Python爬虫:IP验证、步骤详解与数据抓取方法
需积分: 8 85 浏览量
更新于2024-07-18
收藏 7.59MB DOCX 举报
Python爬虫是一种用于自动化数据抓取和处理的技术,它通过编程实现对互联网上特定网页内容的访问和解析,从而获取所需的信息。在Python中,爬虫通常涉及以下几个核心步骤:
1. **IP检查**:
使用`telnetlib`库可以检测IP地址的可用性,通过创建Telnet对象并设置超时时间来尝试连接,判断IP是否能正常工作。
2. **爬虫基础流程**:
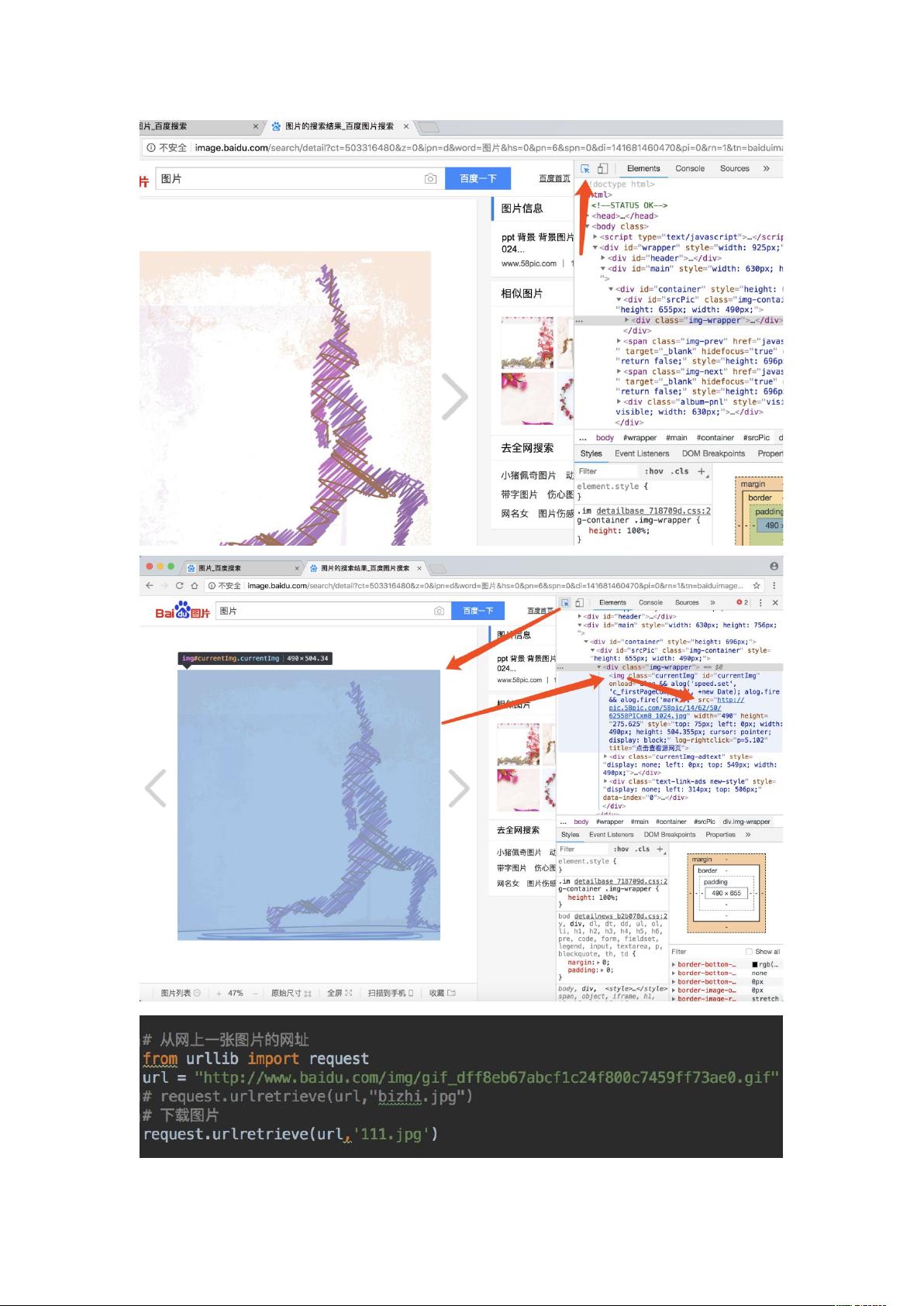
- **爬取网页信息与解码**:首先,需要访问目标网站并获取其HTML内容,这可以通过`urllib.request`、`requests`库(尤其适用于动态网页)或Scrapy框架来实现。爬虫需要模拟浏览器行为,设置User-Agent头,以及可能使用代理IP以避免被识别为机器人。
- **API接口调用**:如果目标网站提供了API,直接使用API会更高效,可以直接获取结构化的JSON数据。
3. **常用爬取方法**:
- `urllib.request`: 提供基本的HTTP请求功能,适合简单静态网页。
- `requests`: 功能强大,支持HTTP/HTTPS,特别适用于处理JSON数据。
- `Scrapy`:高级爬虫框架,支持复杂的数据提取和处理,适合大规模数据抓取。
- `Selenium`:用于模拟用户交互,适合动态网页,但性能较低,主要用于测试和反爬虫策略应对。
4. **信息提取**:
- **正则表达式**:通过模式匹配从HTML中提取数据。
- **BeautifulSoup**:强大的HTML解析库,使用CSS选择器或标签解析法提取数据。
- `Scrapy`中的CSS选择器和XPath:类似BeautifulSoup,但Scrapy内建支持。
5. **数据存储**:
- 数据可以存储为多种格式,如CSV、Excel(`pandas`库方便操作)、数据库(如MySQL、MongoDB等),具体取决于需求和后续数据分析处理的需求。
6. **网页结构分析**:
- 对于没有提供API的网站,通常需要解析HTML结构。例如,可以先查看网页源代码,寻找JSON数据的存在位置,然后使用相应的库进行解析。
针对提供的示例代码片段,它展示了如何从一个Excel文件中读取URL列表,通过`getHtml`函数爬取豆瓣详情页,并将结果存储到文件或数据库。这表明在实际应用中,爬虫会结合数据源(如Excel)、数据获取函数(如`getHtml`)和数据存储模块(如`Saving`)进行操作。
Python爬虫是一个涉及网络请求、数据解析、信息提取和数据存储的综合技术,需要根据目标网站的具体情况进行灵活选择和组合使用不同的工具和技术。同时,尊重网站的Robots协议和法律法规,合理、合法地进行爬取是非常重要的。


2434 浏览量
495 浏览量
463 浏览量
362 浏览量
126 浏览量
332 浏览量
162 浏览量
326 浏览量
217 浏览量

qq_20936501
- 粉丝: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入解析JavaScript实战源码:经典案例剖析
- 探索Ajax编程技术及应用实例
- HX711压力传感器在医疗项目中的应用解析
- 初学者实践:打造简易阅读类小程序
- 掌握JavaScript:视频教程的核心课程
- 基于OpenGL的实用教程项目指南
- VQA2.0数据集处理困难与RESNET特征提取研究
- Movielens数据集:深度分析与推荐系统应用
- Notepad++ 7.4.2 中文版安装指南
- Android全局异常处理与邮件报警系统实现
- Apache Tomcat 8.5.55版本特性与应用解析
- 技能测试项目mini-netflix: 掌握Angular CLI工具
- 优化与SEO:打造完美网站架构
- 一招清除Win7桌面快捷方式箭头
- NodeJS Windows x64环境安装指南
- AC管理软件:免费版简易维护与AP管理工具
