模糊C均值聚类算法的实现与应用
版权申诉
4 浏览量
更新于2024-07-01
收藏 362KB DOCX 举报
"模糊C均值聚类算法的C实现代码"
模糊C均值聚类算法(Fuzzy C-Means, FCM)是聚类分析中的一种,尤其在计算机科学、数据分析和机器学习领域中广泛应用。它属于模糊聚类算法,与传统的K-Means等硬聚类算法不同,模糊C均值算法允许样本点同时隶属于多个类别,这使得它在处理数据不确定性或重叠类别时更为灵活。
模糊C均值算法的核心在于计算样本点对每个类别的隶属度,这通过一个模糊度参数m来控制。隶属度函数μ(x)定义了样本x属于类别Ci的程度,其值介于0和1之间。算法的目标是最小化以下的模糊聚类代价函数:
J = ∑(∑(μi(j)^m * (xi - cj)^2))^(1/m)
其中,xi是样本点i的特征向量,cj是类别Ci的中心,μi(j)是样本i属于类别j的隶属度,m是模糊因子,对算法的结果有显著影响。
FCM算法的步骤如下:
1. 初始化:选择C个初始质心(类别中心),通常随机选取数据集中的样本点作为初始聚类中心。
2. 计算隶属度:对于每个样本点,根据其与所有类别中心的距离,利用模糊度参数m计算其对每个类别的隶属度。
3. 更新质心:根据当前的隶属度分布,重新计算每个类别的质心,公式为:cj = ∑(μi(j)^2 * xi) / ∑(μi(j)^2)。
4. 检查停止条件:如果质心的改变量小于预设阈值,或者达到最大迭代次数,算法终止;否则,返回步骤2继续迭代。
在实际应用中,选择合适的C和m至关重要。C代表聚类的数量,通常需要根据问题的具体领域知识或实验结果来设定。m的值越大,样本点所属类别的模糊性就越低,更接近硬聚类;反之,m的值越小,模糊性越高,样本点可能同时属于多个类别。通常,m取值在1.5到2之间可以得到较好的聚类效果。
在编程实现模糊C均值算法时,需要注意优化计算过程,避免不必要的计算和内存消耗,尤其是在处理大数据集时。此外,还可以采用各种策略来改善算法的性能,例如使用并行计算、启发式初始化方法或引入距离度量的调整。
模糊C均值聚类算法是一种强大的工具,用于处理具有模糊边界和不确定性数据的聚类问题。它的灵活性和对数据复杂性的适应性使其在图像分析、数据挖掘、模式识别等多个领域都有重要应用。理解和掌握FCM算法及其C语言实现,对于提升数据分析能力至关重要。
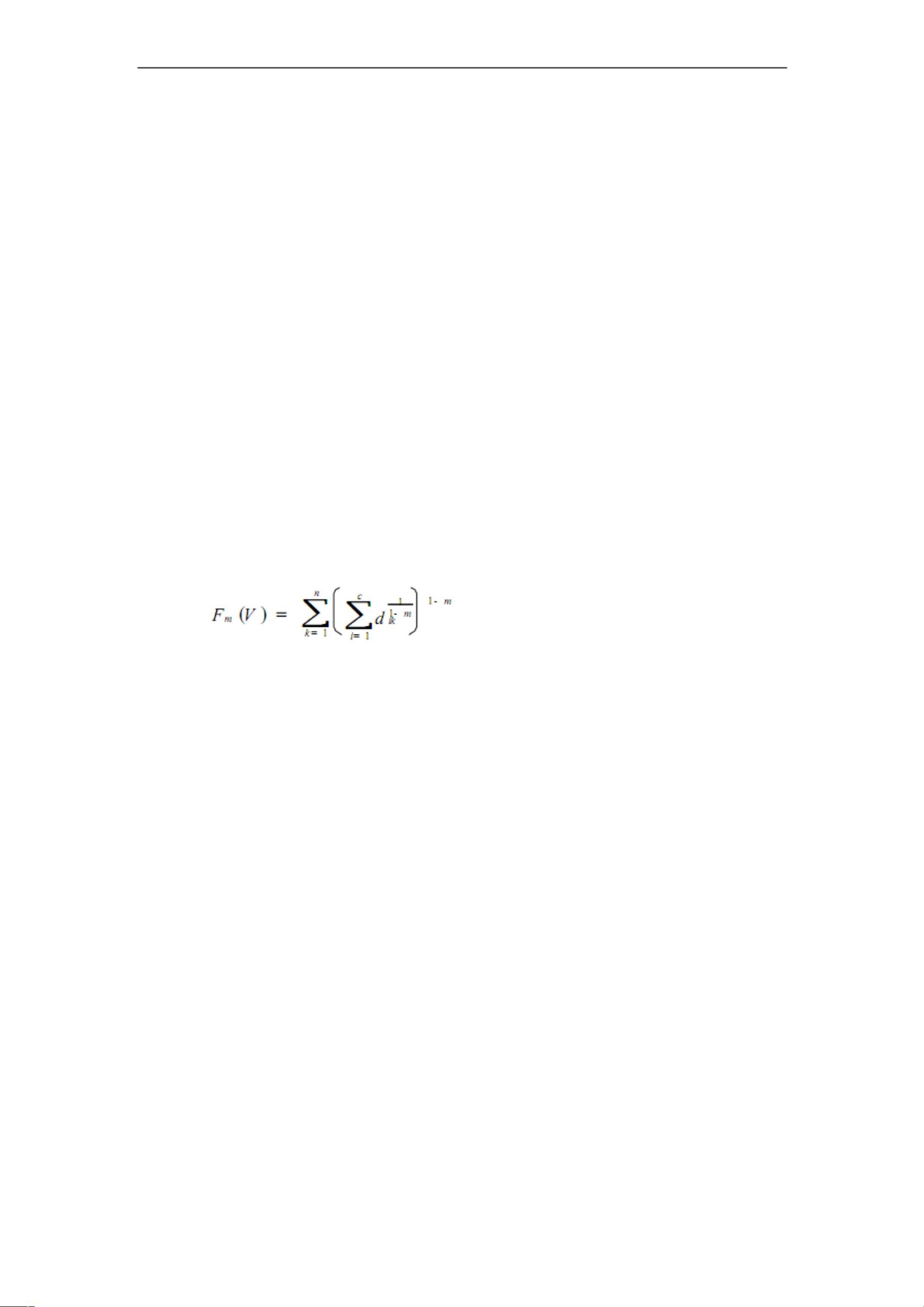
.
(1) 种群中个体的确定
聚类的关键问题是聚类中心的确定,因此可以选取聚类中心作为种
群的个体,由于共有 C 个聚类中心,而每个聚类中心是一个 S 维的实数
向量,因此每个个体的初始值是一个 c*s 维的市属向量。
(2) 编码
常用的编码方式有二进制与实数编码,由于二进制编码的方式搜索
能力最强,且交叉变异操作简单高效,因此采用二进制的编码方式,同
时防止在进行交叉操作时对优良个体造成较大的破坏,在二进制编码的
方式中采用格雷码的编码形式。
每个染色体含 c*s 个基因链,每个基因链代表一维的数据,由于原
始数据中各个属性的取值可能相差很大,因此需首先对数据进行交换以
统一基因链的长度,可以有以下两种变换方式。
1 扫描整个数据集,确定每维数据的取值范围,然后将其变换到同
一量级,在保留一定有效位的基础上取整,根据有效位的个数动态的计
算出基因链的长度。
2 对数据进行正规化处理,即将各维数据都变换到相同的区间,可
以算出此时的基因链长度为 10。
(3) 适应度函数
由于在算法中只使用了聚类中心 V,而未使用虑属矩阵 u,因此需要
对 FCM 聚 类 算 法 的 目 标 函 数 进 行 改 进 , 以 适 用 算 法 的 要 求 ,
和目标函数是等价的,由于遗传算法的
适用度一般取值极大,因此可取上式的倒数作为算法的使用度函数。
(4) 初始种群的确定
初始种群的一般个体由通过采样后运行 FCM 算法得到的结果给出,
另外的一般个体通过随机指定的方法给出,这样既保证了遗传算法在运
算之初就利用背景知识对初始群体的个体进行了优化,使算法能在一个
较好的基础上进行,又使得个体不至于过分集中在某一取值空间,保证
了种群的多样性。
(5) 遗传操作
选择操作采用保持最优的锦标赛法,锦标赛规模为 2,即每次随机取
2 个个体,比较其适应度,较大的作为父个体,并保留每代的最优个体
作为下一代,交叉方式一般采用单点交叉或多点交叉法进行,经过试验
表明单点交叉效果较好,因此采用单点交叉法,同时在交叉操作中,应
该对每维数据分开进行,以保证较大的搜索空间和结果的有效性,变异
操作采用基本位变异法。
(6) 终止条件的确定
遗传算法在以下二种情况下终止
a 最佳个体保持不变的代数达到设定的阈值
b 遗传操作以到达给定的最大世代数
算法具体步骤如下
1 确定参数,如聚类个数 样本集大小 种群规模 最大世代数 交叉概率
和变异概率等。
-.
剩余20页未读,继续阅读
2023-02-20 上传
2022-05-31 上传
2022-07-10 上传
2022-07-09 上传
2022-11-12 上传
2022-11-04 上传

apple_51426592
- 粉丝: 9841
- 资源: 9652
 我的内容管理
展开
我的内容管理
展开







最新资源
- Basic-Banking-App
- VB winsock简单实例tcp连接
- 深度学习
- simple_saver
- winformsprotector:antidecompiler 和 anti deobfuscator,源代码保护-开源
- Marble-Run-Unreal
- Issue_Tracker:问题跟踪器是一个全栈应用程序,用于管理和维护问题列表
- StreamAPI
- 参考资料-2M.02.07 U9产品介绍-销售.zip
- Accuinsight-1.0.32-py2.py3-none-any.whl.zip
- 两档AMT纯电动汽车仿真模型(CRUISE)
- hmtt:在里面
- products-api:注册产品的API
- CS6583LED电源PDF规格书.rar
- 婚礼:我们的婚礼网站
- epl-analysis:对1920赛季英格兰超级联赛足球比赛的分析
