统计模式识别:经典回顾与新进展
需积分: 13 101 浏览量
更新于2024-07-22
收藏 2.11MB PDF 举报
"这篇文章是关于统计模式识别的回顾,由著名专家Anil K. Jain等人撰写,涵盖了统计方法在模式识别中的应用、神经网络技术以及统计学习理论的最新进展。"
统计模式识别是一种广泛应用于各个领域的数据分析技术,其主要目标是进行有监督或无监督的分类任务。该领域经过近50年的发展,尽管取得了很多成就,但对于复杂图案的识别,特别是那些具有任意方向、位置和尺度变化的图案,仍然存在挑战。
统计方法在模式识别中的核心地位在于它提供了一套严谨的框架来处理数据和模型的不确定性。这些方法包括概率模型、贝叶斯推断和最大似然估计等,它们使得我们能够对未知数据分布进行建模,并基于这些模型做出预测。例如,高斯混合模型(Gaussian Mixture Models)常用于对复杂数据集进行建模,而朴素贝叶斯分类器则利用特征之间的独立性假设来进行高效分类。
近年来,随着神经网络技术的兴起,尤其是深度学习的崛起,统计模式识别领域得到了进一步的发展。深度学习模型,如卷积神经网络(CNNs)和循环神经网络(RNNs),在图像识别、语音识别和自然语言处理等领域取得了显著成果。这些模型通过大量的训练数据自动学习特征表示,减少了人工特征工程的工作量。
统计学习理论也为模式识别提供了新的视角,它关注如何从有限的训练样本中获得最优的学习算法。Vapnik-Chervonenkis(VC)维理论和结构风险最小化原则是其中的重要概念,它们指导了模型选择和防止过拟合。
设计一个有效的识别系统需要考虑多个方面:首先,定义清晰的模式类别是基础;其次,理解和适应感知环境,如噪声和光照变化;然后,选择合适的模式表示方式,这可能涉及到像素级的描述或高级语义特征;特征提取和选择是关键步骤,目的是减少冗余并突出重要信息;接下来,聚类分析有助于发现数据的内在结构;分类器设计和学习则涉及选择适合问题的模型和训练策略;训练和测试样本的选择直接影响模型性能;最后,性能评估指标如准确率、召回率和F1分数是衡量模型优劣的标准。
新兴的应用场景,如数据挖掘、网页搜索、多媒体数据检索和人脸识别,不断推动着统计模式识别的边界。尤其是在大数据时代,如何高效地处理海量信息并从中提取有价值的知识,成为统计模式识别面临的新挑战。未来的研究将更深入地探索模型的泛化能力、可解释性和计算效率,以应对更加复杂的现实世界问题。
phenomenon of overfitting in regression when there are too
many free parameters.
Overtraining has been investigated theoretically for
classifiers that minimize the apparent error rate (the error
on the training set). The classical studies by Cover [33] and
Vapnik [162] on classifier capacity and complexity provide
a good understanding of the mechanisms behind
overtraining. Complex classifiers (e.g., those having many
independent parameters) may have a large capacity, i.e.,
they are able to represent many dichotomies for a given
dataset. A frequently used measure for the capacity is the
Vapnik-Chervonenkis (VC) dimensionality [162]. These
results can also be used to prove some interesting proper-
ties, for example, the consistency of certain classifiers (see,
Devroye et al. [40], [41]). The practical use of the results on
classifier complexity was initially limited because the
proposed bounds on the required number of (training)
samples were too conservative. In the recent development
of support vector machines [162], however, these results
have proved to be quite useful. The pitfalls of over-
adaptation of estimators to the given training set are
observed in several stages of a pattern recognition system,
such as dimensionality reduction, density estimation, and
classifier design. A sound solution is to always use an
independent dataset (test set) for evaluation. In order to
avoid the necessity of having several independent test sets,
estimators are often based on rotated subsets of the data,
preserving different parts of the data for optimization and
evaluation [166]. Examples are the optimization of the
covariance estimates for the Parzen kernel [76] and
discriminant analysis [61], and the use of bootstrapping
for designing classifiers [48], and for error estimation [82].
Throughout the paper, some of the classification meth-
ods will be illustrated by simple experiments on the
following three data sets:
Dataset 1: An artificial dataset consisting of two classes
with bivariate Gaussian density with the following para-
meters:
m
1
m
1
1; 1;m
2
m
2
2; 0;
1
1
10
00:25
and
2
2
0:80
01
:
The intrinsic overlap between these two densities is
12.5 percent.
Dataset 2: Iris dataset consists of 150 four-dimensional
patterns in three classes (50 patterns each): Iris Setosa, Iris
Versicolor, and Iris Virginica.
Dataset 3: The digit dataset consists of handwritten
numerals (ª0º-ª9º) extracted from a collection of Dutch
utility maps. Two hundred patterns per class (for a total of
2,000 patterns) are available in the form of 30 48 binary
images. These characters are represented in terms of the
following six feature sets:
1. 76 Fourier coefficients of the character shapes;
2. 216 profile correlations;
3. 64 Karhunen-Loe
Á
ve coefficients;
4. 240 pixel averages in 2 3 windows;
5. 47 Zernike moments;
6. 6 morphological features.
10 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 22, NO. 1, JANUARY 2000
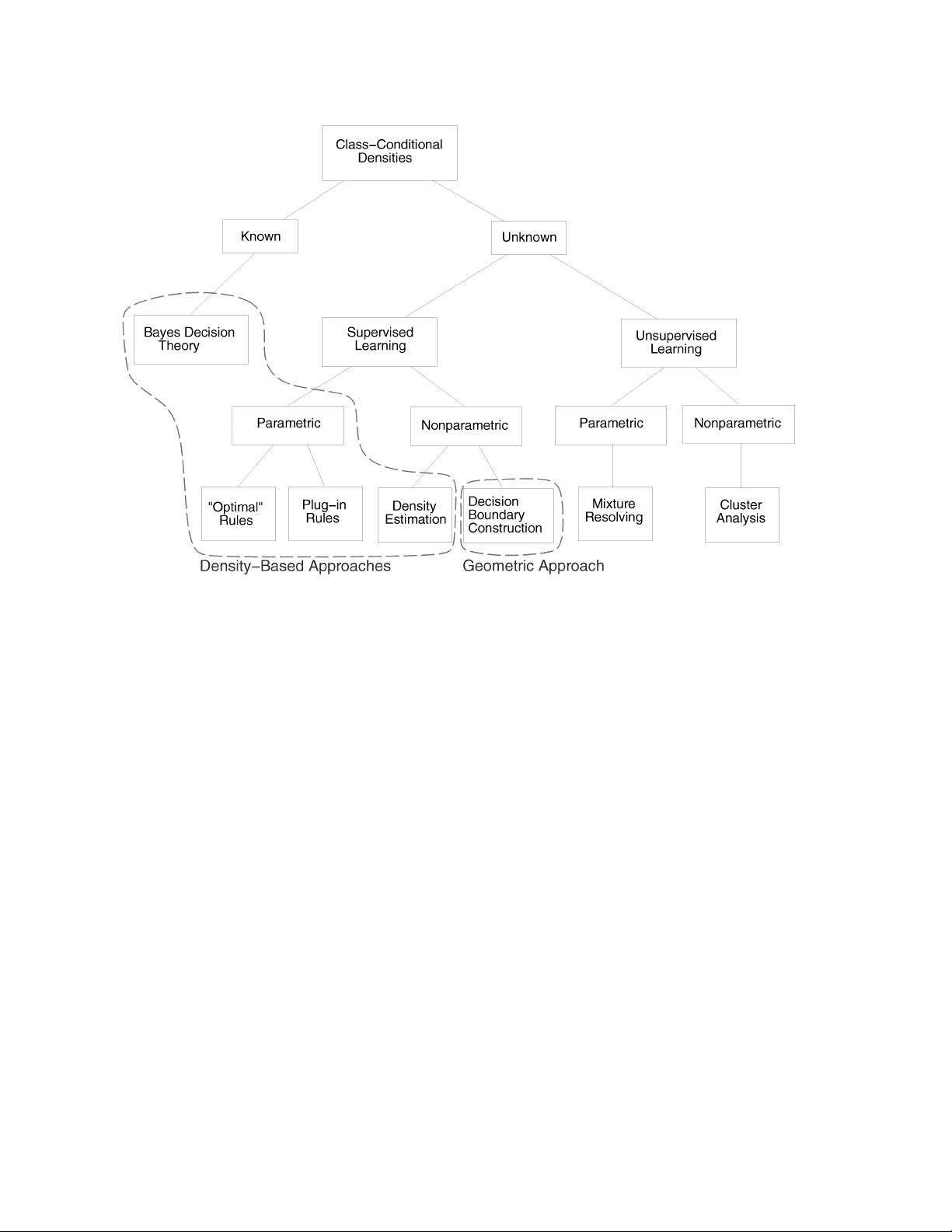
Fig. 2. Various approaches in statistical pattern recognition.
剩余33页未读,继续阅读
244 浏览量
102 浏览量
点击了解资源详情
2008-11-28 上传
107 浏览量
108 浏览量
204 浏览量
157 浏览量

一十干开
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
