H-k-means聚类算法详解与应用
"H-k-means的使用"
本文档详细介绍了分层k-means(H-k-means)聚类算法的使用手册,该算法在处理大数据集时具有较高的运行效率。H-k-means是对传统k-means算法的一种扩展,旨在通过层次结构的方式来更有效地进行聚类。
### 1. k-means算法
k-means是一种广泛应用的无监督学习算法,主要用于数据的聚类。其基本步骤如下:
1. **初始化**:随机选择k个数据点作为初始的聚类中心(或称质心)。
2. **分配**:将每个数据点分配到与其最近的聚类中心所属的类别。
3. **更新**:重新计算每个类别的质心,通常采用类别内所有数据点的均值。
4. **迭代**:重复分配和更新步骤,直到满足停止条件,如达到预设的迭代次数或聚类中心不再显著变化。
### 1.2. 分层k-means
H-k-means是对k-means算法的改进,它采用了分层的思想来逐步构建聚类结构。与标准k-means不同,H-k-means可以更好地处理复杂的聚类结构,通过递归地分割或合并集群来形成一个层次化的聚类树。
### 2. 程序菜单功能
程序提供了以下功能,以支持H-k-means的执行和结果分析:
#### 2.1. 文件加载
- **文件格式**:支持特定的文件格式用于输入数据。
- **参数选择**:用户可以设定聚类数目、迭代次数等算法参数。
- **可视化**:包括聚类树的展示和集群信息的显示。
#### 2.1.1. Clustering Tree
可视化聚类树,展示数据的层次结构,便于理解群组之间的关系。
#### 2.1.2. Cluster Information
提供关于每个集群的详细信息,如大小、形状、内部数据点的特性等。
#### 2.1.3. Working with the clustering tree
用户可以交互式地操作聚类树,例如切分或合并节点,以探索不同的聚类结构。
#### 2.2. 保存结果
用户可以保存聚类结果以便后续分析或进一步处理。
#### 2.3. Threshold calculation
程序还提供了阈值计算功能,帮助用户确定合适的聚类切割点,以获得最佳的聚类结果。
### 结论
H-k-means算法通过引入层次结构,提高了k-means在大数据集上的效率和聚类效果。这个使用手册详细阐述了如何操作程序,从文件加载到结果分析,为用户提供了完整的指南。通过深入理解和应用H-k-means,数据科学家可以更有效地对复杂数据集进行聚类分析,从而揭示隐藏的模式和结构。
© modlab, 2004
3
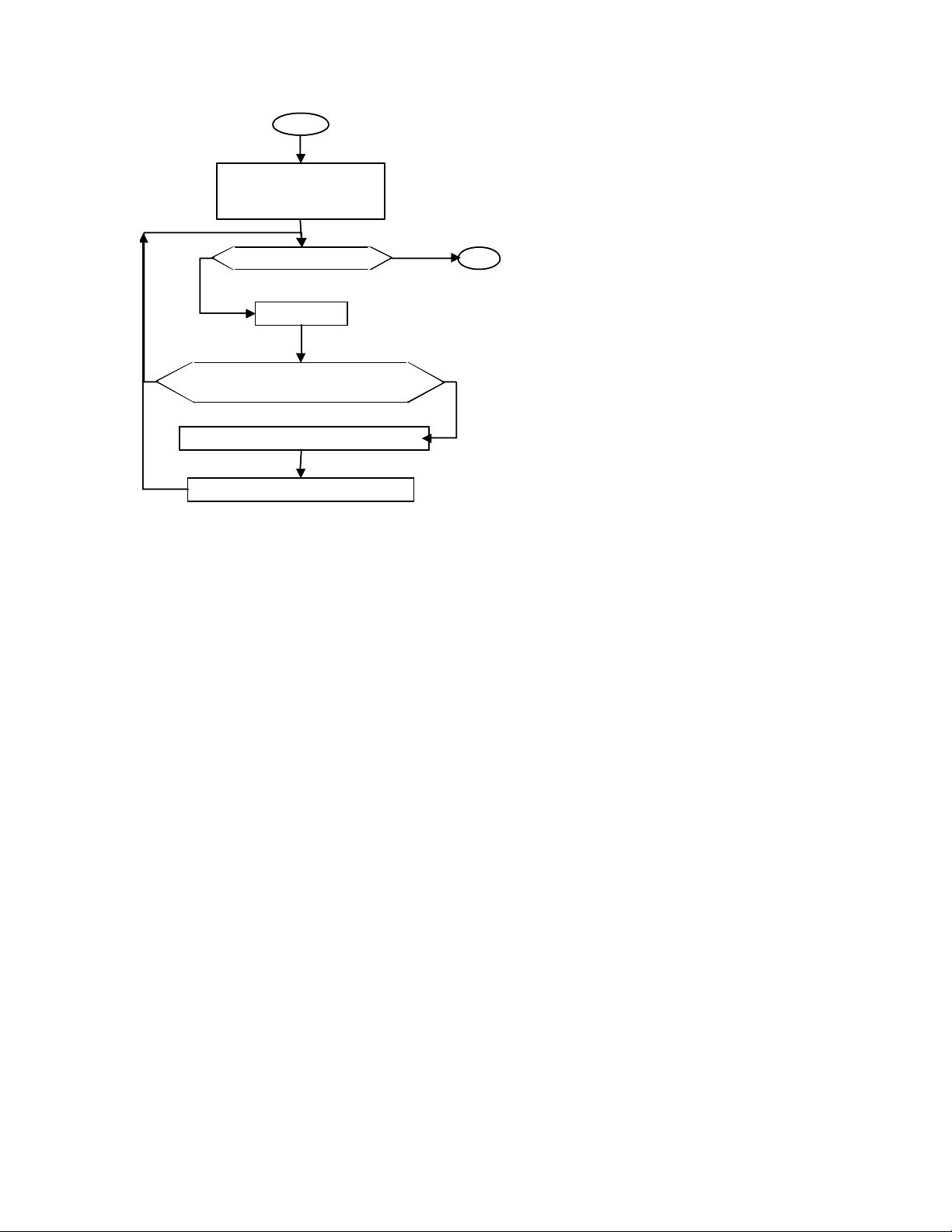
Figure 2: Flow chart for hierarchical k-means clustering
2. The Program - Menu
2.1. File loading
It is possible to load a descriptor file either with or without an adequate class file (a class
file contains the pharmacological activity description of the molecules). If a class file is
available go to File| Load descriptors file with class file in order to load the files. First a
file chooser for the descriptor file will pop up and subsequently a second one for the class
file. If no class file is available go to File| Load descriptor file without class file and
choose a descriptor file. If the chosen files exist, they will be read and an input window
for required parameters will be displayed.
2.1.1. File formats
The descriptors file has to be tab delimited, including the descriptor names in the first
line. The first column contains the identifier of the molecule (Figure 3).
Start
push the start cluster
(containing all molecules)
on the stack
pop a cluster
Is the maximum cluster distance
higher than the threshold value ?
apply k-means-clustering to the cluster
push resulted clusters on the stack
no
Exit
yes
yes
no
Is the stack empty ?
Start
push the start cluster
(containing all molecules)
on the stack
pop a cluster
Is the maximum cluster distance
higher than the threshold value ?
apply k-means-clustering to the cluster
push resulted clusters on the stack
no
Exit
yes
yes
no
Is the stack empty ?
剩余13页未读,继续阅读
2021-02-14 上传
2011-02-15 上传
2023-03-11 上传
2023-05-27 上传
2024-05-13 上传
2023-04-15 上传
2023-05-24 上传
2023-04-29 上传

icetroy
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
