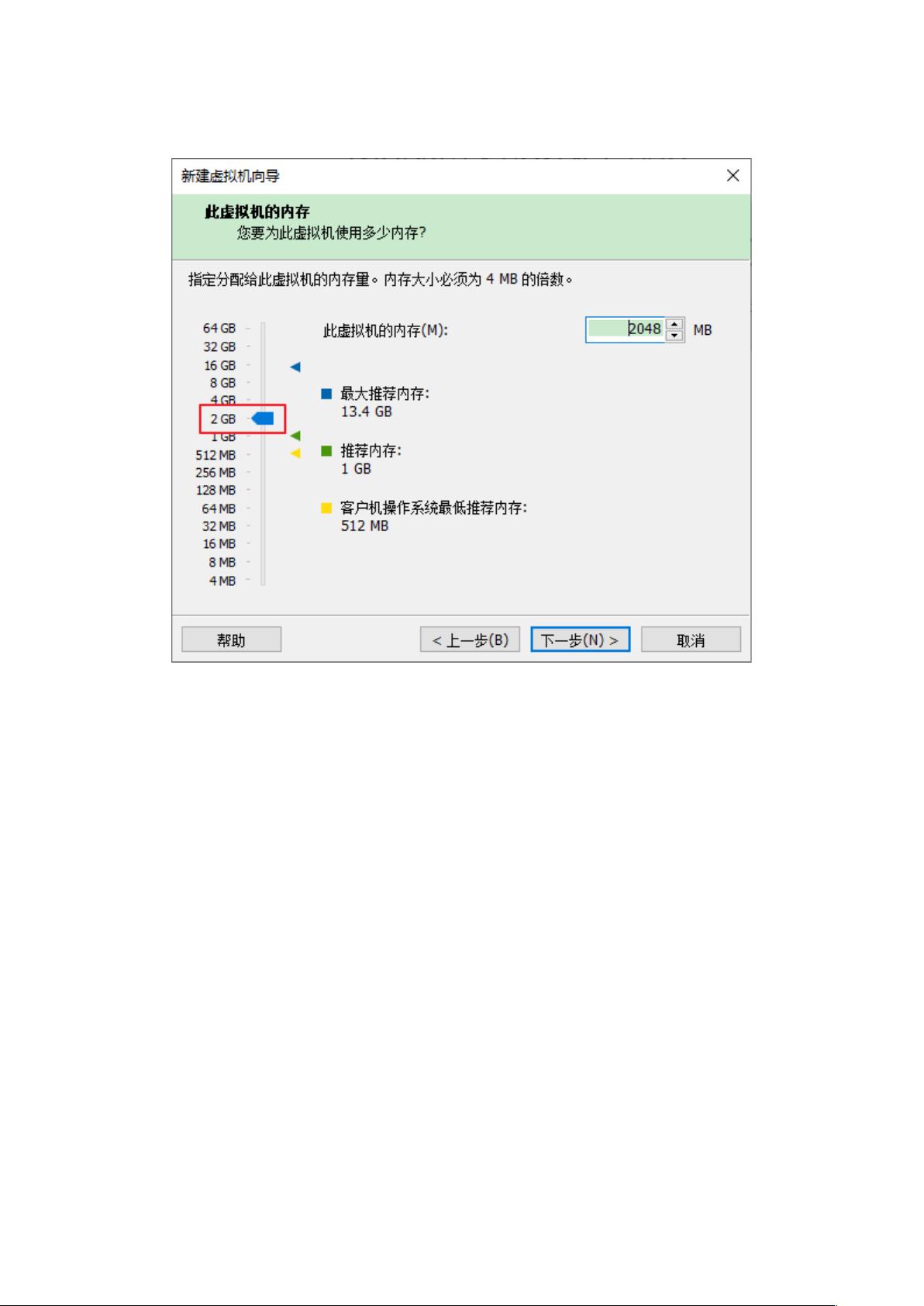
- 通过实例说明如何配置虚拟机,如设置虚拟机名、磁盘位置、处理器核心数量、内存大小、网络设置(NAT模式),以及选择合适的IO控制器和磁盘类型。
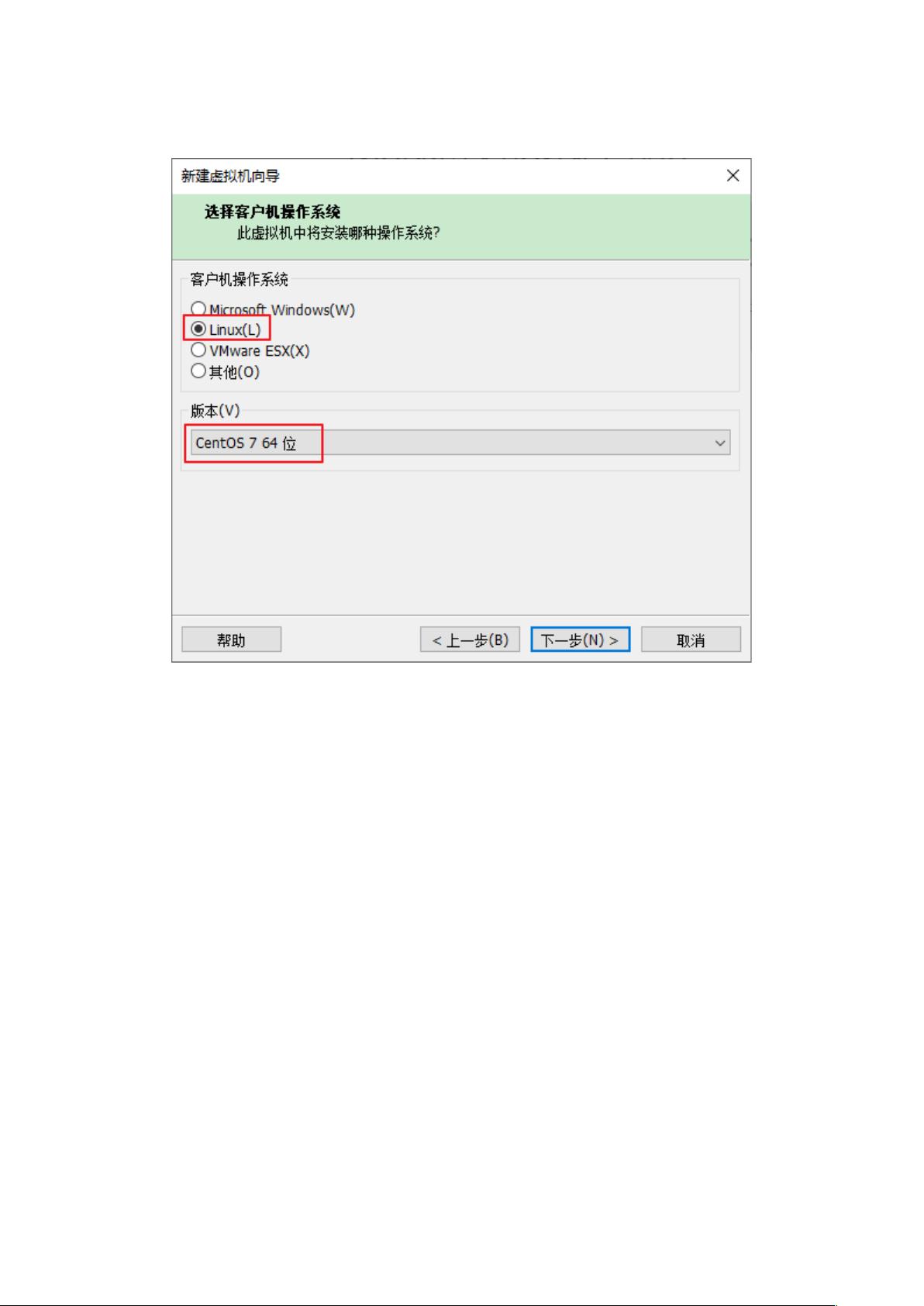
2.2 CentOS安装:
- 针对Windows 7和10系统的用户,指导如何检查BIOS虚拟化支持,然后逐步创建虚拟机,包括创建虚拟磁盘、安装CentOS 7.5.1804版本,以及选择语言和安装选项(如自动分区、选择网络等)。
- 安装过程中,用户需要设置root密码,并了解如何在安装完成后对虚拟机进行基本配置,如加载ISO镜像、启动安装,以及在安装界面进行必要的交互操作。
这份文档为学习者提供了一个全面的Linux入门指南,尤其是对于那些希望在大数据领域使用Linux的读者,它详细解释了如何安装和配置虚拟机环境,以便于理解和实践大数据技术在Linux平台上的应用。无论是初学者还是经验丰富的开发人员,都能从中找到有价值的信息。
2019-07-09 上传
2020-03-14 上传
2020-02-13 上传
2019-06-28 上传
2021-03-02 上传
2021-03-03 上传
2022-07-07 上传
2022-12-15 上传


一个写湿的程序猿
- 粉丝: 1w+
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- Solution_LinkQueue,新年快乐c语言源码,c语言
- Arrays
- 安卓奇奇动画v3.96纯净版 看动漫神器.txt打包整理.zip
- koa-routeasy:在KoaJS中创建路由的简单方法
- linux图形透明度错误shadedErrorBar.m:linux图形透明度错误shadedErrorBar.m-matlab开发
- Kusa Twitch-crx插件
- [聊天留言]工具啦新春许愿墙_nywish.rar
- qiankun-source-code:微前端框架-qiankun源码阅读
- GetOrganized:ASP.NET MVC연습
- RA8875-7,c语言0随机数源码,c语言
- 安卓多功能计算器V1.7.8 应有尽有.txt打包整理.zip
- angular-strict
- hash_formatter:Hash Formatter 是一个为代码编辑器格式化 Ruby 哈希的库
- 웹툰보기 - 바트웹툰-crx插件
- PMP-2013.zip
- HeidiSQL-12.6-64-Portable.zip
