Pandas数据处理:快速创建与定制绘图实例
PDF格式 | 966KB |
更新于2024-08-31
| 47 浏览量 | 举报
Pandas是Python中强大的数据处理库,其设计初衷是为了提供高效的数据结构和数据分析工具。它基于NumPy数组构建,使得许多操作能够利用NumPy或Pandas自身的扩展模块,这些模块通过Cython编写并编译成高效的C代码,从而确保了快速的数据处理性能。
本文主要介绍如何使用Pandas进行数据处理和绘图。首先,我们通过`pd.DataFrame`函数创建了一个包含五个列的DataFrame,其中:
1. "a1"和"a2"列的值是从正态分布(均值mu1和mu2,标准差sigma1和sigma2)中生成的随机数。
2. "a3"列是0到4之间的随机整数。
3. "y1"列是0到1的对数刻度均匀分布。
4. "y2"列是0到1之间的随机整数。
在绘图方面,Pandas的绘图功能非常灵活,它返回的是matplotlib的坐标轴对象,用户可以进一步定制图形。例如,我们可以创建一张图,展示"y1"列的直方图,并添加两条垂直线(水平线)来标记特定值。此外,通过`subplots`函数,我们可以同时在一张图上显示多种数据类型,如散点图、线图等,分别对应不同的列组合和坐标轴。
通过Pandas的绘图功能,数据分析师可以直观地探索数据的分布、趋势以及不同变量之间的关系,这对于数据理解和可视化具有重要意义。Pandas的强大之处在于它不仅提供了丰富的数据处理手段,还与Matplotlib等其他可视化库无缝集成,使得数据科学家能够在Python环境中高效地进行数据探索和分析工作。
pandas数据处理之绘图的实现数据处理之绘图的实现
Pandas是Python中非常常用的数据处理工具,使用起来非常方便。它建立在NumPy数组结构之上,所以它的很多操作通过NumPy或者Pandas自带的扩展模块编写,这些模块用Cython编写并编译到C,
并且在C上执行,因此也保证了处理速度。
今天我们就来体验一下它的强大之处。
1.创建数据创建数据
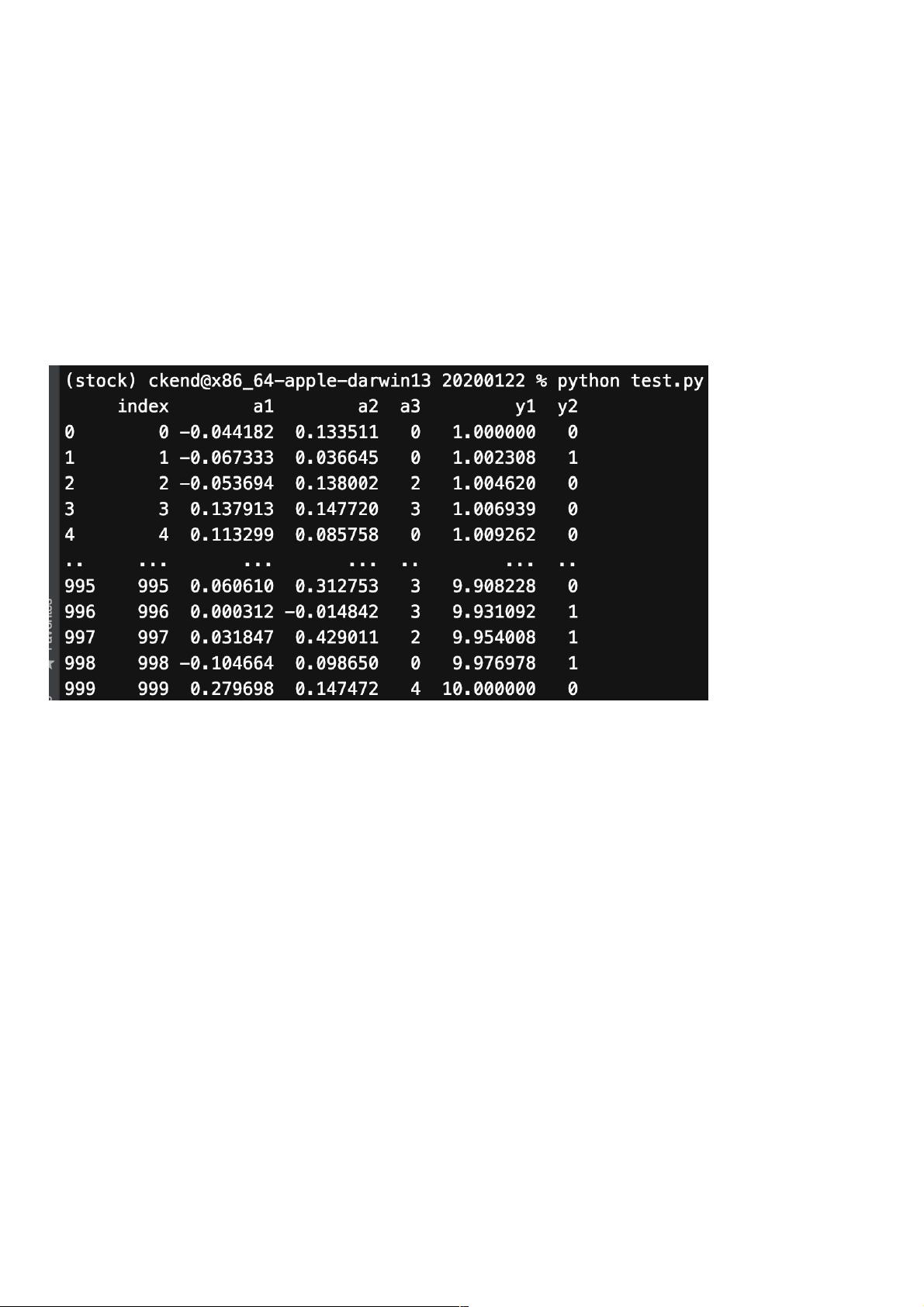
使用pandas可以很方便地进行数据创建,现在让我们创建一个5列1000行的pandas DataFrame:
mu1, sigma1 = 0, 0.1
mu2, sigma2 = 0.2, 0.2
n = 1000df = pd.DataFrame(
{
"a1": pd.np.random.normal(mu1, sigma1, n),
"a2": pd.np.random.normal(mu2, sigma2, n),
"a3": pd.np.random.randint(0, 5, n),
"y1": pd.np.logspace(0, 1, num=n),
"y2": pd.np.random.randint(0, 2, n),
}
)
a1和a2:从正态(高斯)分布中抽取的随机样本。
a3:0到4中的随机整数。
y1:从0到1的对数刻度均匀分布。
y2:0到1中的随机整数。
生成如下所示的数据:
2.绘制绘制图像图像
Pandas 绘图函数返回一个matplotlib的坐标轴(Axes),所以我们可以在上面自定义绘制我们所需要的内容。比如说画一条垂线和平行线。这将非常有利于我们:
1.绘制平均线
2.标记重点的点
import matplotlib.pyplot as plt
ax = df.y1.plot()
ax.axhline(6, color="red", linestyle="--")
ax.axvline(775, color="red", linestyle="--")
plt.show()
下载后可阅读完整内容,剩余7页未读,立即下载
相关推荐




weixin_38558186
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 心电图前端设计:集成呼吸起搏检测功能
- 移动端省市区三级联动功能实现与展示
- 建筑涂料喷刷机器人的操作指南解析
- 深入解析Android MaterialDialog开源项目
- Linux命令库详解与Shell操作指南
- dotlambda库:Racket中支持点标识符和Lambda表达式
- PLSQL与Oracle客户端使用与配置教程
- IDEA开发的图书管理系统功能详解
- Bootstrap前端模板开发快速指南
- Android平台的简易数独游戏教程
- Android ReCap API示例代码教程
- 全隔离式锂离子电池监控与保护系统设计
- 模式分类Duda课后习题Matlab程序实现与工具箱指南
- Python脚本自动获取B站直播奖励
- 新型建筑用混凝土定型模具的介绍与应用
- Odoo10公司系统邮件发送功能学习指南
